我有一個情節圖表,我試圖將推文添加到懸停資訊中。
資料幀本身包含 7000 多行(每小時加密讀數)和 139 條推文,標記為content. 其中content,有 ~6861 行“NaN”,因為content總共有 139 條推文。
我在下面的代碼
fig = px.line(total_data, x = total_data.date,
y = total_data.doge_close)
fig.add_trace(
go.Scatter(
x=total_data[total_data.has_tweet==1].date,
y=total_data[total_data.has_tweet == 1['doge_close'],
mode = 'markers',
hovertemplate =
'<i>tweet:</i>' '<br>'
'<i>%{text}</i>',
text = [t for t in total_data['content']],
name = 'has_tweets'))
fig.show()
產生這個情節:
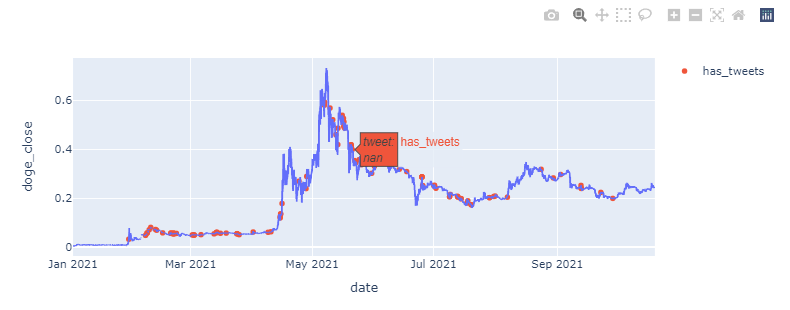
它說的地方NaN,我想要當時推文的實際內容。
“內容”列可以用下面的代碼松散地復制:
df = px.data.stocks().set_index('date')[['GOOG']].rename(columns={'GOOG':'values'})
df['has_tweet'] = df['tweet'].apply(lambda x: 0 if x != x else 1)
df['tweet'] = random.choices(['A tweet','Longer tweet', 'emoji','NaN'], weights=(5,10,5,80), k=len(df))
并且可以使用以下代碼進行一般復制:
import plotly.express as px
import plotly.graph_objects as go
import random
fig = px.line(df, x=df.index, y = 'values')
fig.add_trace(go.Scatter(x=df[df.has_tweet==1].index,
y = df[df.has_tweet==1]['values'],
mode = 'markers',
hovertemplate =
'<i>tweet:</i>' '<br>'
'<i>%{text}</i>',
text = [t for t in df['tweet']],
name = 'has_tweets'))
fig.show()
有沒有辦法從資料框中過濾掉“NaN”以輸入實際的推文內容?
使用解決方案進行編輯
感謝一位非常友好的評論者,我已經找到了解決方案并將其附在下面,以供將來的任何人使用。
fig = px.line(total_data, x = total_data.date, y = total_data.doge_close)
fig.add_trace(go.Scatter(x=total_data[total_data.has_tweet==1].date,
y=total_data[total_data.has_tweet==1]['doge_close'],
mode = 'markers',
hovertemplate =
'<i>tweet:</i>' '<br>'
'<i>%{text}</i>',
text = [t for t in total_data.loc[total_data['has_tweet']==1, 'content']],
name = 'has_tweets'))
fig.show()
它產生: 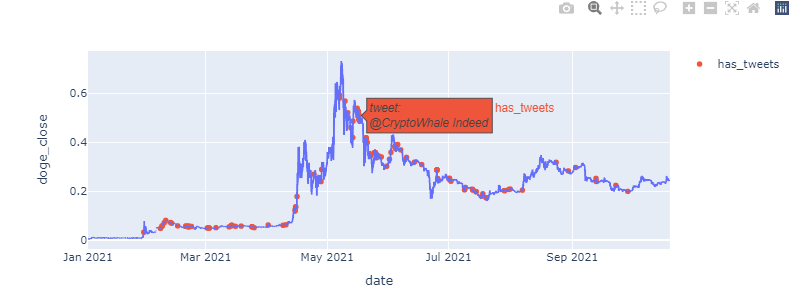
uj5u.com熱心網友回復:
根據您的評論,不是將 0 或 1 隨機分配給該"has_tweet"列,而是應根據“推文”列是否為 0 或 1 NaN。也不是我使用的字串“NaN” np.nan,但這可能需要根據您的實際資料進行修改。
我們可以像這樣創建一些類似于您的資料:
import numpy as np
import plotly.express as px
import plotly.graph_objects as go
import random
random.seed(42)
df = px.data.stocks().set_index('date')[['GOOG']].rename(columns={'GOOG':'values'})
df['tweet'] = random.choices(['A tweet','Longer tweet', 'emoji',np.nan], weights=(5,10,5,80), k=len(df))
df['has_tweet'] = df['tweet'].apply(lambda x: 0 if x != x else 1)
然后我相信我們需要做的唯一改變就是將帶有推文的行傳遞給 text 引數:
fig = px.line(df, x=df.index, y = 'values')
fig.add_trace(go.Scatter(x=df[df.has_tweet==1].index,
y = df.loc[df.has_tweet==1]['values'],
mode = 'markers',
hovertemplate =
'<i>tweet:</i>' '<br>'
'<i>%{text}</i>',
text = [t for t in df.loc[df.has_tweet==1, 'tweet']],
name = 'has_tweets'))
fig.show()
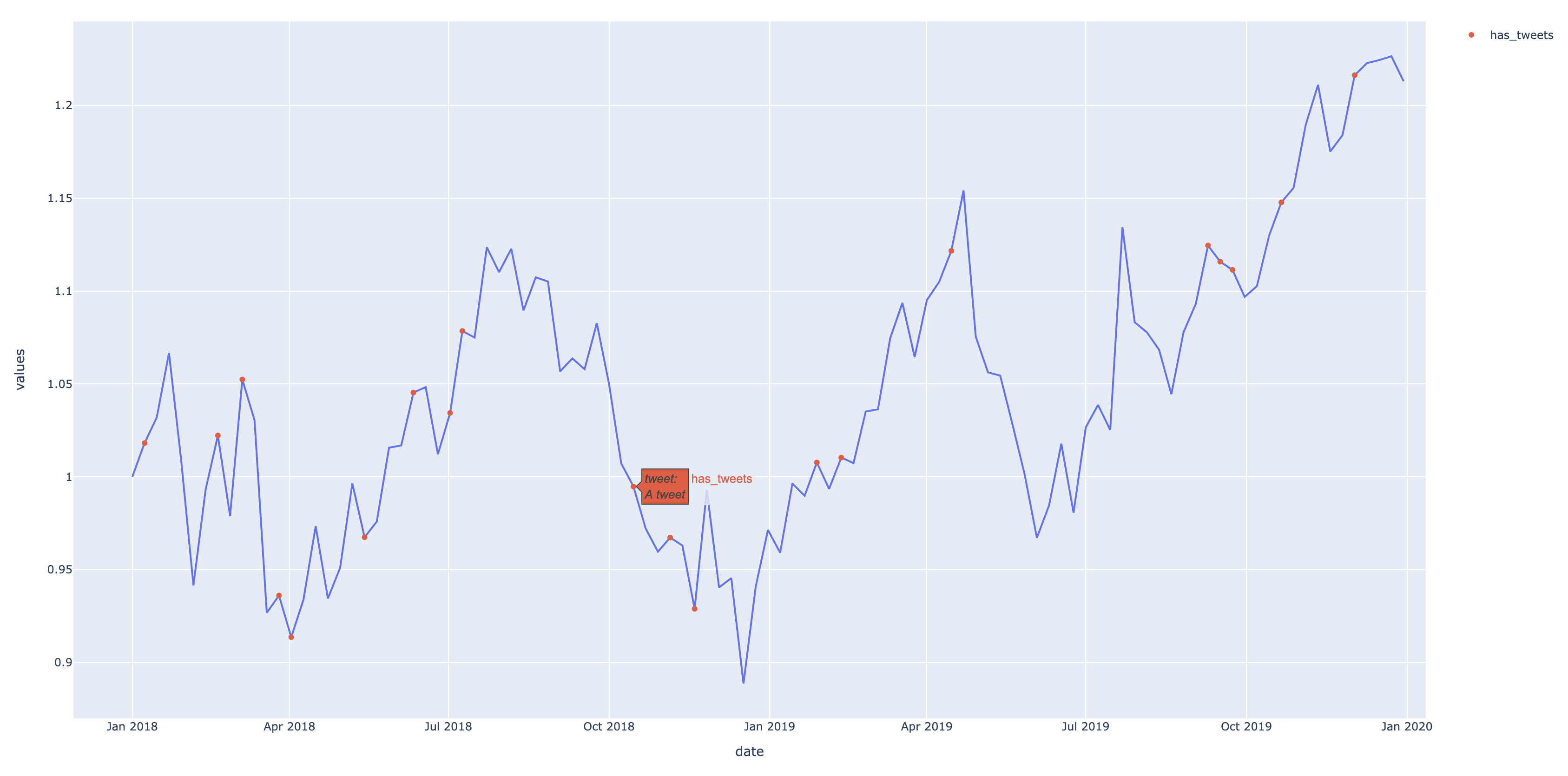
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/355469.html