淺談注意力機制的作用
- 前言
- 什么是注意力機制
- 空間注意力
- 對于時間步的注意力機制
- 1.資料集的制作
- 2.建立注意力模型
- 3.建立整體神經網路
- 4.完整代碼
- 5.實驗效果
- 通道注意力機制
前言
Attention機制是很好的一個東西,Attention機制在近幾年來在影像,自然語言處理和cv等領域中都取得了重要的突破,被證明有益于提高模型的性能,讓我們一起來了解下注意力機制吧,

什么是注意力機制
所謂Attention機制,便是聚焦于區域資訊的機制,比如,影像中的某一個影像區域,隨著任務的變化,注意力區域往往會發生變化,

面對上面這樣的一張圖,如果你只是從整體來看,只看到了很多人頭,但是你拉近一個一個仔細看就了不得了,都是天才科學家,圖中除了人臉之外的資訊其實都是無用的,也做不了什么任務,Attention機制便是要找到這些最有用的資訊,可以想到,最簡單的場景就是從照片中檢測人臉了,
注意力機制的本質就是定位到感興趣的資訊,抑制無用資訊,結果通常都是以概率圖或者概率特征向量的形式展示,
我們來看下這個例子可能久更加明白了:假設我們要翻譯一句話:打電腦游戲,play computer game,
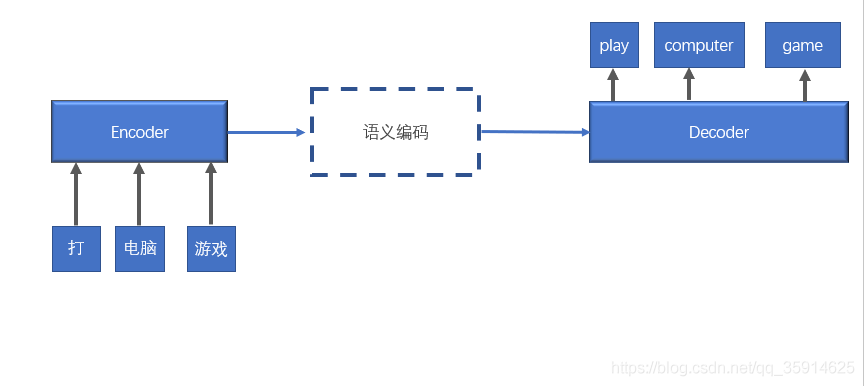
如果不引入注意力機制,那么我們從Encoder獲得語意編碼c之后,這個語意編碼在Decoder中傳遞,其內容就和Encoder無關了,但是事實上我們希望在翻譯打電腦游戲中的打的時候,我們更注意打->play的轉換,此時我們希望Decoder更加注意Encoder從打中提取出來的特征,這就是注意力機制的概念,它的本意是讓神經網路模型在做特定的事的時候可以注意到它需要注意的地方,
由于神經網路是一堆數字的傳遞,每個事物的特征也是由一堆數字組成的,比如打字的特征也是一堆數字,電腦的特征也是一堆數字,游戲的特征也是一堆數字,語意編碼就是這么多特征的組合,
那么如何使得神經網路模型對某個內容進行注意呢?其實就是將改變不同內容的權重,當我們需要神經網路注意到打的時候,我們只需要提高打字的特征的權重就可以了,
假設函式 f 可以用于提取特征,函式 g 可以實作解碼,那么如果我們要神經網路注意到打,可以通過如下方式進行,
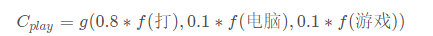
空間注意力
空間域將原始圖片中的空間資訊變換到另一個空間中并保留了關鍵資訊,
空間注意力的作者發明者認為之前通道pooling的方法太過于暴力,直接將資訊合并會導致關鍵資訊無法識別出來,所以提出了一個叫空間轉換器(spatial transformer)的模塊,將圖片中的的空間域資訊做對應的空間變換,從而能將關鍵的資訊提取出來,

比如這個直觀的實驗圖:
(a)列是原始的圖片資訊,其中第一個手寫數字7沒有做任何變換,第二個手寫數字5,做了一定的旋轉變化,而第三個手寫數字6,加上了一些噪聲信號;
(b)列中的彩色邊框是學習到的spatial transformer的框盒(bounding
box),每一個框盒其實就是對應圖片學習出來的一個spatial transformer;
?列中是通過spatial
transformer轉換之后的特征圖,可以看出7的關鍵區域被選擇出來,5被旋轉成為了正向的圖片,6的噪聲資訊沒有被識別進入,
對于時間步的注意力機制
ps:(我感覺cv里面叫空間注意力,不知道我理解錯沒,如果理解錯了私信我)
1.資料集的制作
本次我們要進行的是 使用 注意力機制 + LSTM 進行時間序列預測
默認的 n = 30000, input_dim = 2 ,timesteps = 20,生成的資料為:

假設我們存在一個TIME_STEP為10,INPUT_DIM為2的輸入,當我們的TIME_STEP為2的輸入為[0,0]時,其輸出為0;當我們的TIME_STEP為2的輸入為[1,1]時,其輸出為1;其它TIME_STEP等于其它的時候,如0,1,3,……9時,其對應的時間的輸入為為符合正態分布的數,
代碼:
#-------------------------------------------#
# 獲得資料集
# attention_column代表我們希望被注意的列
#-------------------------------------------#
def get_data_recurrent(n, time_steps, input_dim, attention_column=2):
x = np.random.normal(loc=0, scale=10, size=(n, time_steps, input_dim))
y = np.random.randint(low=0, high=2, size=(n, 1))
x[:, attention_column, :] = np.tile(y[:], (1, input_dim))
return x, y
所以當我們使用這樣的資料去進行 注意力機制 LSTM 的訓練,我們希望得到的結果是 注意力層 主要關注第2個timestep 而對其他timestep 的關注度較低,
#-------------------------------------#
x = [[[14.05795148 10.6586937 ]
[-5.17788409 3.0967234 ]
[ 1. 1. ]
[-7.16327903 7.36591461]
[ 3.07887461 18.46302035]
[ 8.7123103 15.77254757]
[-7.6266161 -4.56511326]
[ 1.64038985 0.10782463]
[ 3.62548177 3.22431191]
[ 0.76630364 -3.95249622]]]
y = [[1]]
#-------------------------------------#
#-------------------------------------#
x = [[[ -4.22167643 1.98029051]
[ -1.00985459 15.08588672]
[ 0. 0. ]
[ 13.48448467 -0.66743308]
[ 31.3199347 3.0311851 ]
[ -4.81579489 1.62016606]
[ 7.40993759 4.25739609]
[ 13.37376609 -11.63055067]
[ -6.46277603 -13.94173142]
[-12.01871193 -9.53632924]]]
y = [[0]]
#-----------------------------------
2.建立注意力模型
我們將一串時間序列傳入到LSTM中,可以獲得一個維度為(batch_size, time_steps, lstm_units)的輸出,我們可以把其當作每一個時間節點的特征,
經過Permute將2、1軸翻轉后,其維度從(batch_size, time_steps, lstm_units)轉化成(batch_size, lstm_units, time_steps),
再經過一個全連接層和Softmax后,其維度仍為(batch_size, lstm_units, time_steps),其實際內涵為,利用全連接層計算每一個time_steps的權重,
再經過Permute將2、1軸翻轉后,其維度從(batch_size, lstm_units, time_steps)轉化成(batch_size, time_steps, lstm_units),代表每一個STEP中每一個特征的權重,
最后將這個結果與Input相乘,也就是將每個STEP的權重,乘上他們的特征,
3.建立整體神經網路
我們構建一個簡單的注意力機制的神經網路,進行預測,
代碼:
#-------------------------------------------#
# 建立注意力模型
#-------------------------------------------#
def get_attention_model():
inputs = Input(shape=(TIME_STEPS, INPUT_DIM,))
lstm_units = 32
# (batch_size, time_steps, INPUT_DIM) -> (batch_size, input_dim, lstm_units)
lstm_out = LSTM(lstm_units, return_sequences=True)(inputs)
attention_mul = attention_3d_block(lstm_out)
# (batch_size, input_dim, lstm_units) -> (batch_size, input_dim*lstm_units)
attention_mul = Flatten()(attention_mul)
output = Dense(1, activation='sigmoid')(attention_mul)
model = Model(input=[inputs], output=output)
return model
‘’
4.完整代碼
from keras.layers import merge
from keras.layers.core import *
from keras.layers.recurrent import LSTM
from keras.models import *
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
INPUT_DIM = 2
TIME_STEPS = 10
#-------------------------------------------#
# 對每一個step的INPUT_DIM的attention幾率
# 求平均
#-------------------------------------------#
def get_activations(model, inputs, layer_name=None):
inp = model.input
for layer in model.layers:
if layer.name == layer_name:
Y = layer.output
model = Model(inp,Y)
out = model.predict(inputs)
# print("*"*100)
# print(out)
# print("*" * 100)
out = np.mean(out[0],axis=-1)
return out
#-------------------------------------------#
# 獲得資料集
# attention_column代表我們希望被注意的列
#-------------------------------------------#
def get_data_recurrent(n, time_steps, input_dim, attention_column=2):
x = np.random.normal(loc=0, scale=10, size=(n, time_steps, input_dim))
y = np.random.randint(low=0, high=2, size=(n, 1))
x[:, attention_column, :] = np.tile(y[:], (1, input_dim))
print(x)
return x, y
#-------------------------------------------#
# 注意力模塊
#-------------------------------------------#
def attention_3d_block(inputs):
# inputs.shape = (batch_size, time_steps, lstm_units)
# (batch_size, time_steps, lstm_units) -> (batch_size, lstm_units, time_steps)
a = Permute((2, 1))(inputs)
# 對最后一維進行全連接
# (batch_size, lstm_units, time_steps) -> (batch_size, lstm_units, time_steps)
a = Dense(TIME_STEPS, activation='softmax')(a)
# (batch_size, lstm_units, time_steps) -> (batch_size, time_steps, lstm_units)
a_probs = Permute((2, 1), name='attention_vec')(a)
# 相乘
# 相當于獲得每一個step中,每個維度在所有step中的權重
output_attention_mul = merge([inputs, a_probs], name='attention_mul', mode='mul')
return output_attention_mul
#-------------------------------------------#
# 建立注意力模型
#-------------------------------------------#
def get_attention_model():
inputs = Input(shape=(TIME_STEPS, INPUT_DIM,))
lstm_units = 32
# (batch_size, time_steps, INPUT_DIM) -> (batch_size, input_dim, lstm_units)
lstm_out = LSTM(lstm_units, return_sequences=True)(inputs)
attention_mul = attention_3d_block(lstm_out)
# (batch_size, input_dim, lstm_units) -> (batch_size, input_dim*lstm_units)
attention_mul = Flatten()(attention_mul)
output = Dense(1, activation='sigmoid')(attention_mul)
model = Model(input=[inputs], output=output)
return model
if __name__ == '__main__':
N = 100000
#l利用高斯分步
X, Y = get_data_recurrent(N, TIME_STEPS, INPUT_DIM)
# print(Y)
model = get_attention_model()
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
print(model.summary())
model.fit(X, Y, epochs=1, batch_size=64, validation_split=0.1)
attention_vectors = []
for i in range(300):
testing_X, testing_Y = get_data_recurrent(1, TIME_STEPS, INPUT_DIM)
attention_vector = get_activations(model,testing_X,layer_name='attention_vec')
print('attention =', attention_vector)
assert (np.sum(attention_vector) - 1.0) < 1e-5
attention_vectors.append(attention_vector)
attention_vector_final = np.mean(np.array(attention_vectors), axis=0)
pd.DataFrame(attention_vector_final, columns=['attention (%)']).plot(kind='bar',
title='Attention Mechanism as '
'a function of input'
' dimensions.')
plt.show()
5.實驗效果
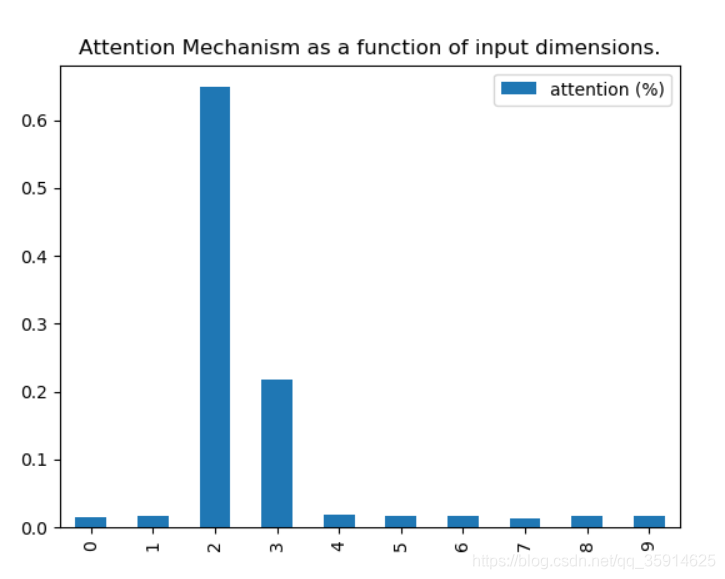
通道注意力機制
在卷積網路中,一個維度是影像的尺度空間,即長寬,另一個維度就是通道,因此基于通道的Attention也是很常用的機制,
在mobileNetv3,本質上是利用了一個基于通道的Attention模型,它通過建模各個特征通道的重要程度,然后針對不同的任務增強或者抑制不同的通道,原理圖如下,
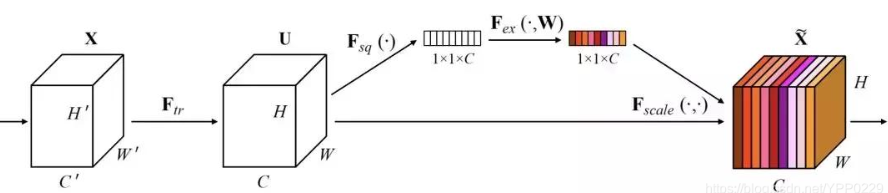
在正常的卷積操作后分出了一個旁路分支,首先進行Squeeze操作(即圖中Fsq(·)),它將空間維度進行特征壓縮,即每個二維的特征圖變成一個實數(mobileNetv3利用全域平均池化),相當于具有全域感受野的池化操作,特征通道數不變,
然后是Excitation操作(即圖中的Fex(·)),它通過引數w為每個特征通道生成權重,w被學習用來顯式地建模特征通道間的相關性,在文章中,使用了一個2層bottleneck結構(先降維最后升維)的全連接層+relu6+hard_swish函式來實作,
得到了每一個特征通道的權重之后,就將該權重應用于原來的每個特征通道,基于特定的任務,就可以學習到不同通道的重要性,
將其機制應用于若干基準模型,在增加少量計算量的情況下,獲得了更明顯的性能提升,作為一種通用的設計思想,它可以被用于任何現有網路,具有較強的實踐意義,
通道注意力機制的本質,在于建模了各個特征之間的重要性,對于不同的任務可以根據輸入進行特征分配,簡單而有效,
代碼:
def squeeze(inputs):
# 注意力機制單元
input_channels = int(inputs.shape[-1])
x = GlobalAveragePooling2D()(inputs)
x = Dense(int(input_channels / 4))(x)
x = Activation(relu6)(x)
x = Dense(input_channels)(x)
x = Activation(hard_swish)(x)
x = Reshape((1, 1, input_channels))(x)
x = Multiply()([inputs, x])
return x
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/3325.html
標籤:python