兄弟們,我來了!
在CSDN抽盲盒中了一個iPhone 13 可還行,這運氣感覺我應該去買個彩票,哎舒服了!
詳細截圖都在這篇文章了,點我閱讀

先不嘚瑟了,我們今天來爬一下本地的房源資訊,不知道我有生之年能不能買的起~
一、準備作業
本文有點長,如果不習慣看文章的話,也有專門的視頻講解,灰常詳細!
Python:爬取本地房源資訊,分析價格走勢,好讓自己死心!
重要的知識點
1. 系統分析網頁性質
2. 結構化的資料決議
3. csv資料保存
使用的環境
Python3.8
pycharm專業版
使用的模塊
requests
parsel
csv
不會安裝模塊的兄弟可以看我發的這篇:如何安裝python模塊, python模塊安裝失敗的原因以及解決辦法
基本思路流程
一、資料來源分析
爬蟲: 對于網頁上面的資料內容進行采集程式
- 確定爬取的內容是什么東西?
二手房源的基本資料 - 通過開發者工具進行抓包分析, 分析這些資料內容是可以哪里獲取,
通過開發者工具, 分析可得 >>> 我們想要的房源資料內容(房源詳情頁url) 就是來自于網頁源代碼,
如果你要爬取多個房源資料, 只需要在串列頁面 獲取所有的房源詳情頁url,
二、代碼實作步驟
發送請求 >>> 獲取資料 >>> 決議資料 >>> 保存資料
- 發送請求, 是對于房源串列頁發送請求
- 獲取資料
- 決議資料, 提取我們想要的內容, 房源詳情頁url,
- 發送請求, 對于房源詳情頁url地址發送請求,
- 獲取資料
- 決議資料, 提取房源基本資訊、售價、標題、單價、面積、戶型,
- 保存資料
- 多頁資料采集
大概思路就這些,咱們一步步來實作吧,
二、資料來源分析
首先要確定我們爬的是什么,我們今天爬的是鏈家的一個二手房房源資訊,比如說價格、大小、樓層、戶型等等一些基本資訊,這些情況都是要我們去采集的,
既然我們知道了需要這些資料,那么我們就要通過開發者工具去抓包分析,分析這些資料可以從哪里獲取,
開發者工具的話可以F12或者按住滑鼠右鍵點擊檢查都可以打開
 然后再選擇network
然后再選擇network
 剛開始打開的時候是沒有任何資料的,所以我們要重繪一下當前頁面,就會出來很多資料,
剛開始打開的時候是沒有任何資料的,所以我們要重繪一下當前頁面,就會出來很多資料,
 但是這些資料并不是我想要的,那么怎么找到自己想要的資料呢?
但是這些資料并不是我想要的,那么怎么找到自己想要的資料呢?
比如說我想要這個房子的標題,
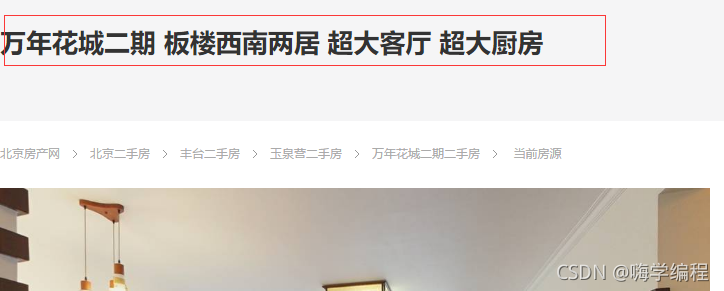
那在這么多的資料里面我們要去哪里找呢?
以谷歌瀏覽器為例,這時候我們就可以用到開發者工具的一個搜索功能,
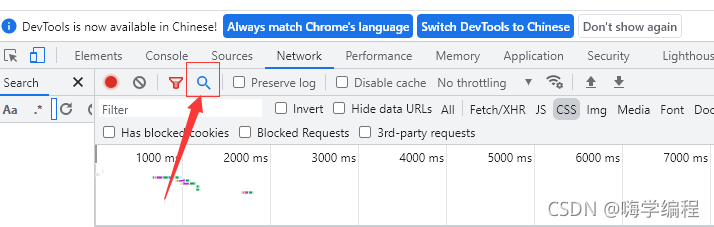
這個搜索功能就可以對我們想要的資料進行搜索,然后它就會給我們回傳相對應的資料內容(資料包),
這里以房子名字為例
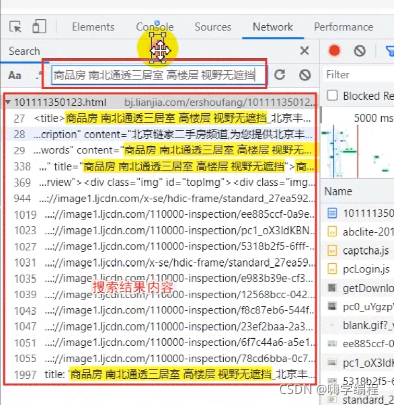 點擊第一個,它就會在右邊給我們彈出一個response下面的內容,response是服務器回傳給我們的一個回應資料,
點擊第一個,它就會在右邊給我們彈出一個response下面的內容,response是服務器回傳給我們的一個回應資料,
比如title標簽里面就有我們想要的內容,房源的名字,
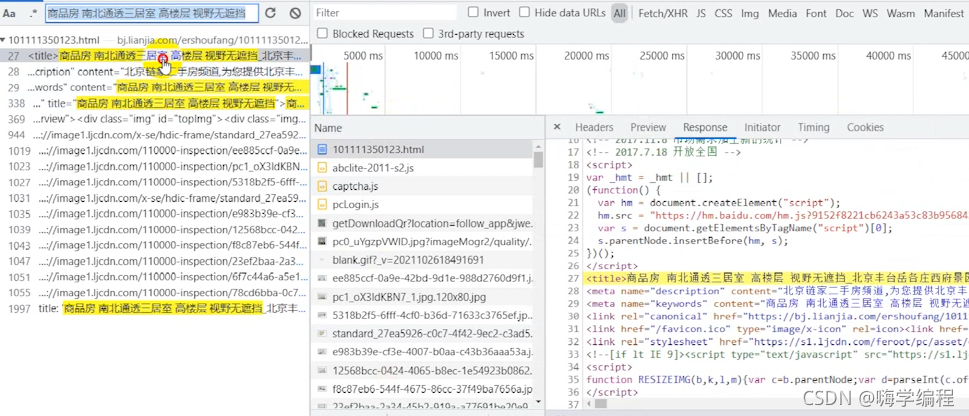 所以這里我們點擊preview,這個是預覽的意思,基本上資料都能在預覽中看到,
所以這里我們點擊preview,這個是預覽的意思,基本上資料都能在預覽中看到,
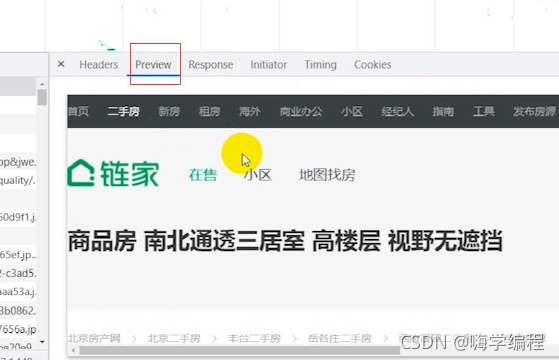
確定了資料都有的話,我們就點擊headers ,這個Request URL 就是我們等下需要發送的請求url,這個url地址的話,跟咱們的網頁地址是一樣的,
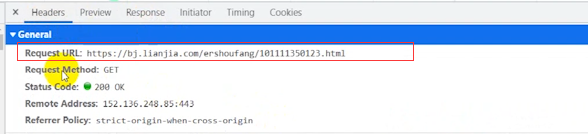
這個get是我們的請求方式,如果它這個地方顯示的是一個post方式,咱們就用post,
它說的是什么方式,咱們就用什么方式,而不是咱們想用什么方式就用什么方式,

get和post的區別
get一個是獲取資料,post一個是傳送資料,
get請求一般情況下只是從服務器獲取資料,并不會對服務器資源產生任何影響,
post請求是我們向服務器發送資料,比如說登錄、上傳、搜索,這種對服務器資源產生影響的時候使用,
在瀏覽器網址顯示的,問號后面的內容都是屬于get請求的引數,post請求的話一般都是隱藏的,所以要通過開發者工具才能看到引數,
三、代碼實作步驟
1、發送請求
咱們回到正題
發送請求的話首先匯入我們要的模塊
import requests
這是我們的資料請求模塊,也是一個第三方模塊,大家應該都安裝了吧,開局就說了的,
然后我們發送請求的url地址確定后就直接復制過來
url = 'https://bj.lianjia.com/ershoufang/'
然后我們要加上一個請求頭,把我們的Python代碼進行偽裝,偽裝成瀏覽器對服務器發送請求,就是模擬瀏覽器,
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.54 Safari/537.36'
}
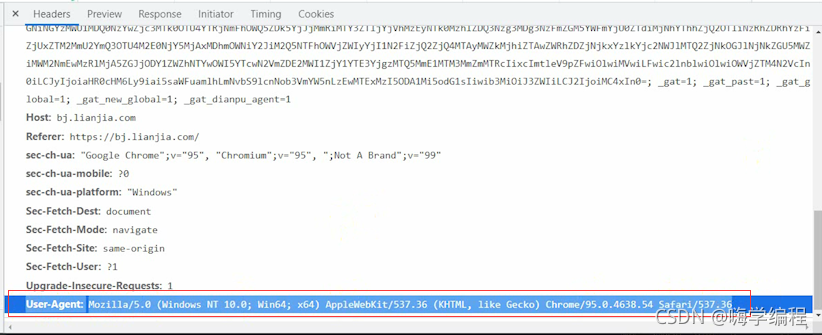
headers引數的話都在這里找,當然內容太多了,咱們沒必要都加進去,所以只要User-Agent里面的內容就好了,
 User-Agent主要表示的是瀏覽器的基本資訊,身份標識,
User-Agent主要表示的是瀏覽器的基本資訊,身份標識,
 然后咱們發送請求用requests模塊里面的get請求方式把url地址和headers請求頭給傳進去,
然后咱們發送請求用requests模塊里面的get請求方式把url地址和headers請求頭給傳進去,
然后我們用response變數接收一下
response = requests.get(url=url, headers=headers)
print(response)
然后直接運行
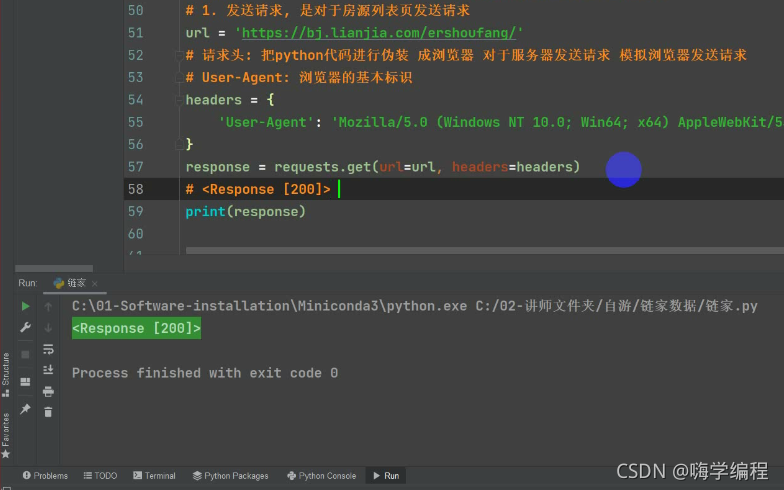 這里回傳的是response [200]>
這里回傳的是response [200]>
它是回應體的一個物件
200 是一個狀態碼,表示請求成功,說明咱們對網站的發送請求沒有問題了,
那么為什么回傳的不是資料,而是response [200]>呢?
2、獲取資料
這時候咱們就要獲取文本資料了,列印的時候在response后面加上text,獲取回應體的文本資料,這樣子咱們才能獲取到跟網頁源代碼一樣的資料了,
print(response.text)
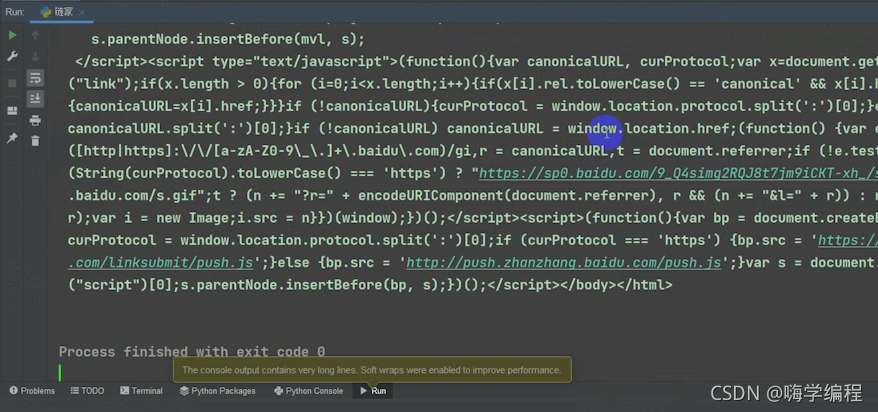 很多人覺得編程難,這其實不難,現在兩步實作了,才五行代碼,而且基本上都是復制粘貼的,多試幾遍不就記住了,對吧,
很多人覺得編程難,這其實不難,現在兩步實作了,才五行代碼,而且基本上都是復制粘貼的,多試幾遍不就記住了,對吧,
3、決議資料
提取我們想要的內容, 房源詳情頁url,
首先匯入咱們的資料決議模塊
import parsel
我們獲取到的response.text ,它是一個html字串資料內容,如果你想要對于字串資料內容直接決議提取的話,只能用re正則運算式,
但是咱們今天是用的parsel模塊,所以我們要對我們獲取到的HTML字串內容進行轉換,轉成Selector方法,然后response.text給它傳進去,
然后用Selector變數接收一下,列印看看是個啥
print(Selector)
它這里回傳的就是一個Selector物件
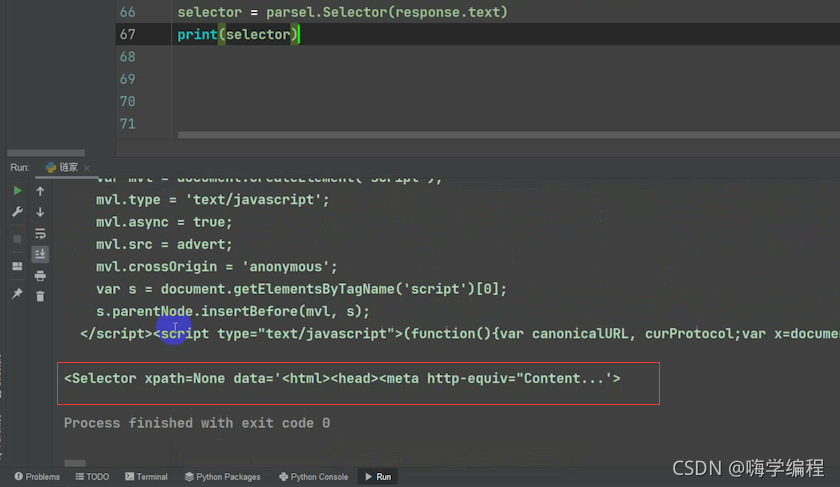 那這個物件里面我們就可以呼叫它相對應的一些方法, 我們今天呼叫的是一個css的選擇器,
那這個物件里面我們就可以呼叫它相對應的一些方法, 我們今天呼叫的是一個css的選擇器,
css選擇器是一個決議方法,根據標簽屬性內容提取相關的資料,
selector.css('')
首先點擊開發者工具上的那個箭頭,點擊我們想要的東西,
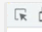
我們想要的是這個url地址
 如果我們不會css語法,就直接選中這里
如果我們不會css語法,就直接選中這里
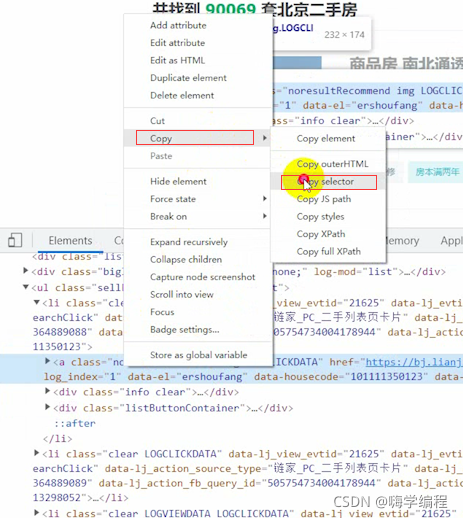 最后可以直接定位到這里
最后可以直接定位到這里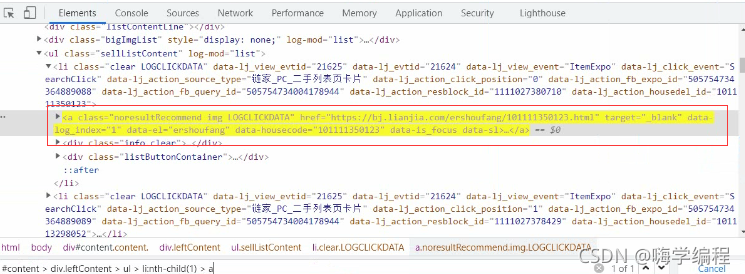 但是這里顯示的是只給我們獲取一個,咱們是要獲取所有的怎么辦呢?
但是這里顯示的是只給我們獲取一個,咱們是要獲取所有的怎么辦呢?
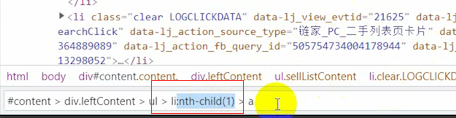
它這個地方顯示的是一個1,意思就是只取它第一個li標簽,咱們直接把它刪了就好了,這樣子就取到31個了,

31個也不對,一頁總共就30頁資料,那么問題出在這個地方,
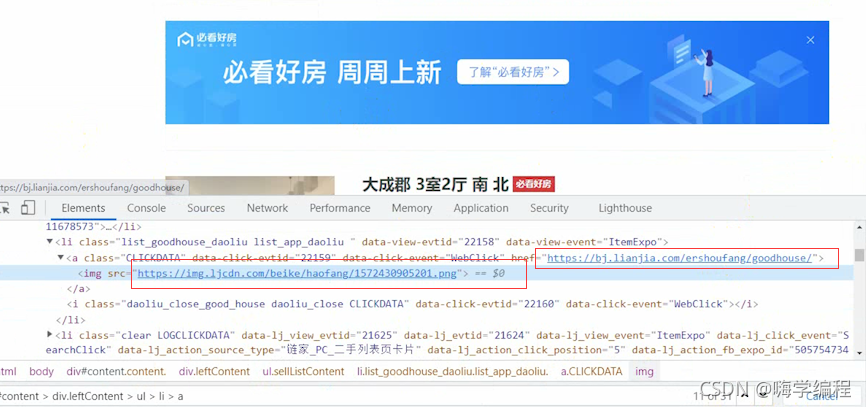 它給我整了一手廣告,就過份!
它給我整了一手廣告,就過份!
但是它這個不是我們想要的,它也給我們取到了,怎么去掉呢?
我們想要的資料都是在li標簽里面,它們唯一不同的話就是clear屬性這個地方,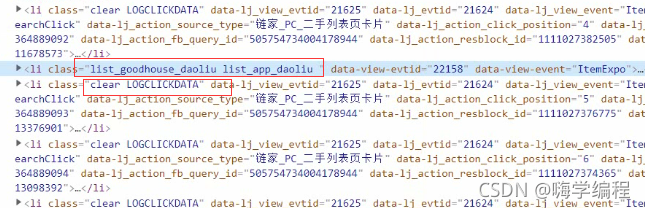 咱們直接把它改一下,根據標簽屬性去取,把不要的過濾掉,
咱們直接把它改一下,根據標簽屬性去取,把不要的過濾掉,
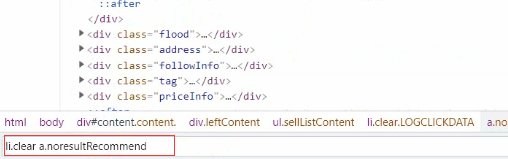
然后再取href接收,列印一下看看
href = selector.css('li.clear a.noresultRecommend::attr(href)').getall()
print(href)
 列印之后,就給我們獲取到了所有的房源詳情頁url地址,
列印之后,就給我們獲取到了所有的房源詳情頁url地址,
那么接下來我們就要給它遍歷一下,讓它把里面的資料都給它一一提取出來,
然后運行一下
href = selector.css('li.clear a.noresultRecommend::attr(href)').getall()
for index in href:
print(href)
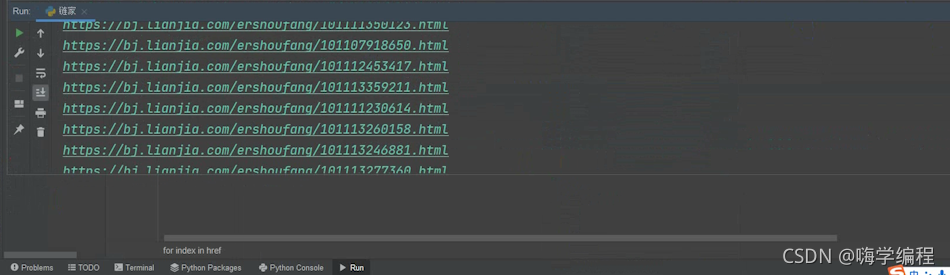 這樣的話,我們就把它所有的一個url地址都獲取下來了,
這樣的話,我們就把它所有的一個url地址都獲取下來了,
4、發送請求
然后就要對我們的詳情頁發送請求
這些的話跟前面的方法都是一樣的,就不詳細去說了,
response_1 = requests.get(url=index, headers=headers)
5、獲取資料
6、 決議資料
接下來的話就取他的一個內容
selector_1 = parsel.Selector(response_1.text)
還是跟剛剛一樣的,去找到它的詳細資訊
取標題
```powershell
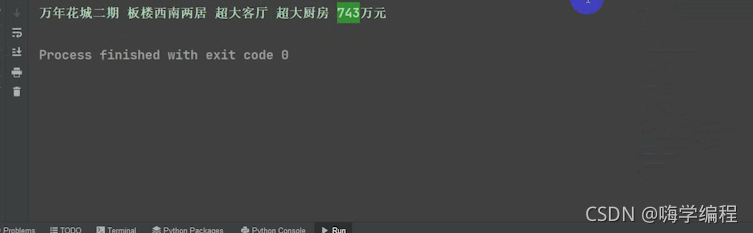
title = selector_1.css('div.title .main::text').get()
取價格
price = selector_1.css('.price .total::text').get() + '萬元'
列印一下看看
print(title,price)
 然后其它的標簽也是差不多的,我就直接給代碼,不一一說了,
然后其它的標簽也是差不多的,我就直接給代碼,不一一說了,
area = selector_1.css('.areaName .info a:nth-child(1)::text').get() # 區域
community_name = selector_1.css('.communityName .info::text').get() # 小區
room = selector_1.css('.room .mainInfo::text').get() # 戶型
room_type = selector_1.css('.type .mainInfo::text').get() # 朝向
height = selector_1.css('.room .subInfo::text').get() # 樓層
height = re.findall('共(\d+)層', height)[0]
sub_info = selector_1.css('.type .subInfo::text').get().split('/')[-1] # 裝修
Elevator = selector_1.css('.content li:nth-child(12)::text').get() + '電梯' # 電梯
if Elevator == '暫無資料電梯':
Elevator = '無電梯'
house_area = selector_1.css('.content li:nth-child(3)::text').get().replace('㎡', '') # 面積
price = selector_1.css('.price .total::text').get() # 價格(萬元)
date = selector_1.css('.area .subInfo::text').get().replace('年建', '') # 年份
dit = {
'市區': area,
'小區': community_name,
'戶型': room,
'朝向': room_type,
'樓層': height,
'裝修情況': sub_info,
'電梯': Elevator,
'面積(㎡)': house_area,
'價格(萬元)': price,
'年份': date,
'詳情頁': index,
}
print(area, community_name, room, room_type, height, sub_info, Elevator, house_area, price, date, index, sep='|')
運行結果
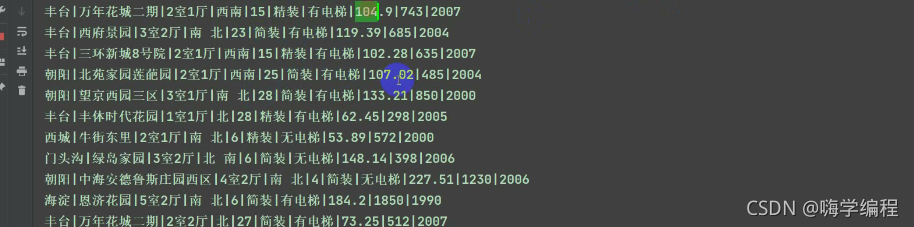 七七八八的資料咱們都獲取下來了,
七七八八的資料咱們都獲取下來了,
7、保存資料
首先我們匯入CSV資料保存模塊
import csv
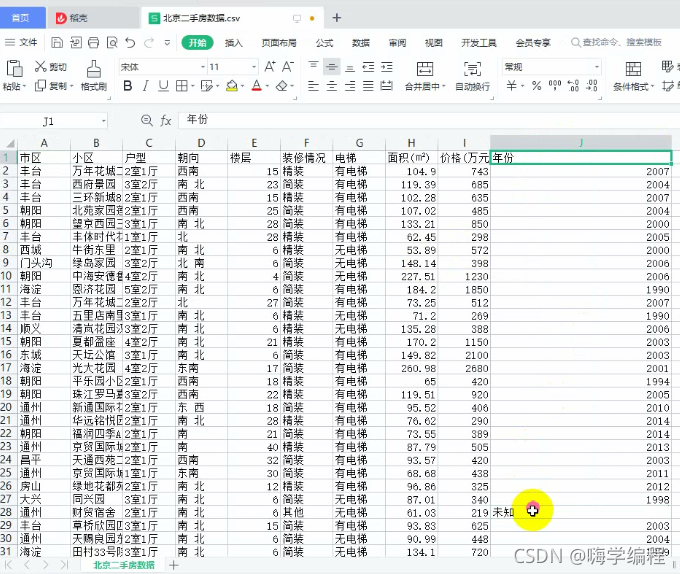
然后opn創建一個檔案,表格規則設計好,
取名北京二手房資料.csv,mode保存方式 a ,追加保存,
encoding編碼utf-8,newline新起一行,
f = open('北京二手房資料.csv', mode='a', encoding='utf-8', newline='')
然后用CSV模塊里面的DictWriter方法把f, fieldnames傳進去,fieldnames是寫入字典里面的內容,
把那些標簽名字后面的都給它替換成逗號,用csv_writer給它接收一下,最后用寫入表頭,
csv_writer = csv.DictWriter(f, fieldnames=[
'市區',
'小區',
'戶型',
'朝向',
'樓層',
'裝修情況',
'電梯',
'面積(㎡)',
'價格(萬元)',
'年份',
'詳情頁'
])
csv_writer.writeheader() # 寫入表頭
運行結果
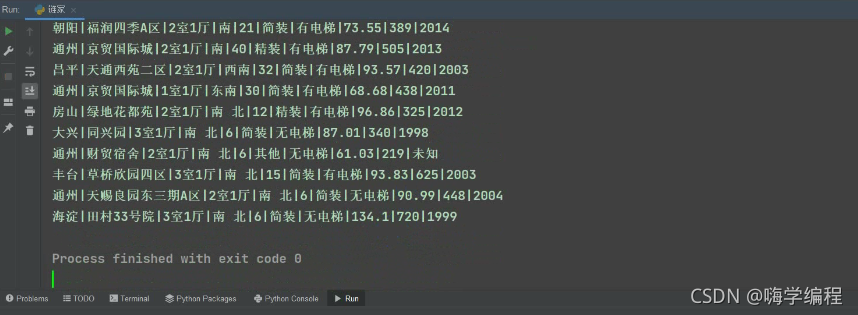 這個時候就當前頁的內容都爬完了,當前只是挑選了一些,其它的七七八八的大家也可以自己爬一下,
這個時候就當前頁的內容都爬完了,當前只是挑選了一些,其它的七七八八的大家也可以自己爬一下,
8、多頁資料采集
多頁其實很簡單,我們翻到第二頁,這里是個pg2,翻到第三頁就是pg3,

那就只要改這個就好了,我們加一個for回圈,想爬多少頁就改多少,我們這里爬到11頁,
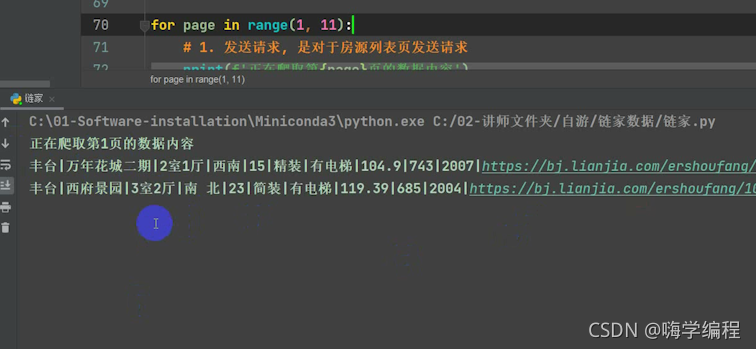
for page in range(1, 11):
然后把這個page傳進去,不然永遠在爬第一頁,
url = f'https://bj.lianjia.com/ershoufang/pg{page}/'
然后再加一行,正在爬取多少頁,
print(f'正在爬取第{page}頁的資料內容')
運行結果
 到這里的話就結束了,大家可以去試試,
到這里的話就結束了,大家可以去試試,
這次的有點長,不知道有多少堅持看完的,兄弟們學廢了嗎?
記得點贊三連啊啊啊!

轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/341890.html
標籤:python
上一篇:Python爬取電影排行TOP250(beautifulsoup+requests)
下一篇:Mongodb 使用