前言:本章將介紹常見八大排序包括如下直接插入排序、希爾排序、選擇排序、堆排序、冒泡排序、快排、歸并排序以及計數排序(基數排序和桶排序面試基本不涉及,本文忽略了,有興趣的讀者可以自行補充),本章內容是重點中的重點!!!鐵子們務必全部掌握!!!
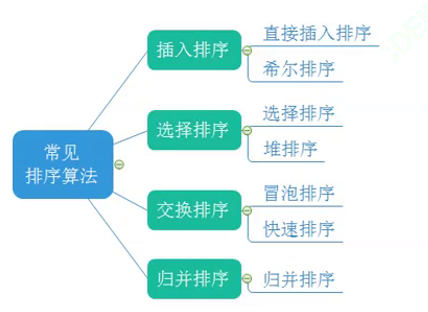
文章目錄
- 1.插入排序
- 1.1直接插入排序
- 1.2希爾排序
- 2.選擇排序
- 2.1 選擇排序(二元改進版)
- 2.2 堆排序
- 3.交換排序
- 3.1 冒泡排序
- 3.2 快速排序
- 3.2.1 Hoare
- 3.2.2 前后指標法
- 3.2.3 挖坑法
- 3.3 快速排序(非遞回)
- 4.歸并排序
- 4.1 遞回實作歸并排序
- 4.2 迭代實作歸并排序
- 5.計數排序
- 6.八大排序對比
- 6.1八大排序的性能測驗評估
- 6.2 各個排序的穩定性如何判斷?
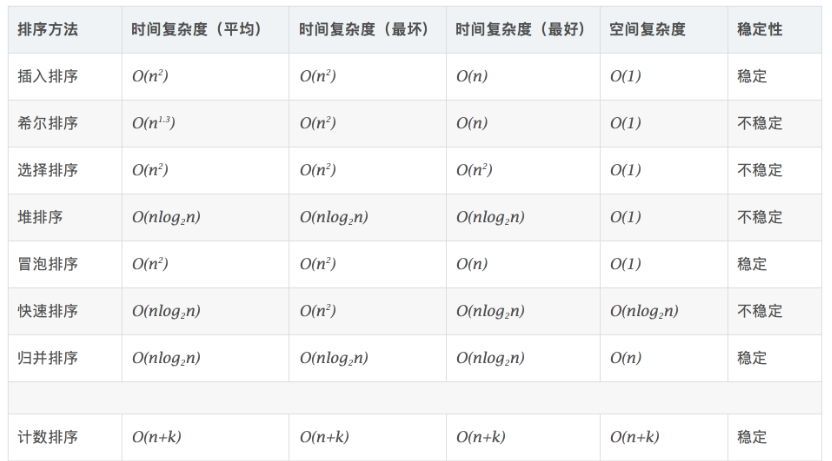
- 6.3八大排序時間/空間復雜度一覽
1.插入排序
1.1直接插入排序
基本思想
把一個數插入到有序區間,保持這個區間有序,當前第n+1個數插入到前面,前面的arr[0]到arr[n-1]已經排好序,此時用arr[n]與前面的arr[n-1], arr[n-2]…的值,進行比較找到合適的位置將arr[n]進行插入,原來位置上的元素順序后移實作了插入
代碼實作
//插入排序
void InsertSort(int* a, int n){
//控制起始條件
//注意控制好終止條件,這里的end的位置是在倒數第二個位置,所以要-1
for(int i=0; i<n-1;i++){
//單趟插入
int end = i;
int temp = a[end + 1]; //有序區間的后面
while(end>=0){ //end到-1就終止了
if(a[end]>temp){
a[end+1] = a[end];
--end;
}else{
break;
}
}
//兩種情況:第一種在最右邊,第二種在最左邊,end為-1了,始終放在end后面
a[end+1] = temp;
}
}
時間復雜度
插入排序的時間復雜度也是O(N^2),在接近有序的情況下他的時間復雜度是O(N),因為遍歷一遍就可以出結果了,空間復雜度O(1),
1.2希爾排序
希爾排序(Shell’s Sort)是插入排序的一種又稱“縮小增量排序”(Diminishing Increment Sort),是直接插入排序演算法的一種更高效的改進版本,
基本思想
希爾排序就是在處理一些極端情況比較高效,比如在上面的插入排序時如果我們在原陣列降序的情況下去排升序,那么我們交換的次數是十分多的,也可以說是插入排序的最壞的情況,這個時候聰明的先輩想到了希爾排序,將陣列分成了gap組,然后可以理解為分別處理每一個小組,gap從5 – 2 – 1的程序在降序的情況下,排在后面的數值小的數能步子更大排到前面,當gap為1的時候實際上就是進行了一次插入排序,設定gap的程序我們也稱之為預排序,
gap越小,越接近有序,gap越大,越不接近有序;
但是gap越小挪動越慢,gap越大挪動越快;
代碼實作
void ShellSort1(int* a, int n)
{
int gap = n;
while (gap>1)//別傻乎乎的加等號啊,死回圈
{
gap = gap / 3 + 1;end的范圍是[0,n-gap)
for (int i = 0; i < n - gap; i++)//并排走
{
int end = i;
int temp = a[end + gap];
while (end>=0)
{
//當前的end的值比tmp大就要往end+gap位置挪
//所以要提前保存end+gap的值
if (temp < a[end])
{
a[end + gap] = a[end];
end = end-gap;
}
else
{
break;
}
}
a[end + gap] = temp;
}
}
}
時間復雜度
O(N^1.3),一般gap建議以gap/3+1的步驟走,
2.選擇排序
簡單選擇排序思路如下動圖所示,就是只針對頭部的一個數進行對比,代碼實作大家可以自己敲敲!
2.1 選擇排序(二元改進版)
基本思想
優化的選擇排序,每次可以選擇一個最大的和一個最小的,然后把他們放在合適的位置,即最小的放在第一個位置,最大的放在最后一個位置,
然后再去選擇次小的和次大的,依次這樣進行,直到區間只剩一個值或沒有,
代碼實作
void SelectSort(int* a, int n)
{
assert(a);
int begin = 0, end = n - 1;
while (begin < end)
{
int min = begin, max = begin;
for (int i = begin; i <= end; i++)//注意起點是begin
{
if (a[i] >= a[max])
max = i;
if (a[i] < a[min])
min = i;
}
//最小的放在
Swap(&a[begin], &a[min]);
//如果最大的位置在begin位置
//說明min是和最大的交換位置
//這個時候max的位置就發生了變換
//max變到了min的位置
//所以要更新max的位置
if (begin == max)
max = min;
Swap(&a[end], &a[max]);
++begin;
--end;
}
}
時間復雜度
O(N^2),最壞的排序
2.2 堆排序
堆排之前文章詳細介紹過,具體細節歡迎點擊查閱

基本思想
細節去查閱之前的文章,現在就強調一點:排升序要建大堆,排降序建小堆
這里以升序為例:先建堆,排升序建大堆,選出最大的數將其放到最后面,然后滿足大小堆后即可做向下調整動作,
代碼實作
//堆排序
void AdjustDown(int* a, int n, int parent){
int child = parent*2 + 1;
while(child < n){
if(child+1<n && a[child+1] > a[child]){
++child;
}
if(a[child]>a[parent]){
Swap(&a[child], &a[parent]);
parent = child;
child = parent*2+1;
}else{
break;
}
}
}
void HeapSort(int* a, int n){
//排升序建大堆 O(N)
for(int i=(n-1-1)/2; i>=0; i--){
AdjustDown(a, n, i);
}
//O(N*logN)
int end = n - 1;
while(end > 0){
Swap(&a[0], &a[end]);
AdjustDown(a, end, 0); //是不是妙不可言hhh!
end--;
}
}
記錄下寫堆排時犯的錯誤(讀者可以跳過,這是留給作者復習自用的):

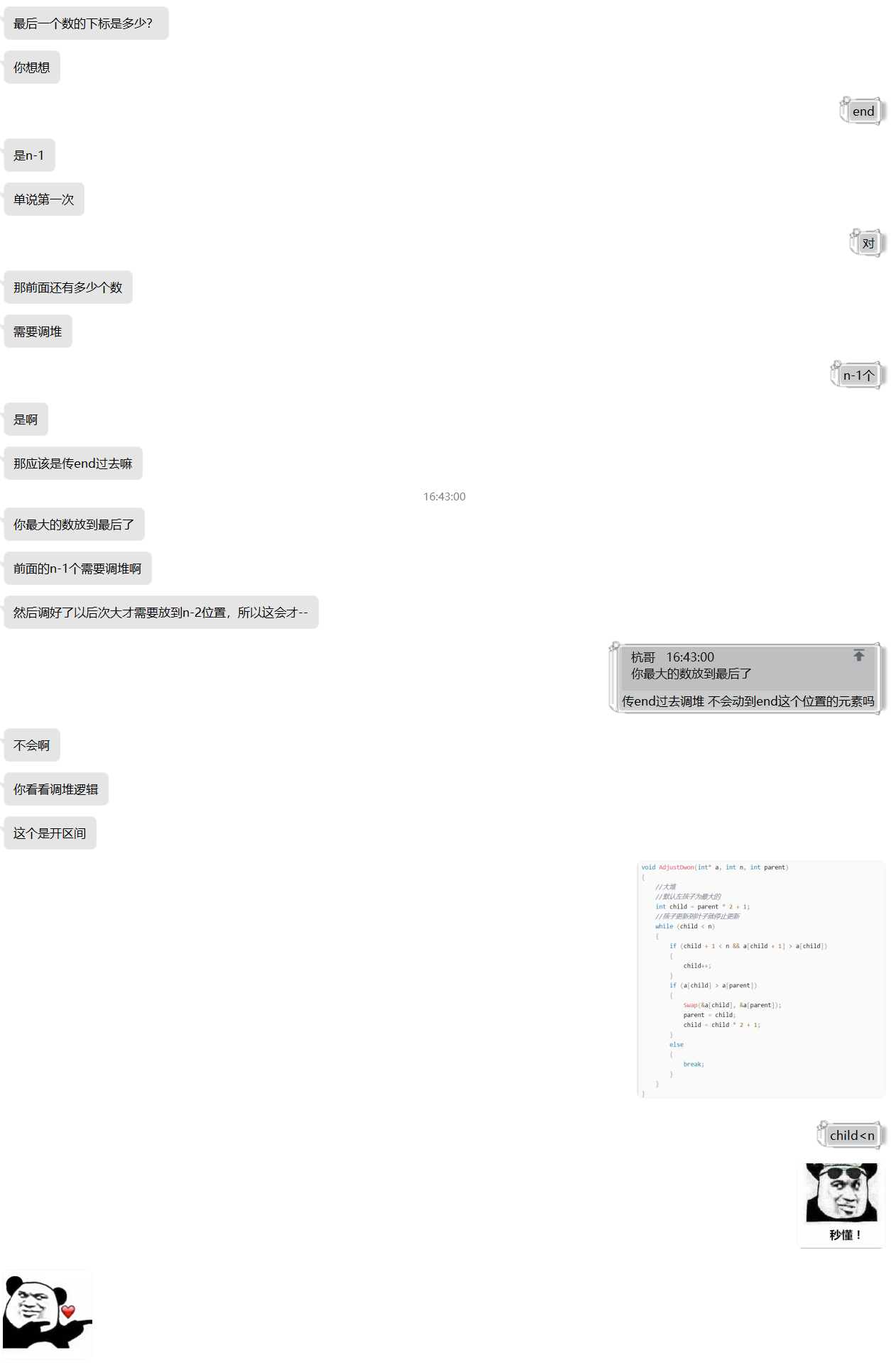
邊界問題,畫圖畫圖,冷靜分析!!!
時間復雜度
時間復雜度是O(N*logN),空間復雜度O(1)
3.交換排序
3.1 冒泡排序
基本思想
以升序為例,每一趟的冒泡排序都是把一個最大的數放到最后面,如果 a[i-1]>a[i],我們將i-1,i的值進行交換,依次回圈反復,
代碼實作
void BubbleSort(int* a, int n){
for(int j=0; j<n; j++){
int flag = 0;
for(int i=1; i<n-j; ++i){
if(a[i] < a[i-1] ){
Swap(&a[i], &a[i-1]);
flag = 1;
}
}
if(flag == 0){
break;
}
}
}
時間復雜度
O(N^2)
3.2 快速排序
3.2.1 Hoare
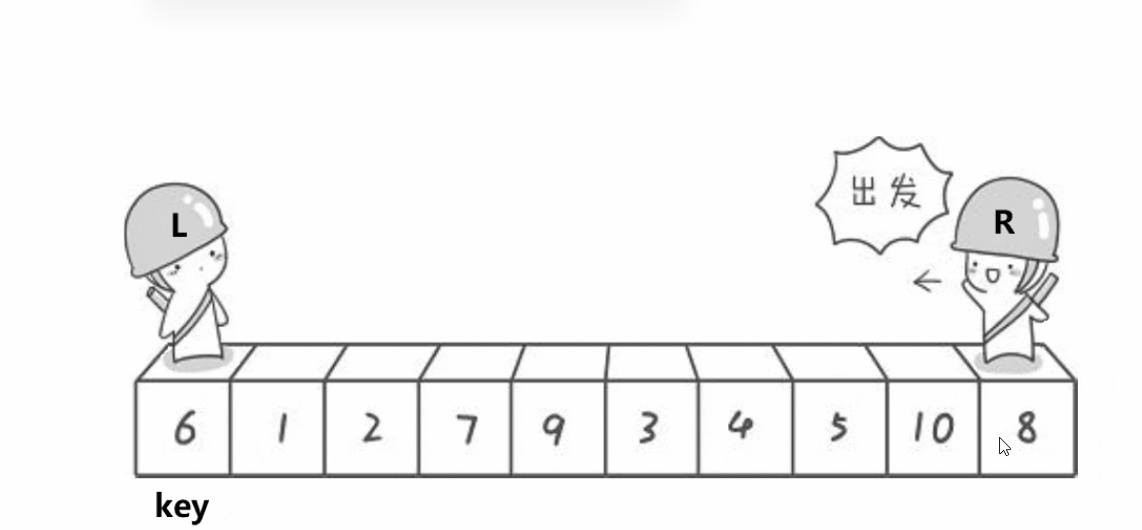
基本思想
選一個關鍵key,一般都是選擇頭,
單趟:key放在他正確的位置上,key的左邊值比key小,key右邊值比key大(這是key一趟下來排完后最終要放的位置)
單趟拍完,再想辦法讓左邊區間有序,key的右邊區間有序
那么還有優化解決方案:
第一種是取隨機值做下標
第二種是獲取這三個數中不是最大,也不是最小的那個值的下標,這種情況下不會有最壞情況,因為有三陣列取中
代碼實作
三數取中(為了優化)
//三數取中
int MidIndex(int* a, int left, int right)
{
int mid = left + (right - left) / 2;
if (a[left] < a[mid])
{
if (a[mid] < a[right])
{
return mid;
}
else if (a[left] < a[right])
{
return right;
}
else
{
return left;
}
}
else //a[left] > a[mid]
{
if (a[mid] > a[right])
{
return mid;
}
else if (a[left] < a[right])
{
return left;
}
else
{
return right;
}
}
}
void Swap(int* a, int* b)
{
int tmp = *a;
*a = *b;
*b = tmp;
}
//不妨思考一下我們進行“三數取中”的意義是什么?
單趟排序:
//一個單趟進行的排序操作的時間復雜度是多少?思考下一次完整的快排需要進行多少趟這樣的單趟排序?
int PartSort1(int* a, int left, int right)
{
int midi = MidIndex(a, left, right);
Swap(&a[left], &a[midi]);
//最左邊的做key為例
int key = left;
while (left<right)
{
//因為我們是最左邊的取key,所以必須是右邊先走找比key小的,思考下為什么?
//右邊先走
while (left < right && a[right] >= a[key])
{
--right;
}
//然后左邊走
while (left < right && a[left] < a[key])
{
++left;
}
Swap(&a[left], &a[right]);
}
Swap(&a[left], &a[key]);//此時left已經和right相遇,一樣的
return left;
}
全趟排序(遞回):
void QuickSort(int* a, int left, int right)
{
//當區間分割到只剩一個或者沒有的時候就回傳
if (left >= right)
return;
//確定一個位置,劃磁區間遞回
//分為[left,key-1] key [key+1,right]
//int key = PartSort1(a, left, right);
int key = PartSort2(a, left, right);
QuickSort(a, left, key - 1);
QuickSort(a, key + 1, right);
}
第一個問題:不妨思考一下我們進行“三數取中”的意義是什么?
如果我們不進行“三數取中”,快排如果遇見最壞的情況——有序,時間復雜度將會變成O(N^2),如果加了“三數取中”,這一最壞情況將會不復存在(后邊倆種單趟排序同理),當然了,實際面試程序當中時間不夠沒必要再來寫一個“三數取中”,面試爭分奪秒啦!
第二個問題:一個單趟進行的排序操作的時間復雜度是多少?思考下一次完整的快排需要進行多少趟這樣的單趟排序?
一個單趟的時間復雜度是O(N),一個完整的快排需要O(logN)趟這樣的單趟排序,
第三個問題:為什么key選擇最左邊的值,就要先讓右邊的數先走先去找小?
為了確保最后相遇時的a[left]<a[key],只要讓右邊的數先走,最后停下來時無論是“左邊遇到右邊”還是“右邊遇到左邊”,都滿足a[left]<a[key],
時間復雜度
一整個快排:O(N*logN)
3.2.2 前后指標法
基本思想
1.cur往前走,找到比key小的資料
2.找到比key小的資料以后,停下來,++prev
3.交換prev和cur指向位置的值
直到cur到達最右邊的位置結束!
cur還沒遇到比key大的資料之前,prev緊跟著cur,cur遇到比key大的值以后,prev和cur之間間隔著一段比key大的資料,
代碼實作
int PartSort2(int* a, int left, int right)
{
int midi = MidIndex(a, left, right);
Swap(&a[midi], &a[left]);
//這里key選取最左邊的元素為例
int key = left;
int prev = left, cur = prev + 1;
while (cur<=right)
{
if (a[cur] < a[key] && ++prev != cur)//防止自己與自己交換
{
Swap(&a[cur], &a[prev]);
}
cur++;
}
//cur走到末尾啦,交換一下,
Swap(&a[prev], &a[key]);//這里可以保證交換之前a[prev]一定小于a[key],思考下為啥?
return prev;
}
答案:跳出while回圈的a[prev],在跳出回圈之前剛與a[cur]交換過,而a[prev]與a[cur]交換的條件就是a[cur]小于a[key],所以可以保證交換跳出while回圈后發生最后一次交換之前a[prev]一定小于a[key],
全趟排序(遞回):
void QuickSort(int* a, int left, int right)
{
//當區間分割到只剩一個或者沒有的時候就回傳
if (left >= right)
return;
//確定一個位置,劃磁區間遞回
//分為[left,key-1] key [key+1,right]
//int key = PartSort1(a, left, right);
int key = PartSort2(a, left, right);
QuickSort(a, left, key - 1);
QuickSort(a, key + 1, right);
}
時間復雜度
一整個快排:O(N*logN)
3.2.3 挖坑法

基本思想
挖坑法可以選擇在0索引處挖坑(即把數拿走保存),然后從右邊找一個小的填坑,再從左邊找一個大的埋住右邊的坑,以此反復回圈,直到left與right相遇,最后把key放入相遇點(最后一個坑位)即可,
代碼實作
int PartSort3(int* a, int left, int right)
{
int midi = MidIndex(a, left, right);
Swap(&a[midi], &a[left]);
//這里key取最左邊的數,讓右邊的先開始走找小
int hole = left;
int key = a[left];
while (left < right)
{
//先找右邊比key小的,填到左邊的坑里面去
while (left < right && a[right] >= key)
{
right--;
}
a[hole] = a[right];
hole = right;
//再找左邊比key大的,找到就交換坑位
while (left<right&&a[left]<key)
{
left++;
}
a[hole] = a[left];
hole = left;
}
a[left] = key;//最后把key放到相遇點
return left;
}
全趟排序(遞回):
void QuickSort(int* a, int left, int right)
{
//當區間分割到只剩一個或者沒有的時候就回傳
if (left >= right)
return;
//確定一個位置,劃磁區間遞回
//分為[left,key-1] key [key+1,right]
//int key = PartSort1(a, left, right);
int key = PartSort3(a, left, right);
QuickSort(a, left, key - 1);
QuickSort(a, key + 1, right);
}
時間復雜度
一整個快排:O(N*logN)
3.3 快速排序(非遞回)
我們前面實作快排是采用遞回的方式,但是遞回本身是有“原罪”的,這個“原罪”在于如下:
1.當遞回深度過大的時候,遞回程式本身可能沒用錯誤,但是編譯之后會報錯——堆疊溢位(stack overflow),
2.性能問題(某些書上提到的,但是現在編譯優化得很好,這個問題不大),
任何一個遞回程式,我們要把他改成非遞回程式有如下倆種方式:
1.回圈(但是有的東西是不好改成回圈的,比如二叉樹的遍歷、快排等)
2.“堆疊”模擬(這個“堆疊”是資料結構中的“堆疊”,不是系統內部那個“堆疊”,一般用到堆疊難度都是略大的)
這里的快排改非遞回用的就是“堆疊”模擬,
基本思想
非遞回的在這里借助堆疊,依次把我們需要單趟排的區間入堆疊,依次取堆疊里面的區間出來單趟排,再把需要處理的子區間入堆疊,以此回圈,直到堆疊為空的時候即處理完畢,
非遞回代碼實作
void QuickSortNonR(int* a, int left, int right)
{
//非遞回,我們可以處理當前的區間,再處理磁區間
//先入右,后入左,就先拿到左
Stack s;
StackInit(&s);
StackPush(&s,right);
StackPush(&s,left);
while (!StackEmpty(&s))
{
left = StackTop(&s);
StackPop(&s);
right = StackTop(&s);
StackPop(&s);
//處理當前區間 [left,right]
int key = PartSort3(a, left, right);
//劃分左右區間,分別入堆疊
//[left,key-1] key [key+1,right]
//先入右區間,區間有兩個值才需要處理
if (key + 1 < right)
{
StackPush(&s, right);
StackPush(&s, key + 1);
}
//再入左區間
if (left < key - 1)
{
StackPush(&s, key - 1);
StackPush(&s, left);
}
}
}
時間復雜度
最優的時間復雜度是O(nlogn),最差的空間O(n^2) ,因為進行了三數取中,不存在最差情況,
4.歸并排序
4.1 遞回實作歸并排序
基本思想
我們可以把一個陣列分成兩半,對于每一個陣列當他們是有序的就可以進行一次合并操作,對于他們的兩個區間進行遞回,一直遞回下去劃磁區間,當區間只有一個值的時候我們就可以進行合并回傳上一層,讓上一層合并再回傳,
代碼實作
void _MergeSort(int* a, int left, int right,int* newArr)
{
if (left >= right)
return;
int mid = left + (right - left) / 2;
//[left,mid][mid+1,right]
_MergeSort(a, left, mid,newArr);
_MergeSort(a, mid + 1, right,newArr);
//走到這里已經是左右區間有序
//將兩個區間合并成一個區間
//拷貝到newArr當中,排完再放回
int index = left;
int begin1 = left, end1 = mid;
int begin2 = mid+1,end2 = right;
while (begin1 <= end1 && begin2 <= end2)
{
if (a[begin1] < a[begin2])
{
newArr[index++] = a[begin1++];
}
else
{
newArr[index++] = a[begin2++];
}
}
//走到這里一定有一邊沒有走完
while (begin1 <= end1)
{
newArr[index++] = a[begin1++];
}
while (begin2 <= end2)
{
newArr[index++] = a[begin2++];
}
//拷貝回元素組 letf -- right 的位置
for (int i = left; i <= right; ++i)
{
a[i] = newArr[i];
}
}
void MergeSort(int* a, int n)
{
//歸并排序就是在左右區間有序重新組合起來
//所以保證左右區間都是有序,遍歷到葉子就可以
int* newArr = (int*)malloc(sizeof(int) * n);
int left = 0;
int right = n - 1;
_MergeSort(a, left, right,newArr);
}
時間復雜度
O(NlogN),可以看出他的遞回程序中每次都將一組平均分,分完后高度大概是logN,空間復雜度O(N)
4.2 迭代實作歸并排序
跟快排類似,遞回會帶給快排的問題同樣會給歸并排序帶來,所以嘗試用非遞回方式!
任何一個遞回程式,我們要把他改成非遞回程式有如下倆種方式:
1.回圈(但是有的東西是不好改成回圈的,比如二叉樹的遍歷、快排等)
2.“堆疊”模擬(這個“堆疊”是資料結構中的“堆疊”,不是系統內部那個“堆疊”,一般用到堆疊難度都是略大的)
這里歸并排序非遞回實作就是采用“回圈”,
基本思想
迭代實作可以用回圈來實作,這里我們根據遞回思想其實很容易知道,我們控制迭代從最小的子問題出發,保存最小子問題的值,然后提供給后面用,這其實就是一個動態規劃的思想,我們可以從利用子問題的解,解決 “大BOSS” ,
代碼實作
void MergeSortNonR(int* a, int n)
{
//int a[] = { 8,4,5,7,1,3,6,2,7,8 };
int* newArr=(int*)malloc(sizeof(int)*n) ;
int groupNum = 1;
int left;
int right;
//動態規劃的思想,當我們把最小的問題切割
while(groupNum<n/2+1)
{
for (int i = 0; i < n; i += (2*groupNum))
{
//分成兩組[begin1,end1][begin2,end2]
int begin1 = i;
int end1 = i + groupNum - 1;
int begin2 = i + groupNum;
int end2 = i + 2 * groupNum - 1;
//處理兩種情況,當end1已經越界,說明處理end1的邊界
if (end1 >= n)
{
end1 = n - 1;
}
//當end1越界,理所當然的begin2和end2都越界了
//這里可能的[begin1,end1]區間,也需要拷貝到臨時陣列,再拷回原陣列
if (begin2 >= n)
{
//表示右區間不存在
begin2 = n;
end2 = n-1;
}
else if (begin2 < n && end2 >= n)
{
end2 = n - 1;
}
left = begin1;
right = end2;
//index用于放到臨時陣列newArr當中的
int index = begin1;
while (begin1 <= end1 && begin2 <= end2)
{
if (a[begin1] < a[begin2])
{
newArr[index++] = a[begin1++];
}
else
{
newArr[index++] = a[begin2++];
}
}
//走到這里一定有一邊沒有走完
while (begin1 <= end1)
{
newArr[index++] = a[begin1++];
}
while (begin2 <= end2)
{
newArr[index++] = a[begin2++];
}
//拷貝回元素組 letf -- right 的位置
for (int x = left; x <= right; ++x)
{
a[x] = newArr[x];
}
}
groupNum*=2;
}
free(newArr);
newArr = NULL;
}
時間復雜度
O(NlogN)
5.計數排序
基本思想
1.統計原陣列中每個值出現的次數
2.排序:遍歷Count陣列,對應位置的值出現多少次就往原陣列寫幾個這個值
當然,在對于資料比較大的時候我們可以通過相對映射,讓(該值-min)后的陣列加一,最后還原回去即可,
代碼實作
void CountSort(int* a, int n)
{
//int a[] = { 31,24,25,16,1,0,79 };
//遍歷一遍找到最大和最小,然后開大一的陣列
int max = a[0];
int min = a[0];
for (int i = 1; i < n; ++i)
{
if (max < a[i])
{
max = a[i];
}
if (min > a[i])
{
min = a[i];
}
}
int size = max - min + 1;
int* tmp = (int*)calloc(size,sizeof(int));
//將a遍歷映射到tmp當中,a的長度是n,tmp的長度只有size
for (int i = 0; i < n; ++i)
{
tmp[a[i] - min]++;//tmp[i]存放的是這個值出現的次數
}
//在按照tmp當中的存放放回去
int index = 0;
for (int i = 0; i < size; ++i)
{
while (tmp[i] > 0)
{
//這里應該是下標+映射的
a[index++] = i + min;
--tmp[i];
}
}
}
時間復雜度
計數排序的時間復雜度是O(N),空間復雜度是O(max-min),就是我們開的陣列是這個區間的范圍差,
6.八大排序對比
6.1八大排序的性能測驗評估
// 測驗排序的性能對比
void TestOP()
{
srand(time(0));
const int N = 10000;
int* a1 = (int*)malloc(sizeof(int)*N);
int* a2 = (int*)malloc(sizeof(int)*N);
int* a3 = (int*)malloc(sizeof(int)*N);
int* a4 = (int*)malloc(sizeof(int)*N);
int* a5 = (int*)malloc(sizeof(int)*N);
int* a6 = (int*)malloc(sizeof(int)*N);
int* a7 = (int*)malloc(sizeof(int)*N);
for (int i = 0; i < N; ++i)
{
a1[i] = rand();
a2[i] = a1[i];
a3[i] = a1[i];
a4[i] = a1[i];
a5[i] = a1[i];
a6[i] = a1[i];
a7[i] = a1[i];
}
int begin1 = clock();
InsertSort(a1, N);
int end1 = clock();
int begin2 = clock();
ShellSort(a2, N);
int end2 = clock();
int begin3 = clock();
SelectSort(a3, N);
int end3 = clock();
int begin4 = clock();
HeapSort(a4, N);
int end4 = clock();
int begin5 = clock();
QuickSort(a4, 0, N-1);
int end5 = clock();
int begin6 = clock();
MergeSort(a6, N);
int end6 = clock();
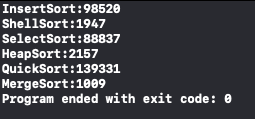
printf("InsertSort:%d\n", end1 - begin1);
printf("ShellSort:%d\n", end2 - begin2);
printf("SelectSort:%d\n", end3 - begin3);
printf("HeapSort:%d\n", end4 - begin4);
printf("QuickSort:%d\n", end5 - begin5);
printf("MergeSort:%d\n", end6 - begin6);
free(a1);
free(a2);
free(a3);
free(a4);
free(a5);
free(a6);
free(a7);
}
結果如下:
6.2 各個排序的穩定性如何判斷?
直接看排完序后是否能保證相同的值的相對位置不會發生變化,若能保證,就是穩定,反之即不穩定,
不要死記,一定要理解分析!
冒泡排序:倆倆對比,前一個大于后一個才發生交換(升序),不會出現相等值互換順序的情況,能保證不改變相同值的相對順序,穩定,
簡單選擇排序:在進行倆數交換位置的程序當中,可能陣列當中有一個數跟發生交換的倆數數值是一樣的,這樣就改變的相同數之間的相對順序,不穩定,
直接插入排序:從前到后一個個元素拿出來跟前面的對比,若插入的數值比被對比的數值小,被對比的數值往后挪動;若插入的數值比被對比的數值大,直接插入到被對比數值的后面,并沒有改變倆個相同值得相對順序,穩定,
希爾排序:在預排序時,相同的資料可能在不同的組里面,沒辦法控制,所以不穩定,
堆排序:比如倆個一樣大的數值,一個在“樹頂”,一個在“樹中”,樹頂元素跟最后一個元素發生交換立馬影響相同數值的相對順序,不穩定,
歸并排序:能保證相同值得相對順序不變,穩定,
快速排序:比如陣列中存在跟key數值一樣的值,而key是肯定會移動的,這樣相對順序就改變了,所以不穩定,
計數排序:計數是在統計每個數出現的次數,但是相同的數哪個在前哪個在后,并沒有區分,所以不穩定,
補充:穩定性有什么意義?
比如我們做了一個考試系統,考生當中先交卷的,成績在陣列的前面,后交卷的,成績在陣列后面,當我們對前幾名進行排名的時候,就可能會遇見倆個分值相同的考生,這時候為了公平性考試用時較短者應當在前面,
6.3八大排序時間/空間復雜度一覽
資料結構八大排序演算法到此介紹結束了,感謝您的閱讀!!!如果內容對你有幫助的話,記得給我三連(點贊、收藏、關注)——做個手有余香的人,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/323431.html
標籤:java