前言:
網路爬蟲無疑會為我們生活帶來便利,但是過度的惡意爬取也會造成服務器的負擔,這里還是請諸位利用好這把爬蟲雙刃劍,
目錄
一、話不多說,先看代碼,隨后詳談
1.代碼如下:
(1)單個網頁爬取
(2)多個網頁
2.運行結果 (只是一部分)
二、思路流程
1.正所謂巧婦難為無米之炊,我們要爬取資訊得要源代碼才行,可以用requests解決,
2.分析源代碼,找到包含資訊的標簽,用beautifulsoup遍歷找到,
3.利用beautifulsoup通過標簽名字和屬性遍歷標簽,查找到資訊,
4.觀察網址資訊,制作出爬取多個網頁的回圈,比如說網址的后半段的某些數字的間隔是有規律的,如下所示
二、代碼解釋
1.代碼庫的解釋
2.代碼段的解釋
(1)requests代碼段的解釋
(2)beautifulsoup代碼段的解釋
(3)整個代碼段的解釋
三、總結
一、話不多說,先看代碼,隨后詳談
1.代碼如下:
(1)單個網頁爬取
import requests
from bs4 import BeautifulSoup
kv={'user-agent':'Mozilla/5.0'}
r=requests.get('https://movie.douban.com/top250',headers=kv)
if (r.status_code==200):
source=r.text
soup = BeautifulSoup(source,'html.parser')
items=soup.find_all('div','item')
for i in items:
for j in range(len(i.find_all('span','title'))):
print(i.find_all('span','title')[j].string,end='')
print(i.find_all('span','other')[0].string)
print(i.find_all('p')[0].text.replace('\n','').replace(' ',''))
if(len(i.find_all('span','inq'))!=0):
print('評語:'+i.find_all('span','inq')[0].string)
print('評分:'+i.find_all(property="v:average")[0].string)
print("\n")
else:
print("哦豁~目標網站不給予回應")(2)多個網頁
import requests
from bs4 import BeautifulSoup
kv={'user-agent':'Mozilla/5.0'}
page=0
while (page<=250):
r=requests.get('https://movie.douban.com/top250?start='+str(page)+'&filter=',headers=kv)
page=page+25
if (r.status_code==200):
source=r.text
soup = BeautifulSoup(source,'html.parser')
items=soup.find_all('div','item')
for i in items:
for j in range(len(i.find_all('span','title'))):
print(i.find_all('span','title')[j].string,end='')
print(i.find_all('span','other')[0].string)
print(i.find_all('p')[0].text.replace('\n','').replace(' ',''))
if(len(i.find_all('span','inq'))!=0):
print('評語:'+i.find_all('span','inq')[0].string)
print('評分:'+i.find_all(property="v:average")[0].string)
print("\n")
else:
print("哦豁~目標網站不給予回應")
print('OVER~')
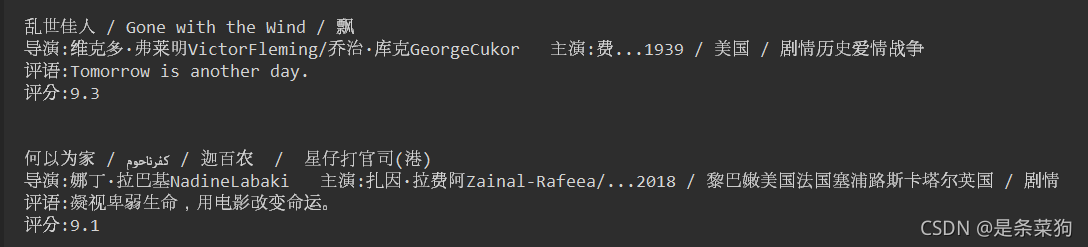
2.運行結果 (只是一部分)
二、思路流程
1.正所謂巧婦難為無米之炊,我們要爬取資訊得要源代碼才行,可以用requests解決,
2.分析源代碼,找到包含資訊的標簽,用beautifulsoup遍歷找到,
比如我們此次要爬取的電影都在items標簽中,所有的電影名字都在title標簽中,導演在p標簽中等等,都是需要我們需要留心的,

3.利用beautifulsoup通過標簽名字和屬性遍歷標簽,查找到資訊,
這里用到了beautifulsoup的find_all利用標簽名字和屬性遍歷,標簽的.string和.text屬性進行字符提取輸出,這里的string和text有所不同,string只能讀取含有一個字標簽的標簽字符,而text可以讀取含有多個字標簽的所有字符,
4.觀察網址資訊,制作出爬取多個網頁的回圈,比如說網址的后半段的某些數字的間隔是有規律的,如下所示:
http://www.gugugu.com/top250?start=0&filter=
http://www.gugugu.com/top250?start=25&filter=
http://www.gugugu.com/top250?start=50&filter=
二、代碼解釋
1.代碼庫的解釋
代碼所需要的是reuqests和beautifulsoup的庫,request的功能是訪問網站并回傳回應資訊和網站的源代碼,而beautifulsoup的功能是將源代碼規范化以便查找其中的對應的資訊,簡單來說就是我們爬取到資訊就好比要喝一碗湯,喝到湯就需要原料并且將其烹飪,requests為我們提供原料,beautifulsoup為我們烹飪,在烹飪后的美味湯中我們得以取到有價值的資訊,
2.代碼段的解釋
(1)requests代碼段的解釋
#引入庫
import requests
from bs4 import BeautifulSoup
#首先我們要進行偽造,將user-agent改成瀏覽器的,很多網站對python默認的user-agent很敏感,不改是大概率行不通的
#要是還行不通大家就改一下一下requests的其他post屬性吧
kv={'user-agent':'Mozilla/5.0'}
#開始請求回應,并將回應的資訊賦予給r
r=requests.get('https://movie.douban.com/top250',headers=kv)
#如果回應為200,便證明我們的回應成功,要是其他數字,那就自求多福咯~有興趣的伙伴可以去網上查HTTP協議,里面有關于回應代碼的詳解
if (r.status_code==200):
#下面不必看,我稍后在解釋!下面不必看,我稍后在解釋!下面不必看,我稍后在解釋!
# source=r.text
# soup = BeautifulSoup(source,'html.parser')
# items=soup.find_all('div','item')
# for i in items:
# for j in range(len(i.find_all('span','title'))):
# print(i.find_all('span','title')[j].string,end='')
# print(i.find_all('span','other')[0].string)
# print(i.find_all('p')[0].text)
# print('評語:'+i.find_all('span','inq')[0].string)
# print('評分:'+i.find_all(property="v:average")[0].string)
# print("\n")
#上面不必看,我稍后在解釋!上面不必看,我稍后在解釋!上面不必看,我稍后在解釋!
else:#其他回應表明服務器可能有些不太樂意回應你
print("哦豁~目標網站不給予回應")(2)beautifulsoup代碼段的解釋
#import requests
#from bs4 import BeautifulSoup
#kv={'user-agent':'Mozilla/5.0'}
#r=requests.get('https://movie.douban.com/top250',headers=kv)
#現在咱們介紹回應成功的情況
if (r.status_code==200):
#既然回應成功,就說明r已經得到了回應的資訊,這里我們將資訊中的源代碼(r.text)賦予給source,以它為原料進行煲湯
source=r.text
#將源代碼依照html.parser方法進行規格化
soup = BeautifulSoup(source,'html.parser')
#用find_all方法到資訊所在標簽,并以串列形式回傳,
#這里的items包含著當前網頁的電影項,
items=soup.find_all('div','item')
#用i遍歷items中每一項電影
for i in items:
#電影的標題
for j in range(len(i.find_all('span','title'))):
print(i.find_all('span','title')[j].string,end='')
#電影的其他資訊
print(i.find_all('span','other')[0].string)
#text不管標簽中有多少子標簽都會輸出全部字符
#但是string在包含有多個標簽的時候會不知所措,回傳空值
print(i.find_all('p')[0].text)
#電影的引言
if(len(i.find_all('span','inq'))!=0):#防止有的電影沒有引言
print('評語:'+i.find_all('span','inq')[0].string)
#電影的評分
print('評分:'+i.find_all(property="v:average")[0].string)
print("\n")
#else:
print("哦豁~目標網站不給予回應")(3)整個代碼段的解釋
import requests
from bs4 import BeautifulSoup
#改變請求代理為瀏覽器,
kv={'user-agent':'Mozilla/5.0'}
page=0#網頁起始頁數
while (page<=250):#遍歷多個網頁
r=requests.get('https://movie.douban.com/top250?start='+str(page)+'&filter=',headers=kv)
page=page+25#以25為頁面跨度
if (r.status_code==200):
將r.text進行規格化以便遍歷
source=r.text#
soup = BeautifulSoup(source,'html.parser')
#開始遍歷所有電影
items=soup.find_all('div','item')
#在每一個電影中搜查資訊
for i in items:
for j in range(len(i.find_all('span','title'))):
print(i.find_all('span','title')[j].string,end='')
print(i.find_all('span','other')[0].string)
print(i.find_all('p')[0].text)
if(len(i.find_all('span','inq'))!=0):#電影沒引言就跳過
print('評語:'+i.find_all('span','inq')[0].string)
print('評分:'+i.find_all(property="v:average")[0].string)
print("\n")
else:
print("哦豁~目標網站不給予回應")
print('OVER~')三、總結
爬多了也會對服務器造成負擔的,大家實驗一下就好,不宜多爬,文章寫的啰嗦了,而且代碼的輸出不夠美觀,還請各位就一笑而過吧,有錯誤的話懟我就成~
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/341889.html
標籤:python