分享一個大牛的人工智能教程,零基礎!通俗易懂!風趣幽默!希望你也加入到人工智能的隊伍中來!請點擊http://www.captainbed.net
MySQL中索引分三類:B+樹索引、Hash索引、全文索引,InnoDB存盤引擎中用的是B+樹索引,要介紹B+樹索引,不得不提二叉查找樹、平衡二叉樹和B樹這三種資料結構,B+樹是從它們三個演化來的,
二叉查找樹:
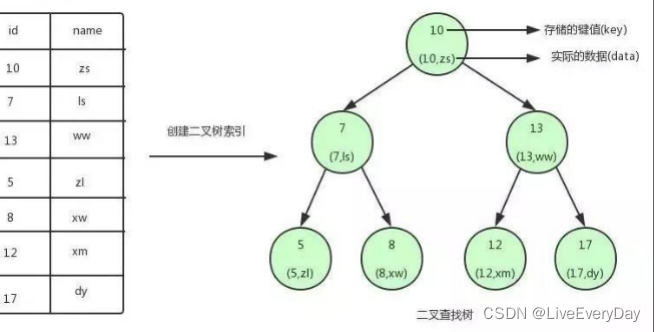
圖中為user表建立了一個二叉查找樹的索引,節點中存盤了鍵(key)和資料(data),資料對應user表中的行資料,
如果查找id=12的用戶資訊,流程如下:
1)將根節點作為當前節點,12大于10,將10的右子節點(13節點)作為當前節點,
2)12與13比較,將13的左子節點(12節點)作為當前節點,
3)12與12比較,滿足條件,從當前節點去除data,即id=12,name=xm,
利用二叉查找樹,3次可找到匹配資料,如果在表中一條一條查找,需要6次,
平衡二叉樹:
如果上面的二叉樹這樣構造:
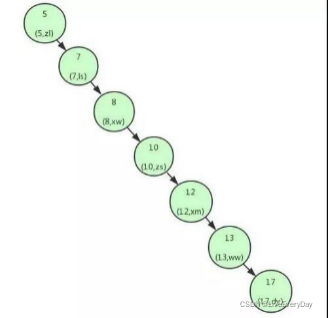
變成了一個鏈表,查詢id=17的用戶資訊,需要查7次,相當于全表掃描,導致這個現象是因為二叉查找樹不平衡了,為了解決這個問題,需要用平衡二叉樹,
平衡二叉樹又稱 AVL 樹,在滿足二叉查找樹特性的基礎上,要求每個節點的左右子樹的高度差不能超過 1,
B樹:
因為記憶體的易失性,一般會將資料和索引存盤到磁盤中,和記憶體比,從磁盤讀資料會慢很多,所以應當減少讀取次數,此外,從磁盤讀資料按照磁盤塊來讀取,而非一條一條的讀,
如果我們能把盡可能多的資料放進磁盤塊中,那一次磁盤讀取操作就會讀取更多資料,那我們查找資料的時間也會大幅度降低,如果我們用樹這種資料結構作為索引的資料結構,那我們每查找一次資料就需要從磁盤中讀取一個節點,也就是我們說的一個磁盤塊,我們都知道平衡二叉樹可是每個節點只存盤一個鍵值和資料的,那說明什么?說明每個磁盤塊僅僅存盤一個鍵值和資料!那如果我們要存盤海量的資料呢?
可以想象到二叉樹的節點將會非常多,高度也會極其高,我們查找資料時也會進行很多次磁盤 IO,我們查找資料的效率將會極低!
為了解決平衡二叉樹的這個弊端,我們應該尋找一種單個節點可以存盤多個鍵值和資料的平衡樹,也就是我們接下來要說的 B 樹,
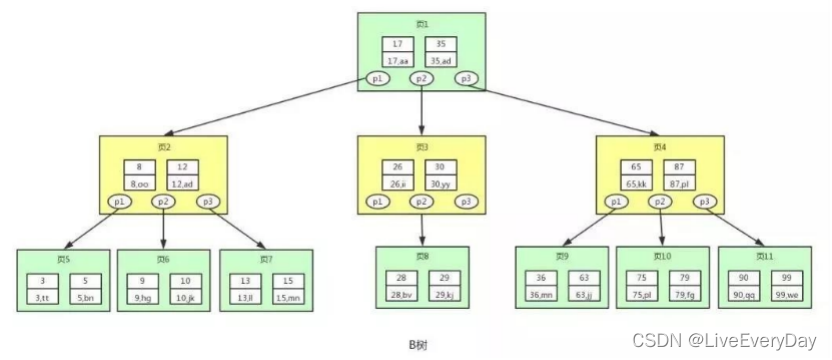
圖中的每個節點稱為頁(就是磁盤塊),在MySQL中資料讀取的基本單位都是頁,每個節點存盤了更多的鍵值和資料,子節點的個數一般稱為階,上述圖中B樹為3階B樹,
查找id=28的用戶資訊,流程如下:
1)先找到根節點也就是頁 1,判斷 28 在鍵值 17 和 35 之間,那么我們根據頁 1 中的指標 p2 找到頁 3,
2)將 28 和頁 3 中的鍵值相比較,28 在 26 和 30 之間,我們根據頁 3 中的指標 p2 找到頁 8,
3)將 28 和頁 8 中的鍵值相比較,發現有匹配的鍵值 28,鍵值 28 對應的用戶資訊為(28,bv),
B+樹:
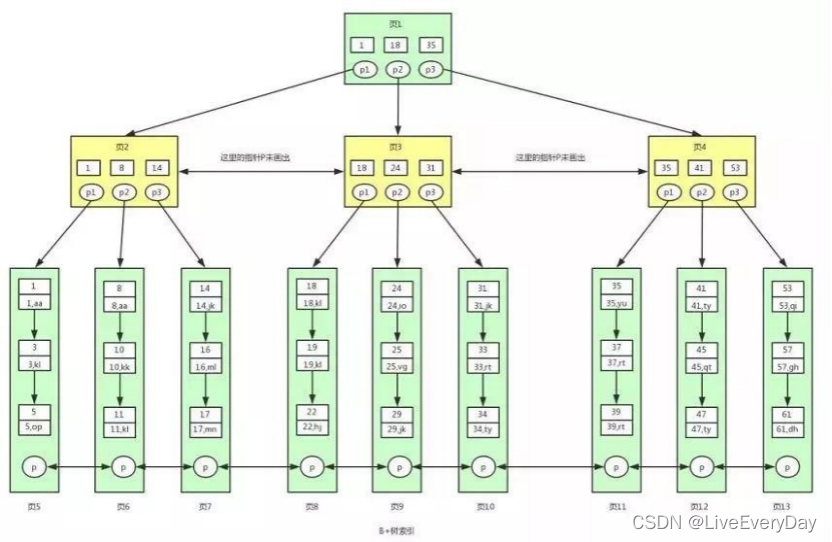
B+樹是對B樹的進化,其不同:
1)B+樹非葉子節點不存盤資料,僅存盤鍵值,B樹則存盤鍵值和資料(為什么這么做?資料庫中頁的大小是固定的,InnoDB中默認是16KB,如果不存資料,就可以存更多的鍵值,樹的階數會更大,樹就會更矮胖,查找資料進行磁盤IO的次數就會減少,查詢效率快),一般根節點是常駐記憶體的,
2)B+樹索引的所有資料存盤在葉子節點,而且資料是按照順序排列的(使得范圍查找、排序查找、分組查找及去重查找很簡單,而B樹因為資料分散在各個節點,實作這一點很不容易),B+樹的葉子節點中的資料通過單向鏈表連接,各個頁之間通過雙向鏈表連接,
通過上圖可以看到,在 InnoDB 中,我們通過資料頁之間通過雙向鏈表連接以及葉子節點中資料之間通過單向鏈表連接的方式可以找到表中所有的資料,
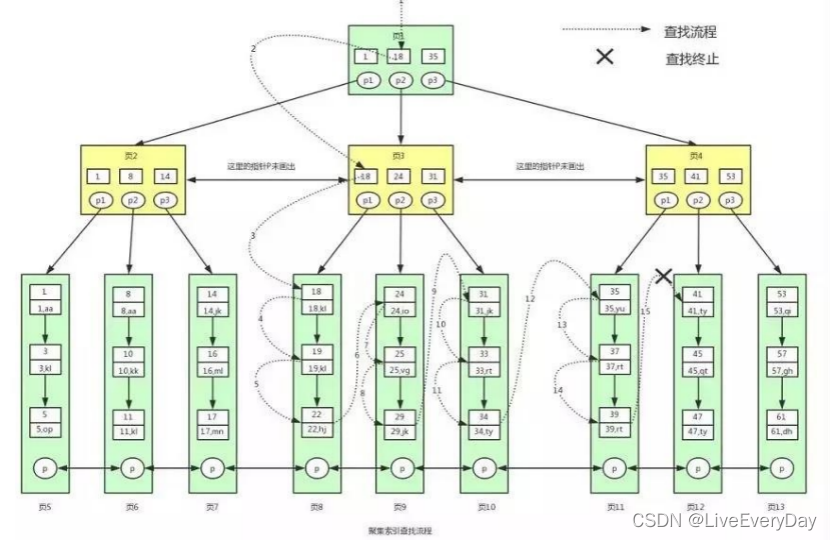
在 MySQL 中,B+ 樹索引按照存盤方式的不同分為聚集索引和非聚集索引,
利用聚集索引查找資料
現在假設我們要查找 id>=18 并且 id<40 的用戶資料,對應的 sql 陳述句為:
select * from user where id>=18 and id<40;其中id為主鍵,具體的查找程序如下:
1)一般根節點常駐記憶體的,頁1已經在記憶體中了,不用讀磁盤,直接記憶體讀取,
在記憶體中頁1查找id>=18 and id<40或者范圍值,先找到id=18的鍵值,從頁1找到指標p2,定位到頁3,
2)從磁盤中讀取頁3,然后將頁3放入記憶體中,然后進行查找,可以找到鍵值18,然后拿到頁3中的指標p1,定位到頁8,
3)將頁8讀取到記憶體中,根據二分查找法定位到鍵值18, 因為是范圍查找,而且此時所有的資料又都存在葉子節點,并且是有序排列的,那么我們就可以對頁 8 中的鍵值依次進行遍歷查找并匹配滿足條件的資料,
我們可以一直找到鍵值為 22 的資料,然后頁 8 中就沒有資料了,此時我們需要拿著頁 8 中的 p 指標去讀取頁 9 中的資料,
4)因為頁 9 不在記憶體中,就又會加載頁 9 到記憶體中,并通過和頁 8 中一樣的方式進行資料的查找,直到將頁 12 加載到記憶體中,發現 41 大于 40,此時不滿足條件,那么查找到此終止,
具體流程圖:
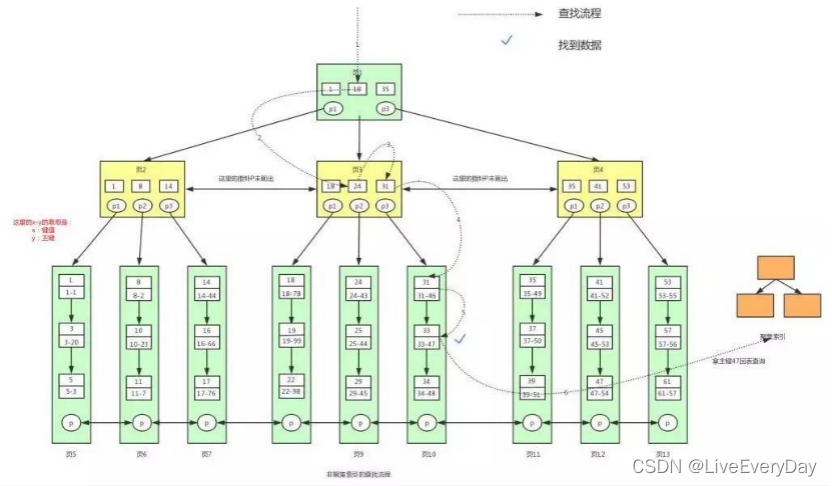
利用非聚集索引查找資料
查找幸運數字為33的用戶資訊,需要回表,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/404131.html
標籤:java