寶子們,你們要的面試題續集終于來啦~
為了提升閱讀體驗,這次的面試題會分成若干小章節,每章只裝十道題
開始吧!!

1、java有哪些類加載器?
-
啟動類(Bootstrap)加載器 BootClassPathHolder: 加載<JAVA_HOME>/lib下的jar包
-
擴展類(Extension)加載器ExtClassLoader:加載<JAVA_HOME>/lib/ext下的jar包
-
系統類(System)加載器AppClassLoader:加載我們自己專案中寫的java檔案編譯而成的class檔案,位于target/classes下
2、int和Integer有什么區別?
Integer是int的包裝類,int則是java的一種基本資料型別,Integer的默認值是null,int的默認值是0;
JavaBean中我們應盡量使用Integer,打個比方,學生成績如果用int,缺考怎么表示,0?那考0分的呢;-1?也可以,但沒有null直觀;
3、你在專案中如何保證快取和資料庫的一致性?
記住一句話,只要有引入快取的地方,都不可能保證強一致性,所以這里的一致性是指最終一致性
方法很多,最常用的就是延時雙刪,先洗掉快取,再操作資料庫,完事兒再洗掉一次快取
第二次洗掉快取是為了避免 在第一次洗掉快取之后,到操作資料庫完成之前,這期間有新的查詢過來,導致再次把舊資料生成快取
4、如果你發現某個介面回應很慢,該怎么排查?
導致介面回應慢的原因太多了:網路、應用層、資料庫事務、服務器自身、慢sql等
逐個來說
- 網路:對于單個請求來講,網路因素影響其實很小,除非網路掛了導致請求超時才能意識到;而對于大批量請求,每個請求慢10ms,請求多了,時間也就長了,這種情況可以檢查下你的應用部署機和資料庫機地理位置是不是隔得很遠,比如一個在華東一個在西南,地理距離也會對請求回應時間產生影響,請求量越大越明顯;
- 應用層:就是我們敲的controller、service那些代碼,這一層出問題很好解決,因為代碼畢竟都是我們敲的嘛,一看日志就大概知道什么原因,最多的就是出現死回圈(當然一旦出現死回圈也不只是回應慢那么簡單了);代碼邏輯寫的差點其實不會太影響性能,現在的cpu執行效率你盡管放心,再怎么優化也頂不了少一次io;
- 資料庫事務:檢查下你的資料庫是不是卡事務了,導致鎖了很多表;
- 服務器自身:服務器是不是卡了,cpu是不是炸了,記憶體是不是滿了;
- 慢sql:這一層出問題的幾率很大,同一組查詢結果,由于sql不同,耗時能相差幾百上千倍,可以通過查看sql執行計劃來排查問題,詳見 mysql執行計劃決議
5、呼叫ReentrantLock的lock方法后,如果當前執行緒沒有獲取到鎖,它會怎么辦?
不管是公平鎖與否,都會進入clh佇列,但是注意,執行緒不會在獲取鎖失敗后立馬入隊,在真正入隊之前會多次嘗試再次獲取鎖,嘗試次數跟是否公平鎖有關:
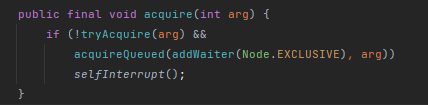
公平鎖:
先tryAcquire嘗試獲取鎖,如果失敗,執行acquireQueued,acquireQueued內部會再次執行tryAcquire嘗試獲取鎖,如果再失敗,就入隊;
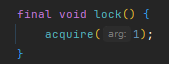
非公平鎖:
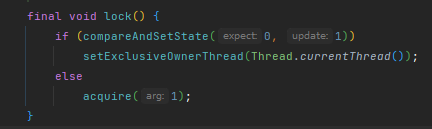
先cas嘗試獲取鎖,如果失敗,執行tryAcquire再次嘗試獲取鎖,如果還失敗,執行acquireQueued,acquireQueued內部會再次執行tryAcquire嘗試獲取鎖,如果再失敗,入隊;
6、判斷一塊記憶體空間是否會被垃圾回收器回收的標準有哪些?
- 物件的參考被賦值為null,并且后面不再呼叫
- 物件的參考被重新分配了記憶體空間
- 物件的參考被賦予了新值
7、redis的持久化機制
所謂持久化機制就是保證 redis 掛掉再重啟后,可以恢復資料
快照(默認)
默認開啟,無需設定,有個引數 save m n,這表示m秒內進行了n次寫操作就進行備份,而且可以設定多組,滿足不同場景;這里備份有兩種,一個是save(阻塞),一個是bgsave(異步),還有一種是自動化,redis的快照是采用bgsave;
AOF(AppendOnlyFile:只追加檔案)
需手動開啟,在redis.conf中開啟appendonly,默認是no,改為yes,生成的日志檔案名默認為appendonly.aof,可以修改,然后配置appendfsync,有三個選項,always、everysec和no:
默認是everysec,表示每秒同步一次,性能和資料可靠性都能兼顧,最壞情況會丟失不到2秒的資料;
no表示平時不進行同步,只會在redis關倍訓者aof被關閉時同步,性能最佳,但是丟資料風險高;
always表示每次寫操作都會同步,性能差,但是丟資料風險低;
8、Java變數的本質是什么?
String str = new String("123");
我們常說的變數,也就是上面這個str,其實就是個記憶體地址,真正的String物件在堆上
9、ConcurrentHashMap在jdk1.8相對于之前版本有什么區別?
1.7
基于Segment陣列和HashEntry,Segment繼承自ReentrantLock,懂了吧,它自然就有了鎖的基本功能;每個Segment陣列中都有多個HashEntry,我們的資料都存在HashEntry里面,每次需要修改資料時,先對HashEntry所在的Segment加鎖,其它Segment不受影響,分段鎖就是這么來的;
1.8
整體實作很像HashMap,在它基礎上引入了synchronized,和大量的CAS操作,以及大量的volatile關鍵字,所以1.8中ConcurrentHashMap的優勢在于鎖的粒度更小;
10、mysql支持哪些索引結構?
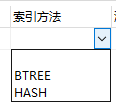
這是從navicat中截的圖,有眼睛的小伙伴可以看到mysql支持B+樹和hash
但是!!!
其實我們只能建BTREE索引,hash索引是不能人為創建的,mysql官方檔案中有提到

InnoDB utilizes hash indexes internally for its Adaptive Hash Index feature
貼心翻譯:InnoDB內部利用哈希索引實作其自適應哈希索引功能
只有mysql認為應該建hash索引的時候才會建,不信的話你建個hash索引保存,會發現變成了BTREE
再來個冷知識,hash索引全稱:innodb_adaptive_hash_index,翻譯成人話就是 innodb自適應hash索引,懂了吧
如文中有錯,請及時指出~
ok我話說完
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/404130.html
標籤:java
上一篇:cgb2111-day07
下一篇:MySQL的索引是如何實作的