目錄
一,Requests庫練習
1,用百度 360 搜索關鍵字
2,圖片爬取并保存本地
二,網路爬蟲之資訊提取——Beautiful soup庫學習
1,安裝Beautiful soup
2,運用Beautiful soup獲取源代碼
3, beautifulsoup使用格式
4,beautiful的基本使用元素
? beatiful soup庫 決議器
beautiful soup類基本元素
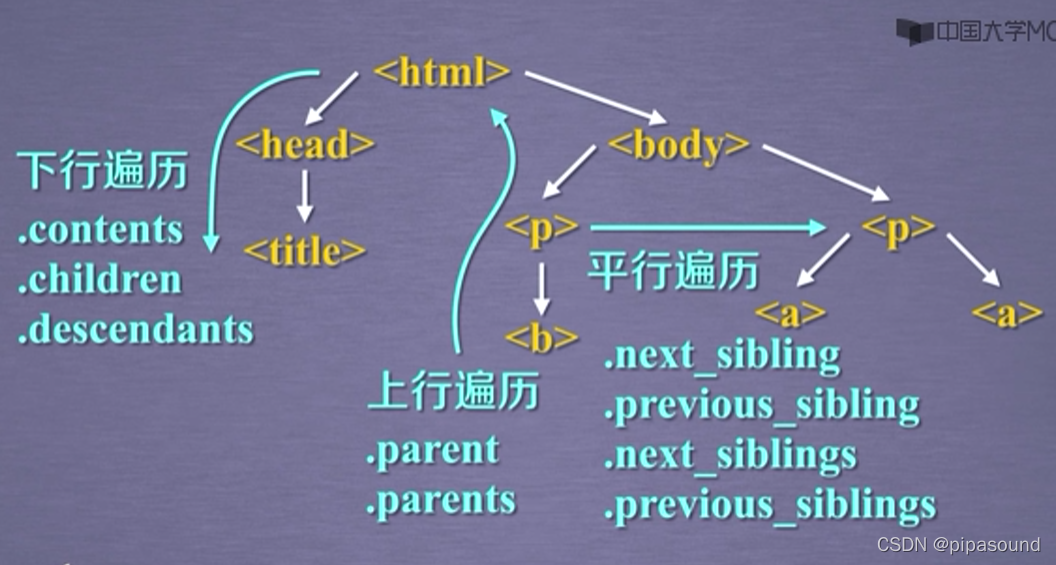
5,基于bs4庫的HTML內容遍歷方法
標簽樹的下行遍歷
? 標簽樹的上行遍歷?
標簽樹的平行遍歷
總結
? 6,基于bs4庫的HTML格式輸出
一,Requests庫練習
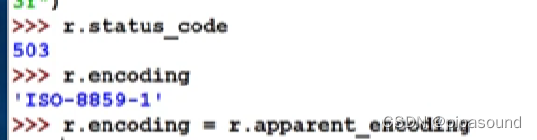
- raise_for_status():若在回傳的代碼是200的情況下,是不會產生例外,否則產生例外
- 每次爬取前檢查能否訪問
1,用百度 360 搜索關鍵字
- 百度關鍵詞搜索 http://www.baidu.com/s?wd=keyword
- 360關鍵字搜索 http://www.so.com/s?q=keyword
import requests
kv={'wd':'Python'}
r=requests.get("http://www.baidu.com/s",params=kv)
r.status_code
>>>200
r.request.url
>>>'http://www.baidu.com/s?wd=Python'
print(r.request.url)
>>>http://www.baidu.com/s?wd=Python
print(r.text[1000:2000])
當鏈接回傳的非常多的時候,r.text可能會導致idle失效,所以盡量約束一個范圍空間
2,圖片爬取并保存本地
-
要考慮一切可能會發生的情況
import requests
import os
root = 'E://pictures//'
url = 'https://cj.jj20.com/2020/down.html?picurl=/up/allimg/tp03/1Z9211U233AA-0.jpg'
path = root+url.split('/')[-1]
try:
if not os.path.exists(root):
os.mkdir(root)
if not os.path.exists(path):
r = requests.get(url=url)
with open(path, 'wb') as f:
f.write(r.content)
f.close()
print("該檔案保存成功")
else:
print('檔案已存在')
except:
print("爬取失敗")二,網路爬蟲之資訊提取——Beautiful soup庫學習
1,安裝Beautiful soup
pip install beautifulsoup4
用來決議html和xml檔案的功能庫
2,運用Beautiful soup獲取源代碼
from bs4 import BeautifulSoup
import requests
r = requests.get("http://python123.io/ws/demo.html")
demo = r.text
soup = BeautifulSoup(demo, 'html.parser') # html.parser是html決議器,使代碼能看懂
print(soup.prettify())#列印源代碼成功,beatifulsoup成功決議demo頁面
3, beautifulsoup使用格式
from bs4 import BeautifulSoup
soup=BeautifulSoup('<p>data<p>','html.parser')
4,beautiful的基本使用元素
 beatiful soup庫 決議器
beatiful soup庫 決議器

beautiful soup類基本元素

from bs4 import BeautifulSoup
import requests
r = requests.get("http://python123.io/ws/demo.html")
demo = r.text
soup = BeautifulSoup(demo, 'html.parser')
soup.title
.>>><title>This is a python demo page</title>
tag=soup.a //只會回傳第一個
tag
>>><a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">Basic Python</a>soup.a.parent.name
>>>'p'
soup.a.name
>>>'a'soup.a.parent.parent.name
>>>'body'
tag=soup.a
tag.attrs
>>>{'href': 'http://www.icourse163.org/course/BIT-268001', 'class': ['py1'], 'id': 'link1'}
tag.attrs['href']
>>>'http://www.icourse163.org/course/BIT-268001'
5,基于bs4庫的HTML內容遍歷方法
標簽樹的下行遍歷

soup.head.contents
>>>[<title>This is a python demo page</title>]
soup.body.contents
>>>['\n', <p class="title"><b>The demo python introduces several python courses.</b></p>, '\n', <p class="course">Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses:
<a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">Basic Python</a> and <a class="py2" href="http://www.icourse163.org/course/BIT-1001870001" id="link2">Advanced Python</a>.</p>, '\n']
len(soup.body.contents)
>>>5
soup.body.contents[1]
>>><p class="title"><b>The demo python introduces several python courses.</b></p>//可用回圈進行遍歷
for child in soup.body.children:
print(child)
 標簽樹的上行遍歷
標簽樹的上行遍歷
for parent in soup.a.parents:
if parent is None://遍歷父輩會遍歷soup本身,但是soup父輩是空,所以用判斷
print(parent)
else:
print(parent.name)>>>
p
body
html
[document]
標簽樹的平行遍歷

- 平行遍歷發生在同一個父節點下的各節點間
- 平行遍歷獲得的下一個節點不一定是標簽型別
soup.a.next_sibling
>>>' and '
soup.a.next_sibling.next_sibling
>>><a class="py2" href="http://www.icourse163.org/course/BIT-1001870001" id="link2">Advanced Python</a>
- 遍歷前續節點(回圈)
for sibling in soup.a.previous_siblings:
print(sibling)
總結
 6,基于bs4庫的HTML格式輸出
6,基于bs4庫的HTML格式輸出
- print(soup.prettify())
-
print(soup.a.prettify())
>>> <a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">
Basic Python
</a>
-
soup.a.prettify()
>>>'<a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">\n Basic Python\n</a>\n'
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/402740.html
標籤:python
下一篇:Python每天定時發送監控郵件