雖然是20年寫的,但最近改了改還能用,
?怎么還審核不通過,刪了些圖片,加了個代碼,
專案地址:
https://github.com/stay-leave/CNKI-selenium-crawler
配置:
本專案使用selenium模塊,瀏覽器使用的是火狐,
1.下載geckodriver,地址https://github.com/mozilla/geckodriver/releases
2.將適配的安裝包放置在火狐瀏覽器的安裝路徑、Python的Stricpts檔案夾
3.將火狐的安裝路徑添加到電腦環境變數的用戶變數的path中,
功能:
1.社科基金專案資料爬取
代碼樣例:
#coding='utf-8'
import requests
import re
import xlwt
headers = {
'Accept-Encoding': 'gzip, deflate, sdch',
'Accept-Language': 'en-US,en;q=0.8',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Referer': 'https://www.baidu.com/',
'Connection': 'keep-alive',
}
url_1='http://fz.people.com.cn/skygb/sk/index.php/index/seach/'
url_2='?pznum=&xmtype=0&xktype=%E5%9B%BE%E4%B9%A6%E9%A6%86%E3%80%81%E6%83%85%E6%8A%A5%E4%B8%8E%E6%96%87%E7%8C%AE%E5%AD%A6&xmname=&lxtime=0&xmleader=&zyzw=0&gzdw=&dwtype=0&szdq=0&ssxt=0&cgname=&cgxs=0&cglevel=0&jxdata=0&jxnum=&cbs=&cbdate=0&zz=&hj='
url_0=list(range(1,3))#生成一個1到93的數字串列
urls=[]#網址串列
def require(url):
"""獲取網頁原始碼
"""
response = requests.get(url, headers=headers)
print(response.status_code)#狀態碼
print(response.encoding)#首選編碼
'''print(response.apparent_encoding)#備選編碼'''
#response.encoding=response.apparent_encoding
html=response.text#源代碼文本
return html
def cut(list,n):
"""將串列按特定數量切分成小串列"""
for i in range(0,len(list),n):
yield list[i:i+n]
for i in url_0:
i=url_1+str(i)+url_2
urls.append(i)
def get_infor(one_url):
'''進入一個頁面,獲取該頁面的資訊,回傳串列的串列all'''
html=require(one_url)
result_1=re.findall('<table width="100%" border="0" cellpadding="0" cellspacing="0">(.*?)</table>',html,re.S)#進入table
result_2=re.findall(' <tr>(.*?)</tr>',str(result_1),re.S)#找到所有tr標簽
#專案編號、立項時間、專案負責人、所屬系統
i_1=re.findall('<td width="90">(.*?)</td>',str(result_2),re.S)#找到所有td width=90的標簽,得出四種不同的屬性,專案編號、立項時間、專案負責人、所屬系統
i_2=re.findall('<span title.*?>(.*?)</span>',str(i_1),re.S)#取出字符,i_2是一個串列
#專案類別、學科分類、專業職務
i_3=re.findall('<td width="70">(.*?)</td>',str(result_2),re.S)#找到所有td width=70的標簽,得出三種不同的屬性,專案類別、學科分類、專業職務
i_4=re.findall('<span title.*?>(.*?)</span>',str(i_3),re.S)#取出字符
#專案名稱
i_5=re.findall('<td width="320"><span.*?>(.*?)</span></td>',str(result_2),re.S)#找到所有td width=320的標簽,得出專案名稱
#作業單位
i_6=re.findall('<td width="150"><span.*?>(.*?)</span></td>',str(result_2),re.S)#找到所有td width=150的標簽,得出作業單位
#單位類別
i_7=re.findall('<td width="80"><span.*?>(.*?)</span></td>',str(result_2),re.S)#找到所有td width=80的標簽,得出單位類別
#所在地
i_8=re.findall('<td width="100"><span.*?>(.*?)</span></td>',str(result_2),re.S)#找到所有td width=100的標簽,得出所在省市區
l_1=[]
l_2=[]
for i in cut(i_2,4):#四種屬性的值串列
l_1.append(i)
for i in cut(i_4,3):#三種屬性的值串列
l_2.append(i)
all=[]#總的結果
#串列拼接
for i in range(len(i_8)):
all.append(l_1[i]+l_2[i]+i_5[i:i+1]+i_6[i:i+1]+i_7[i:i+1]+i_8[i:i+1])
return all
"""保存為excel"""
f=xlwt.Workbook()
sheet1=f.add_sheet(u'sheet1',cell_overwrite_ok=True)
sheet1.write(0,0,'專案編號')
sheet1.write(0,1,'立項時間')
sheet1.write(0,2,'專案負責人')
sheet1.write(0,3,'所屬系統')
sheet1.write(0,4,'專案類別')
sheet1.write(0,5,'學科分類')
sheet1.write(0,6,'專業職務')
sheet1.write(0,7,'專案名稱')
sheet1.write(0,8,'作業單位')
sheet1.write(0,9,'單位類別')
sheet1.write(0,10,'所在地')
i=1
alls=[]
for one_url in urls:
alls.append(get_infor(one_url))#全部頁的資料分為一個93個子串列的串列
for all in alls:#遍歷每一頁
for data in all:#遍歷每一行
for j in range(len(data)):#取每一單元格
sheet1.write(i,j,data[j])#寫入單元格
i=i+1#往下一行
f.save('測驗檔案.xls')
#保存所有
2.論文的元資料爬取
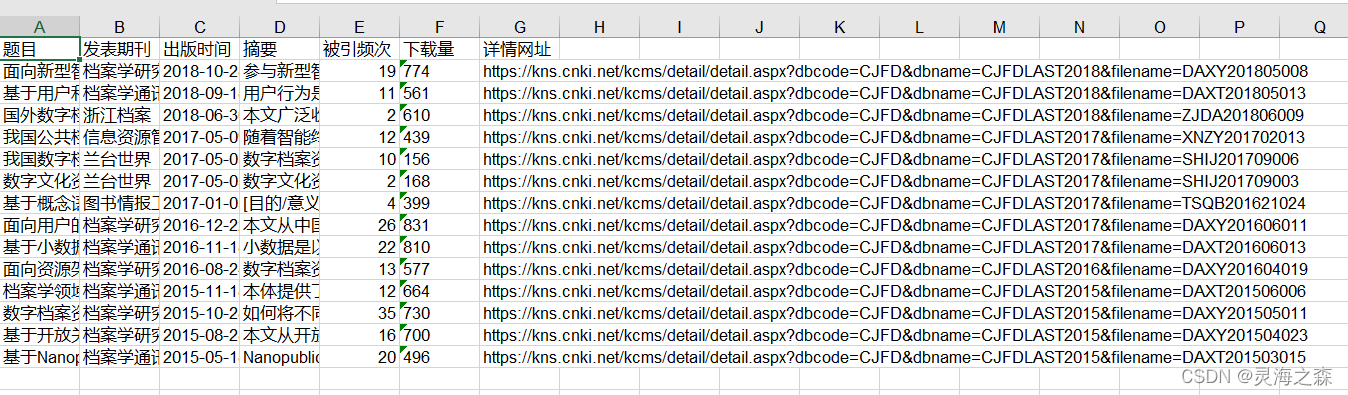 由于我在學習中是將關鍵詞按年份聚類的,所以沒有對單個論文的關鍵詞作分隔,都是一個基金的所有產出論文的,可以在原始碼中修改,
由于我在學習中是將關鍵詞按年份聚類的,所以沒有對單個論文的關鍵詞作分隔,都是一個基金的所有產出論文的,可以在原始碼中修改,
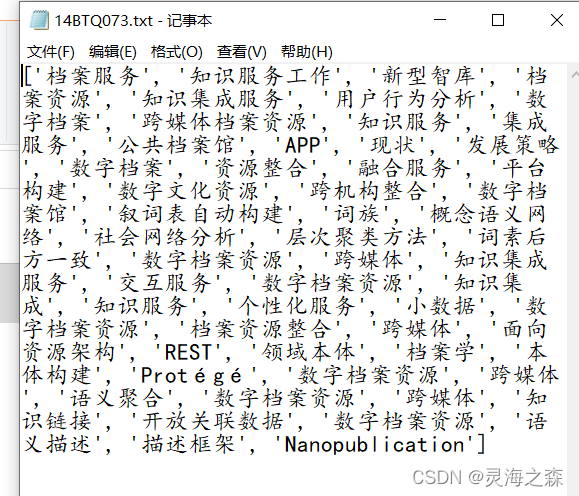
3.論文的參考和引證的期刊文獻爬取
注意事項:
1.任意網路均適用,不需要購買知網,
2.可以按原始代碼從社科基金專案開始直到產出論文的參考、引證文獻的爬取,
3.爬取速度可以調節,修改程式里的t.sleep()中的數值即可,建議1到6之間,可以采用random隨機,
4.論文元資料爬取需要嚴格按照三個程式的順序,即題名等、被引數等、論文地址,
5.所有結果均以excel方式保存,注意看檔案路徑,本專案中基金號為主鍵,
6.僅作學習使用,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/402739.html
標籤:python
上一篇:synchronized和volatile關鍵字實作和底層原理詳解
下一篇:爬蟲筆記3