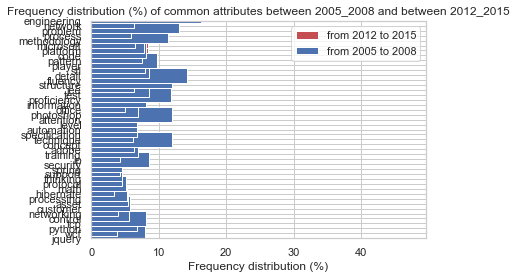
我正在做一個水平條形圖,但正在努力調整 ylim,或者可能是另一個引數,以使我的標簽更清晰,并使所有標簽都適合 y 軸。我玩過 ylim,文本大小可以更大或更小,但條形不適合 y 軸。關于正確方法的任何想法?
我的代碼:
import matplotlib.pyplot as plt #we load the library that contains the plotting capabilities
from operator import itemgetter
D=[]
for att, befor, after in zip(df_portion['attributes'], df_portion['2005_2011 (%)'], df_portion['2012_2015 (%)']):
i=(att, befor, after)
D.append(i)
Dsort = sorted(D, key=itemgetter(1), reverse=False) #sort the list in order of usage
attri = [x[0] for x in Dsort]
aft = [x[1] for x in Dsort]
bef = [x[2] for x in Dsort]
ind = np.arange(len(attri))
width=3
ax = plt.subplot(111)
ax.barh(ind, aft, width,align='center',alpha=1, color='r', label='from 2012 to 2015') #a horizontal bar chart (use .bar instead of .barh for vertical)
ax.barh(ind - width, bef, width, align='center', alpha=1, color='b', label='from 2005 to 2008') #a horizontal bar chart (use .bar instead of .barh for vertical)
ax.set(yticks=ind, yticklabels=attri,ylim=[1, len(attri)/2])
plt.xlabel('Frequency distribution (%)')
plt.title('Frequency distribution (%) of common attributes between 2005_2008 and between 2012_2015')
plt.legend()
plt.show()
這是上面代碼的情節
uj5u.com熱心網友回復:
要使標簽適合,您需要設定較小的字體大小,或使用較大的 figsize。更改ylim將僅顯示條的子集(以防ylim設定太窄),或者將顯示更多空白(ylim更大時)。
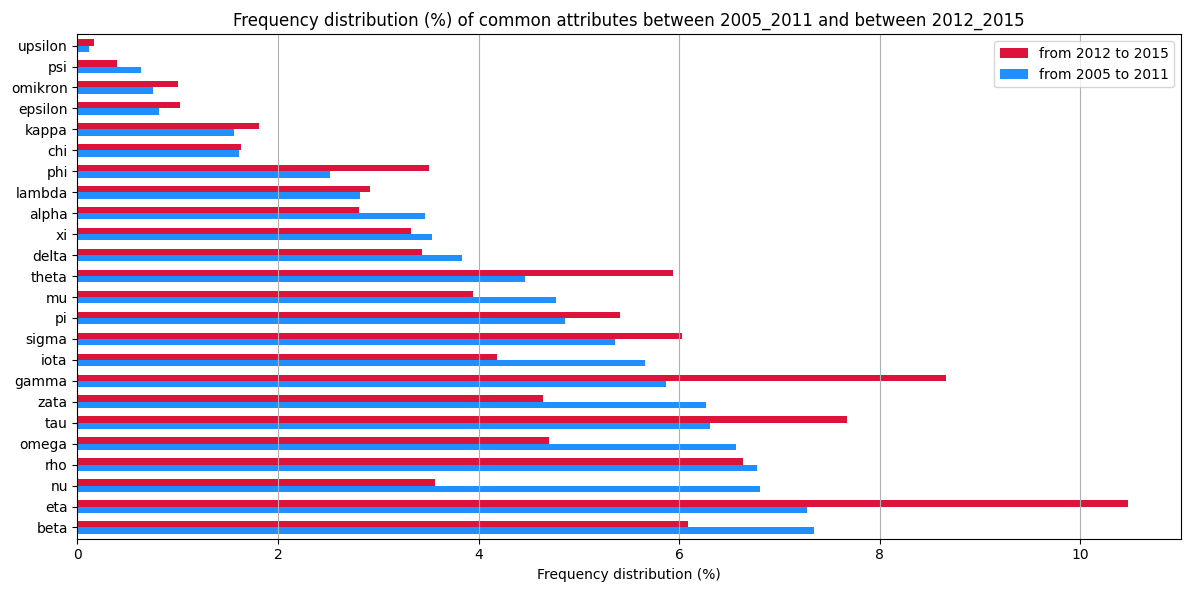
代碼中最大的問題是width太大了。兩倍的寬度需要適應一段距離1.0(刻度通過 放置ind,這是一個陣列0,1,2,...)。由于 matplotlib 將水平條形圖的厚度稱為“高度”,因此在下面的示例代碼中使用了此名稱。使用align='edge'可以讓您直接定位條形(align='center'將它們移動一半的“高度”)。
Pandas 具有根據一行或多行對資料幀進行排序的簡單功能。
代碼來說明這些想法:
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
# first create some test data
df = pd.DataFrame({'attributes': ["alpha", "beta", "gamma", "delta", "epsilon", "zata", "eta", "theta", "iota",
"kappa", "lambda", "mu", "nu", "xi", "omikron", "pi", "rho", "sigma", "tau",
"upsilon", "phi", "chi", "psi", "omega"]})
totals_2005_2011 = np.random.uniform(100, 10000, len(df))
totals_2012_2015 = totals_2005_2011 * np.random.uniform(0.70, 2, len(df))
df['2005_2011 (%)'] = totals_2005_2011 / totals_2005_2011.sum() * 100
df['2012_2015 (%)'] = totals_2012_2015 / totals_2012_2015.sum() * 100
# sort all rows via the '2005_2011 (%)' column, sort from large to small
df = df.sort_values('2005_2011 (%)', ascending=False)
ind = np.arange(len(df))
height = 0.3 # two times height needs to be at most 1
fig, ax = plt.subplots(figsize=(12, 6))
ax.barh(ind, df['2012_2015 (%)'], height, align='edge', alpha=1, color='crimson', label='from 2012 to 2015')
ax.barh(ind - height, df['2005_2011 (%)'], height, align='edge', alpha=1, color='dodgerblue', label='from 2005 to 2011')
ax.set_yticks(ind)
ax.set_yticklabels(df['attributes'], fontsize=10)
ax.grid(axis='x')
ax.set_xlabel('Frequency distribution (%)')
ax.set_title('Frequency distribution (%) of common attributes between 2005_2011 and between 2012_2015')
ax.legend()
ax.margins(y=0.01) # use smaller margins in the y-direction
plt.tight_layout()
plt.show()
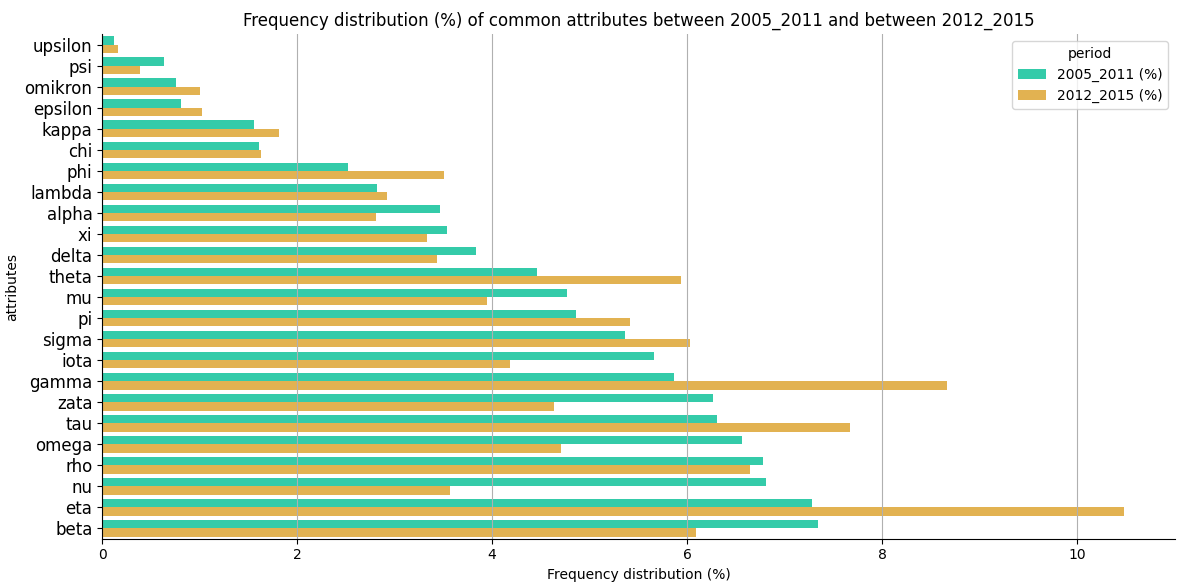
seaborn 庫有一些功能可以創建每個屬性具有多個條形圖的條形圖,而無需手動調整條形位置。Seaborn 更喜歡“長格式”的資料,可以通過 pandas' 創建melt()。
示例代碼:
import seaborn as sns
df = df.sort_values('2005_2011 (%)', ascending=True)
df_long = df.melt(id_vars='attributes', value_vars=['2005_2011 (%)', '2012_2015 (%)'],
var_name='period', value_name='distribution')
fig, ax = plt.subplots(figsize=(12, 6))
sns.barplot(data=df_long, y='attributes', x='distribution', hue='period', palette='turbo', ax=ax)
ax.set_xlabel('Frequency distribution (%)')
ax.set_title('Frequency distribution (%) of common attributes between 2005_2011 and between 2012_2015')
ax.grid(axis='x')
ax.tick_params(axis='y', labelsize=12)
sns.despine()
plt.tight_layout()
plt.show()
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/415773.html
標籤: