我以前學過資料結構和演算法(data structure and algorithms. 現在普遍簡稱DSA),當時用的Robert Sedgewick的coursera課程,這位大神寫的《演算法(第四版)》,是演算法的經典教材,可惜這本書900頁,我直接被嚇跑了,而coursera課程用的是java,我又不會java,所以課后習題做的例外艱苦,
這幾天,我又想學一下資料結構和演算法,但是我決定用python學,其實我也會c++和c#,但是python顯然是最簡單易用的語言,使用python可以節省很多時間,于是,我在網上找免費的資源,最后,我找到了一個12個小時的視頻,這個視頻是FreeCodeCamp.org提供的,FreeCodeCamp是一個免費提供程式員教學視頻的網站,很多人通過它實作了轉行,它的視頻的特點是時間都很長,最短的可能也有2小時,比起其他的編程視頻,它是一個比較系統的教材,這邊的python資料結構和演算法,一共有6課,分別是Binary Search, Binary Search Trees, Hash和字典,遞回和動態規劃,圖,面試技巧,
我看了第一課,雖然Binary Search比較簡單,也許很多人覺得不用再看了,不過這一課里面,有比較規范的解題程序,從單元測驗,到通用演算法,這些都能和python的語言特性相結合,而且這些都是容易被我們忽略的,
問題
愛麗絲有幾張撲克牌,她將撲克牌按降序排列,然后將它們按順序面朝下放在桌子上,她挑戰鮑勃,讓他翻出盡可能少的撲克牌,從中選出包含給定數字的撲克牌,撰寫一個函式來幫助 Bob 定位卡片,
你為什么要學習資料結構和演算法
無論您是從事軟體開發還是資料科學職業,幾乎可以肯定的是,您會被要求解決編程問題,例如在技術面試或編碼評估中反轉鏈表或平衡二叉樹,
然而,眾所周知,作為軟體開發人員,您在作業中幾乎永遠不會遇到這些問題,所以有理由想知道為什么在面試和編碼評估中會問這樣的問題,解決編程問題表現出以下特點:
- 你可以系統地思考一個問題,然后一步一步地系統地解決它,
- 您可以為您撰寫的程式設想不同的輸入、輸出和邊緣情況,
- 您可以向同事清楚地傳達您的想法并采納他們的建議,
- 最重要的是,您可以將您的想法和想法轉化為可讀的作業代碼,
在面試中測驗的不是您對特定資料結構或演算法的了解,而是您解決問題的方法,您可能無法解決問題并仍然通過面試,反之亦然,在本課程中,您將學習成功解決問題和清晰面試的技能,
方法
閱讀問題后,您可能會對如何解決它有一些想法,您的第一直覺可能是開始撰寫代碼,這不是最佳策略,由于編碼錯誤,您最終可能會花費更長的時間來嘗試解決問題,或者根本無法解決問題,
這是我們將用于解決問題的系統策略:
- 把問題說清楚,識別輸入和輸出格式,
- 提出一些示例輸入和輸出,嘗試覆寫所有邊緣情況,
- 提出問題的正確解決方案,用簡單的英語說出來,
- 實施解決方案并使用示例輸入對其進行測驗,修復錯誤,如果有的話,
- 分析演算法的復雜性并找出效率低下的地方(如果有),
- 應用正確的技術來克服低效率,重復步驟 3 到 6,
*“應用正確的技術”*是常用資料結構和演算法知識派上用場的地方,
解決方案
1. 把問題說清楚,識別輸入和輸出格式,
在編碼挑戰和面試中,您經常會遇到詳細的單詞問題,第一步是用抽象的術語清楚而準確地陳述問題,
例如,在這種情況下,我們可以將撲克牌序串列示為數字串列,翻出一張特定的卡片,就相當于訪問了串列對應位置的數字的值,
現在可以將問題表述如下:
問題
我們需要撰寫一個程式來查找給定數字在按降序排列的數字串列中的位置,我們還需要盡量減少訪問串列中元素的次數,
輸入
cards:按降序排列的數字串列,例如[13, 11, 10, 7, 4, 3, 1, 0]query: 一個數字,要確定其在陣列中的位置,例如7
輸出
position:query在串列中的位置cards,例如3在上述情況下(從 開始計數0)
基于以上內容,我們現在可以創建函式的簽名:
def locate_card(cards, query):
pass
2. 單元測驗
我們的函式應該能夠處理我們傳遞給它的任何有效輸入集,以下是我們可能會遇到的一些可能變化的串列:
- 該數字
query出現在串列中間的某個位置cards, query是 中的第一個元素cards,query是 中的最后一個元素cards,- 該串列
cards僅包含一個元素,即query, - 該串列
cards不包含 numberquery, - 該串列
cards為空, - 該串列
cards包含重復數字, - 該數字
query出現在 中的多個位置cards, - (你能想到更多的變化嗎?)
tests = []
# query occurs in the middle
# 在中間的情況
tests.append({
'input': {
'cards': [13, 11, 10, 7, 4, 3, 1, 0],
'query': 1
},
'output': 6
})
# query is the first element
# 第一張撲克牌就是我們要找的
tests.append({
'input': {
'cards': [4, 2, 1, -1],
'query': 4
},
'output': 0
})
# query is the last element
# 最后一張撲克牌
tests.append({
'input': {
'cards': [3, -1, -9, -127],
'query': -127
},
'output': 3
})
# cards contains just one element, query
# 只有一張撲克牌
tests.append({
'input': {
'cards': [6],
'query': 6
},
'output': 0
})
# cards does not contain query
# 找不到
tests.append({
'input': {
'cards': [9, 7, 5, 2, -9],
'query': 4
},
'output': -1
})
# cards is empty
# 撲克牌佇列是空的
tests.append({
'input': {
'cards': [],
'query': 7
},
'output': -1
})
# numbers can repeat in cards
# 有重復的數字
tests.append({
'input': {
'cards': [8, 8, 6, 6, 6, 6, 6, 3, 2, 2, 2, 0, 0, 0],
'query': 3
},
'output': 7
})
# query occurs multiple times
# 被查找的撲克牌出現很多次
tests.append({
'input': {
'cards': [8, 8, 6, 6, 6, 6, 6, 6, 3, 2, 2, 2, 0, 0, 0],
'query': 6
},
'output': 2
})
讓我們看一下我們的單元測驗,
>>>tests
[{'input': {'cards': [13, 11, 10, 7, 4, 3, 1, 0], 'query': 7}, 'output': 3},
{'input': {'cards': [13, 11, 10, 7, 4, 3, 1, 0], 'query': 1}, 'output': 6},
{'input': {'cards': [4, 2, 1, -1], 'query': 4}, 'output': 0},
{'input': {'cards': [3, -1, -9, -127], 'query': -127}, 'output': 3},
{'input': {'cards': [6], 'query': 6}, 'output': 0},
{'input': {'cards': [9, 7, 5, 2, -9], 'query': 4}, 'output': -1},
{'input': {'cards': [], 'query': 7}, 'output': -1},
{'input': {'cards': [8, 8, 6, 6, 6, 6, 6, 3, 2, 2, 2, 0, 0, 0], 'query': 3},
'output': 7},
{'input': {'cards': [8, 8, 6, 6, 6, 6, 6, 6, 3, 2, 2, 2, 0, 0, 0],
'query': 6},
'output': 2}]
3. 提出問題的正確解決方案,用簡單的語言表達出來,
我們的首要目標應該始終是為問題提出正確的解決方案,這可能是最有效的解決方案,一個問題的最簡單或最明顯的解決方案,通常涉及檢查所有可能的答案,稱為蠻力解決方案,
在這個問題中,想出一個正確的解決方案是很容易的:Bob 可以簡單地將卡片一張一張地翻過來,直到他找到一張上面有給定數字的卡片,下面是我們如何實作它:
- 創建一個
position值為 0的變數, - 檢查是否在索引數量
position的card平等query, - 如果是,
position就是答案并且可以從函式回傳 - 如果不是,則將 的值增加
position1,并重復步驟 2 到 5,直到我們到達最后一個位置, - 如果未找到該號碼,則回傳
-1,
線性搜索演算法:恭喜,我們剛剛撰寫了我們的第一個演算法!演算法只是一個陳述句串列,可以將其轉換為代碼并由計算機在不同的輸入集上執行,這種特定的演算法稱為線性搜索,因為它涉及以線性方式搜索串列,即元素一個元素,
**提示:**在開始編碼之前,始終嘗試用自己的語言表達(說或寫)演算法,它可以根據您的需要簡短或詳細,寫作是清晰思考的好工具,您可能會發現解決方案的某些部分難以表達,這表明您可能無法清楚地思考它,你越能清楚地表達你的想法,你就越容易轉化為代碼,
4. 實施解決方案并使用示例輸入對其進行測驗,修復錯誤,
呼!我們終于準備好實施我們的解決方案了,到目前為止我們所做的所有作業肯定會派上用場,因為我們現在正是我們想要我們的函式做的事情,并且我們有一種簡單的方法可以在各種輸入上測驗它,
這是實作該功能的第一次嘗試,
def locate_card(cards, query):
# Create a variable position with the value 0
position = 0
# Set up a loop for repetition
while True:
# Check if element at the current position matche the query
if cards[position] == query:
# Answer found! Return and exit..
return position
# Increment the position
position += 1
# Check if we have reached the end of the array
if position == len(cards):
# Number not found, return -1
return -1
讓我們用第一個測驗用例來測驗這個函式
>>>result = locate_card(test['input']['cards'], test['input']['query'])
>>>result
3
好極了!結果與輸出匹配,
接著,我們測驗所有的test case,
def test_all(tests, func):
for test in tests:
result = func(**test['input'])
if result == test['output']:
print(f"pass, expected: {test['output']}, actual: {result}")
else:
print(f"fail, expected: {test['output']}, actual: {result}")
我們現在運行所有的單元測驗,
>>>test_all(tests, locate_card)
pass, expected: 3, actual: 3
pass, expected: 6, actual: 6
pass, expected: 0, actual: 0
pass, expected: 3, actual: 3
pass, expected: 0, actual: 0
pass, expected: -1, actual: -1
---------------------------------------------------------------------------
IndexError Traceback (most recent call last)
<ipython-input-54-e822f482ec2b> in <module>
----> 1 test_all(tests, locate_card)
<ipython-input-53-680d62f7d94a> in test_all(tests, func)
1 def test_all(tests, func):
2 for test in tests:
----> 3 result = func(**test['input'])
4 if result == test['output']:
5 print(f"pass, expected: {test['output']}, actual: {result}")
<ipython-input-41-9ed30c367c36> in locate_card(cards, query)
7
8 # Check if element at the current position matche the query
----> 9 if cards[position] == query:
10
11 # Answer found! Return and exit..
IndexError: list index out of range
我們發現,第7個單元測驗報錯了,因為這里cards為空,所以試圖取得第一個元素失敗,
我們可以增加一個檢查position是否合法的陳述句,
def locate_card(cards, query):
position = 0
while position < len(cards):
if cards[position] == query:
return position
position += 1
return -1
然后,我們再測驗,
>>>test_all(tests, locate_card)
pass, expected: 3, actual: 3
pass, expected: 6, actual: 6
pass, expected: 0, actual: 0
pass, expected: 3, actual: 3
pass, expected: 0, actual: 0
pass, expected: -1, actual: -1
pass, expected: -1, actual: -1
pass, expected: 7, actual: 7
pass, expected: 2, actual: 2
不錯,所有的單元測驗都通過了,
5. 分析演算法的復雜性并找出效率低下的地方(如果有),
回想一下原始問題中的陳述:“愛麗絲挑戰鮑勃,讓他翻出盡可能少的卡片,從中選出包含給定數字的卡片,” 我們將這個要求重申為:“最小化我們訪問串列中元素的次數cards”
在我們最小化數量之前,我們需要一種方法來衡量它,由于我們在每次迭代中訪問一個串列元素一次,對于一個大小的串列,N我們最多訪問串列中的元素N,因此,N在最壞的情況下,Bob 可能需要翻轉卡片,才能找到所需的卡片,
假設他每分鐘只允許翻一張牌,如果桌子上放了 30 張牌,他可能需要 30 分鐘才能找到所需的牌,這是他能做到的最好的嗎?鮑勃可以通過只翻出 5 張牌而不是 30 張牌來得出答案嗎?
與找到完成計算機程式執行所需的時間、空間或其他資源量有關的研究領域稱為演算法分析,找出解決給定問題的最佳演算法的程序稱為演算法設計和優化,
復雜性和大 O 符號
演算法的復雜性是演算法對于給定大小的輸入所需的時間和/或空間量的度量,例如
N,除非另有說明,否則術語復雜性總是指最壞情況的復雜性(即程式/演算法處理輸入所花費的最高可能時間/空間),
在線性搜索的情況下:
- 該演算法的時間復雜度是
cN針對某個固定常數的c,它取決于我們在每次迭代中執行的運算元量以及執行一條陳述句所花費的時間,時間復雜度有時也稱為演算法的運行時間, - 的空間復雜度是某個常數
c'(獨立的N),因為我們只需要一個變數position來迭代通過陣列,它占用計算機的記憶體(RAM)的恒定空間,
大 O 表示法:最壞情況的復雜性通常使用大 O 表示法表示,在 Big O 中,我們去掉了固定常數和變數的較低冪以捕捉輸入大小與演算法復雜度之間關系的趨勢,即如果演算法的復雜度為
cN^3 + dN^2 + eN + f,則在 Big O 符號中表示為O(N^3)
因此,線性搜索的時間復雜度為O(N),其空間復雜度為O(1),
6. 應用正確的技術來克服低效率,重復步驟 3 到 6,
目前,我們只是一張一張地翻閱卡片,甚至沒有利用它們被排序的面孔,這稱為蠻力方法,
如果 Bob 能在第一次嘗試時以某種方式猜出這張牌那就太好了,但是當所有的牌都翻過來時,根本不可能猜出正確的牌,
下一個最好的想法是隨機選擇一張卡片,并使用串列已排序的事實來確定目標卡片位于它的左側還是右側,事實上,如果我們選擇中間卡,我們可以將要測驗的附加卡數量減少到串列大小的一半,然后,我們可以簡單地對每一半重復這個程序,這種技術稱為二分查找,
7. 提出問題的正確解決方案,用簡單的英語說出來,
以下是二分搜索如何應用于我們的問題:
- 找到串列的中間元素,
- 如果與查詢到的號碼匹配,則回傳中間位置作為答案,
- 如果小于查詢的數,則搜索串列的前半部分
- 如果大于查詢的數,則搜索串列的后半部分
- 如果沒有更多元素剩余,則回傳 -1,
8. 實施解決方案并使用示例輸入對其進行測驗,修復錯誤
def locate_card(cards, query):
lo, hi = 0, len(cards) - 1
while lo <= hi:
mid = (lo + hi) // 2
mid_number = cards[mid]
print("lo:", lo, ", hi:", hi, ", mid:", mid, ", mid_number:", mid_number)
if mid_number == query:
return mid
elif mid_number < query:
hi = mid - 1
elif mid_number > query:
lo = mid + 1
return -1
單元測驗
>>>test_all(tests, locate_card)
lo: 0 , hi: 7 , mid: 3 , mid_number: 7
pass, expected: 3, actual: 3
lo: 0 , hi: 7 , mid: 3 , mid_number: 7
lo: 4 , hi: 7 , mid: 5 , mid_number: 3
lo: 6 , hi: 7 , mid: 6 , mid_number: 1
pass, expected: 6, actual: 6
lo: 0 , hi: 3 , mid: 1 , mid_number: 2
lo: 0 , hi: 0 , mid: 0 , mid_number: 4
pass, expected: 0, actual: 0
lo: 0 , hi: 3 , mid: 1 , mid_number: -1
lo: 2 , hi: 3 , mid: 2 , mid_number: -9
lo: 3 , hi: 3 , mid: 3 , mid_number: -127
pass, expected: 3, actual: 3
lo: 0 , hi: 0 , mid: 0 , mid_number: 6
pass, expected: 0, actual: 0
lo: 0 , hi: 4 , mid: 2 , mid_number: 5
lo: 3 , hi: 4 , mid: 3 , mid_number: 2
pass, expected: -1, actual: -1
pass, expected: -1, actual: -1
lo: 0 , hi: 13 , mid: 6 , mid_number: 6
lo: 7 , hi: 13 , mid: 10 , mid_number: 2
lo: 7 , hi: 9 , mid: 8 , mid_number: 2
lo: 7 , hi: 7 , mid: 7 , mid_number: 3
pass, expected: 7, actual: 7
lo: 0 , hi: 14 , mid: 7 , mid_number: 6
fail, expected: 2, actual: 7
我們發現,最后一個單元測驗失敗了,
回顧一下最后一個單元測驗,
>>>tests[-1]
{'input': {'cards': [8, 8, 6, 6, 6, 6, 6, 6, 3, 2, 2, 2, 0, 0, 0], 'query': 6},
'output': 2}
原來,這里有多個6,但是我們并沒有回傳第一個6,這里,我們可以增加一個檢查,如果我們找到的mid前面還有和query相同的值,那么我們就繼續往前面找,
為方便起見,我們將定義一個名為 的輔助函式test_location,它將以 list cards、 thequery和mid作為輸入,
def test_location(cards, query, mid):
mid_number = cards[mid]
print("mid:", mid, ", mid_number:", mid_number)
if mid_number == query:
if mid-1 >= 0 and cards[mid-1] == query:
return 'left'
else:
return 'found'
elif mid_number < query:
return 'left'
else:
return 'right'
def locate_card(cards, query):
lo, hi = 0, len(cards) - 1
while lo <= hi:
print("lo:", lo, ", hi:", hi)
mid = (lo + hi) // 2
result = test_location(cards, query, mid)
if result == 'found':
return mid
elif result == 'left':
hi = mid - 1
elif result == 'right':
lo = mid + 1
return -1
測驗
>>>test_all(tests, locate_card)
lo: 0 , hi: 7
mid: 3 , mid_number: 7
pass, expected: 3, actual: 3
lo: 0 , hi: 7
mid: 3 , mid_number: 7
lo: 4 , hi: 7
mid: 5 , mid_number: 3
lo: 6 , hi: 7
mid: 6 , mid_number: 1
pass, expected: 6, actual: 6
lo: 0 , hi: 3
mid: 1 , mid_number: 2
lo: 0 , hi: 0
mid: 0 , mid_number: 4
pass, expected: 0, actual: 0
lo: 0 , hi: 3
mid: 1 , mid_number: -1
lo: 2 , hi: 3
mid: 2 , mid_number: -9
lo: 3 , hi: 3
mid: 3 , mid_number: -127
pass, expected: 3, actual: 3
lo: 0 , hi: 0
mid: 0 , mid_number: 6
pass, expected: 0, actual: 0
lo: 0 , hi: 4
mid: 2 , mid_number: 5
lo: 3 , hi: 4
mid: 3 , mid_number: 2
pass, expected: -1, actual: -1
pass, expected: -1, actual: -1
lo: 0 , hi: 13
mid: 6 , mid_number: 6
lo: 7 , hi: 13
mid: 10 , mid_number: 2
lo: 7 , hi: 9
mid: 8 , mid_number: 2
lo: 7 , hi: 7
mid: 7 , mid_number: 3
pass, expected: 7, actual: 7
lo: 0 , hi: 14
mid: 7 , mid_number: 6
lo: 0 , hi: 6
mid: 3 , mid_number: 6
lo: 0 , hi: 2
mid: 1 , mid_number: 8
lo: 2 , hi: 2
mid: 2 , mid_number: 6
pass, expected: 2, actual: 2
洗掉所有的print以后,我們完成了這個任務,
def test_location(cards, query, mid):
if cards[mid] == query:
if mid-1 >= 0 and cards[mid-1] == query:
return 'left'
else:
return 'found'
elif cards[mid] < query:
return 'left'
else:
return 'right'
def locate_card(cards, query):
lo, hi = 0, len(cards) - 1
while lo <= hi:
mid = (lo + hi) // 2
result = test_location(cards, query, mid)
if result == 'found':
return mid
elif result == 'left':
hi = mid - 1
elif result == 'right':
lo = mid + 1
return -1
9. 分析演算法的復雜性并找出效率低下的地方(如果有),
再一次,讓我們嘗試計算演算法中的迭代次數,如果我們從一個包含 N 個元素的陣列開始,那么每次下一次迭代時陣列的大小都會減少一半,直到只剩下 1 個元素,
初始長度 - N
迭代 1 - N/2
迭代 2 -N/4即N/2^2
迭代 3 -N/8即N/2^3
…
迭代 k - N/2^k
由于陣列的最終長度為 1,我們可以找到
N/2^k = 1
重新排列條款,我們得到
N = 2^k
取對數
k = log N
哪里log是指以 2 為底的對數,因此,我們的演算法的時間復雜度為O(log N),這個事實通常被表述為:二分查找在對數時間內運行,您可以驗證二分查找的空間復雜度為O(1),
10. 速度比較
我們把我們最初的方法命名為locate_card_linear,
def locate_card_linear(cards, query):
position = 0
while position < len(cards):
if cards[position] == query:
return position
position += 1
return -1
我們新建一個測驗用例,
large_test = {
'input': {
'cards': list(range(10000000, 0, -1)),
'query': 2
},
'output': 9999998
}
brutal force 方法:
>>>%timeit locate_card_linear(**large_test["input"])
1.69 s ± 152 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
binary search:
>>>%timeit locate_card(**large_test["input"])
9.88 μs ± 809 ns per loop (mean ± std. dev. of 7 runs, 100000 loops each)
兩者速度相差160,000倍,所以,用演算法很重要,
此外,隨著輸入的大小變大,差異只會變得更大,對于 10 倍大小的串列,線性搜索將運行 10 倍,而二分搜索只需要 3 次額外的操作!(你能驗證一下嗎?)這就是復雜度**O(N)和O(log N)**之間的真正區別,
另一種看待它的方式是c * N / log N,對于某些固定常量,二分搜索比線性搜索運行 得快幾倍c,由于log N與 相比增長非常緩慢N,因此差異隨著輸入的大小而變大,這是一個圖表,顯示了如何比較演算法運行時間的常用函式(來源):
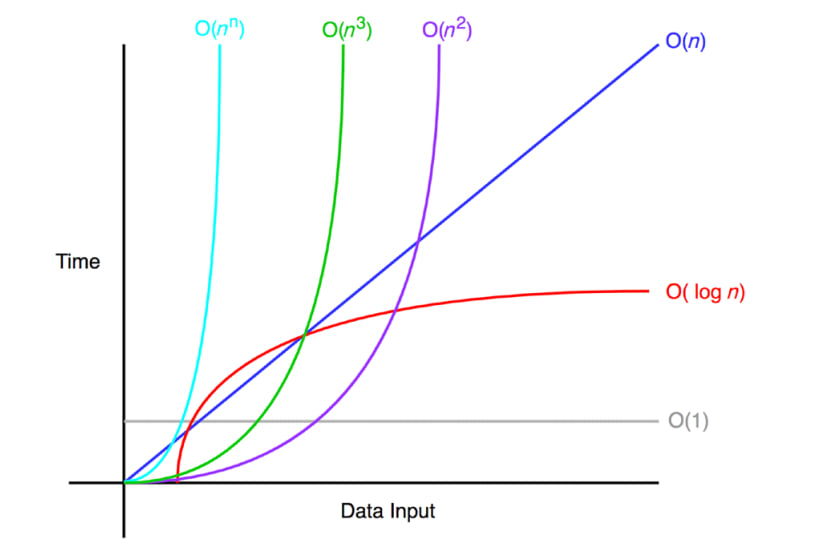
你現在明白為什么我們在使用大 O 符號表示復雜性時忽略常數和低階項了嗎?
通用二分搜索
下面是二分搜索背后的一般策略,它適用于各種問題:
- 想出一個條件來確定答案是在給定位置之前、之后還是在給定位置
- 檢索串列的中點和中間元素,
- 如果是答案,則回傳中間位置作為答案,
- 如果答案在它之前,請使用串列的前半部分重復搜索
- 如果答案在其后,請使用串列的后半部分重復搜索,
這是在 Python 中實作的二分搜索的通用演算法:
def binary_search(lo, hi, condition):
"""TODO - add docs"""
while lo <= hi:
mid = (lo + hi) // 2
result = condition(mid)
if result == 'found':
return mid
elif result == 'left':
hi = mid - 1
else:
lo = mid + 1
return -1
二分查找的最壞情況復雜度或運行時間為O(log N),前提是用于確定答案是在給定位置之前、之后還是在給定位置的條件的復雜度為O(1),
請注意,binary_search接受一個函式condition作為引數,與 C++ 和 Java 不同,Python 允許將函式作為引數傳遞給其他函式,
我們現在可以locate_card使用該binary_search函式更簡潔地重寫該函式,
def locate_card(cards, query):
def condition(mid):
if cards[mid] == query:
if mid > 0 and cards[mid-1] == query:
return 'left'
else:
return 'found'
elif cards[mid] < query:
return 'left'
else:
return 'right'
return binary_search(0, len(cards) - 1, condition)
測驗
>>>test_all(tests, locate_card)
pass, expected: 3, actual: 3
pass, expected: 6, actual: 6
pass, expected: 0, actual: 0
pass, expected: 3, actual: 3
pass, expected: 0, actual: 0
pass, expected: -1, actual: -1
pass, expected: -1, actual: -1
pass, expected: 7, actual: 7
pass, expected: 2, actual: 2
該binary_search功能現在也可用于解決其他問題,這是一個經過測驗的邏輯,
問題:給定一個按升序排序的整數陣列 nums,找到給定數字的開始和結束位置,
這僅在兩個重要方面與問題不同:
- 數字按升序排列,
- 我們正在尋找遞增順序和遞減順序,
這是解決問題的完整代碼,通過對我們之前的函式進行微小修改獲得:
def first_position(nums, target):
def condition(mid):
if nums[mid] == target:
if mid > 0 and nums[mid-1] == target:
return 'left'
return 'found'
elif nums[mid] < target:
return 'right'
else:
return 'left'
return binary_search(0, len(nums)-1, condition)
def last_position(nums, target):
def condition(mid):
if nums[mid] == target:
if mid < len(nums)-1 and nums[mid+1] == target:
return 'right'
return 'found'
elif nums[mid] < target:
return 'right'
else:
return 'left'
return binary_search(0, len(nums)-1, condition)
def first_and_last_position(nums, target):
return first_position(nums, target), last_position(nums, target)
我們可以通過在此處提交來測驗我們的解決方案:https : //leetcode.com/problems/find-first-and-last-position-of-element-in-sorted-array/
重溫
這是我們用于解決問題的系統策略:
- 把問題說清楚,識別輸入和輸出格式,
- 提出一些示例輸入和輸出,嘗試覆寫所有邊緣情況,
- 提出問題的正確解決方案,用簡單的英語說出來,
- 實施解決方案并使用示例輸入對其進行測驗,修復錯誤,如果有的話,
- 分析演算法的復雜性并找出效率低下的地方(如果有),
- 應用正確的技術來克服低效率,重復步驟 3 到 6,
使用此模板使用此方法解決問題:https : //jovian.ai/aakashns/python-problem-solving-template
這種看似顯而易見的策略將幫助您解決在面試或編碼評估中將面臨的幾乎所有編程問題,
本課程的目的是通過反復將其應用于不同型別的問題,重新連接您的大腦以使用這種方法進行思考,這是一門關于系統地思考問題并將這些想法轉化為代碼的課程,
練習
這里有一些資源可以了解更多資訊并找到要練習的問題,
二分搜索賦值:https://jovian.ai/aakashns/python-binary-search-assignment
LeetCode 上的二分搜索問題:https://leetcode.com/problems/binary-search/
GeeksForGeeks 上的二分搜索問題:https://www.geeksforgeeks.org/binary-search/
Codeforces 上的二進制搜索問題:https://codeforces.com/problemset ? tags = binary+search
使用此模板解決問題:https://jovian.ai/aakashns/python-problem-solving-template
在論壇上開始討論:https://jovian.ai/forum/c/data-structures-and-algorithms-in-python/lesson-1-binary-search-linked-lists-and-complex/81
課后作業 - 旋轉串列
這里,我們將運用所學的Binary Search來解決一個復雜問題,
問題 - 旋轉串列
我們將逐步解決以下問題:
有一個排序好的整數串列,被旋轉(rotate)了若干次,寫一個函式,找出其被旋轉的最小次數,時間復雜度為O(log N), N 是串列的長度,串列里沒有重復數字,
例子:串列[0, 2, 3, 4, 5, 6, 9]旋轉了3次,得到[5, 6, 9, 0, 2, 3, 4]
我們定義旋轉(rotation)為把最后串列的最后一個數字插入到最前面,如[3, 2, 4, 1]旋轉一次得到[1, 3, 2, 4],
方法
以下是我們將用于解決問題的系統策略:
- 把問題說清楚,識別輸入和輸出格式,
- 提出一些示例輸入和輸出,嘗試覆寫所有邊緣情況,
- 提出問題的正確解決方案,
- 測驗方案,修正方案,
解決方案
1. 把問題說清楚,識別輸入和輸出格式
問題
找出一個被旋轉串列的旋轉次數
輸入
nums: 一個被旋轉的數列
輸出
rotations:被旋轉的次數
基于以上,我們有函式的簽名為
from typing import List
def count_rotations(nums: List[int]) -> int:
pass
2. 單元測驗
tests = []
# A list of size 8 rotated 5 times.
# 一個長度為8,旋轉5次的數列
tests.append({
'input': {
'nums': [4, 5, 6, 7, 8, 1, 2, 3]
},
'output': 5
})
# A list that wasn't rotated at all.
# 沒有選裝的數列
tests.append({
'input': {
'nums': [1, 2, 3, 4, 5, 6, 7, 8]
},
'output': 0
})
# A list that was rotated just once.
# 旋轉一次的數列
tests.append({
'input': {
'nums': [8, 1, 2, 3, 4, 5, 6]
},
'output': 1
})
# A list that was rotated n-1 times, where n is the size of the list.
# 旋轉n-1次的數列
tests.append({
'input': {
'nums': [2, 3, 4, 5, 6, 7, 8, 1]
},
'output': 7
})
# A list that was rotated n times, where n is the size of the list
# 旋轉次數等于數列長度
tests.append({
'input': {
'nums': [1, 2, 3, 4, 5, 6, 7, 8]
},
'output': 0
})
# An empty list.
# 空數列
tests.append({
'input': {
'nums': []
},
'output': 0
})
# A list containing just one element.
# 只有一個數字的數列
tests.append({
'input': {
'nums': [1]
},
'output': 0
})
查看
>>>tests
[{'input': {'nums': [4, 5, 6, 7, 8, 1, 2, 3]}, 'output': 5},
{'input': {'nums': [1, 2, 3, 4, 5, 6, 7, 8]}, 'output': 0},
{'input': {'nums': [8, 1, 2, 3, 4, 5, 6]}, 'output': 1},
{'input': {'nums': [2, 3, 4, 5, 6, 7, 8, 1]}, 'output': 7},
{'input': {'nums': [1, 2, 3, 4, 5, 6, 7, 8]}, 'output': 0},
{'input': {'nums': []}, 'output': 0},
{'input': {'nums': [1]}, 'output': 0}]
測驗所有
def test_all(tests, func):
for test in tests:
actual = func(**test['input'])
status = "pass" if actual == test['output'] else "fail"
print(f"{status}, expected:{test['output']}, actual:{actual}")
運行
>>>test_all(tests, count_rotations)
fail, expected:5, actual:None
fail, expected:0, actual:None
fail, expected:1, actual:None
fail, expected:7, actual:None
fail, expected:0, actual:None
fail, expected:0, actual:None
fail, expected:0, actual:None
3. 提出問題的正確解決方案
這里,假如我們用brutal force,如果要找到旋轉了幾次,就要找出第一個數字的位置,那么我們不斷取出兩個數字,直到找到了第二個數字小于第一個數字的情況,如果沒找到,那么說明這個數列沒有被旋轉過,或者旋轉了n次,n等于數列長度,
直接運用binary search,
您可能已經猜到了,我們可以應用binary search來解決這個問題,在二分搜索中我們需要回答的關鍵問題是:給定中間元素,如何決定它是答案(最小的數字),還是答案在它的左邊或右邊,
如果中間元素比它的前任小,那么它就是答案,但是,如果不是,則此檢查不足以確定答案位于其左側還是右側,考慮以下示例,
[7, 8, 1, 3, 4, 5, 6] (答案位于中間元素的左側)
[1, 2, 3, 4, 5, -1, 0] (答案位于中間元素的右側)
這里有一個檢查可以幫助我們確定答案在左邊還是右邊:如果串列的中間元素小于范圍的最后一個元素,那么答案就在它的左邊,否則,答案就在右邊,
def count_rotations_binary(nums):
lo = 0
hi = len(nums)-1
while lo <= hi:
mid = (lo + hi) // 2
mid_number = nums[mid]
# Uncomment the next line for logging the values and fixing errors.
# print("lo:", lo, ", hi:", hi, ", mid:", mid, ", mid_number:", mid_number)
if mid > 0 and nums[mid]<nums[mid-1]:
# The middle position is the answer
return mid
elif nums[mid]<nums[hi]:
# Answer lies in the left half
hi = mid - 1
else:
# Answer lies in the right half
lo = mid + 1
return 0
測驗
>>>test_all(tests, count_rotations_binary)
pass, expected:5, actual:5
pass, expected:0, actual:0
pass, expected:1, actual:1
pass, expected:7, actual:7
pass, expected:0, actual:0
pass, expected:0, actual:0
pass, expected:0, actual:0
不錯,通過了,
leetcode上面有一題和這個差不多,你可以試試:
https://leetcode.com/problems/search-in-rotated-sorted-array/
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/323449.html
標籤:python