我有兩個具有多列的資料框。我已經使用 DataFrame 變成了長格式pd.wide_to_long
df1 = pd.wide_to_long(df_1.reset_index(), ['dvr','r'], i='index', j='Sample ID').reset_index()
df2 = pd.wide_to_long(df_2.reset_index(), ['dvlnr','r'], i='index', j='Sample ID').reset_index()
我想創建子圖,并且由于其優雅的格式功能而傾向于使用 seaborn。這是我生成帶有輔助 Y 軸的子圖的代碼。
ax= sns.relplot(data=df1, x='r', y='dvlnr', col='Sample ID', col_wrap=2, kind="line", height=4, aspect=1.5)
ax1 = plt.twinx()
ax1= sns.relplot(data=df2, x='r', y='dvr', ax=ax, col='Sample ID', col_wrap=2, kind="line", height=4, aspect=1.5)
但我總是得到 ValueError: Could not interpret value 'dvr' for parameter 'y'
我已經檢查了一些示例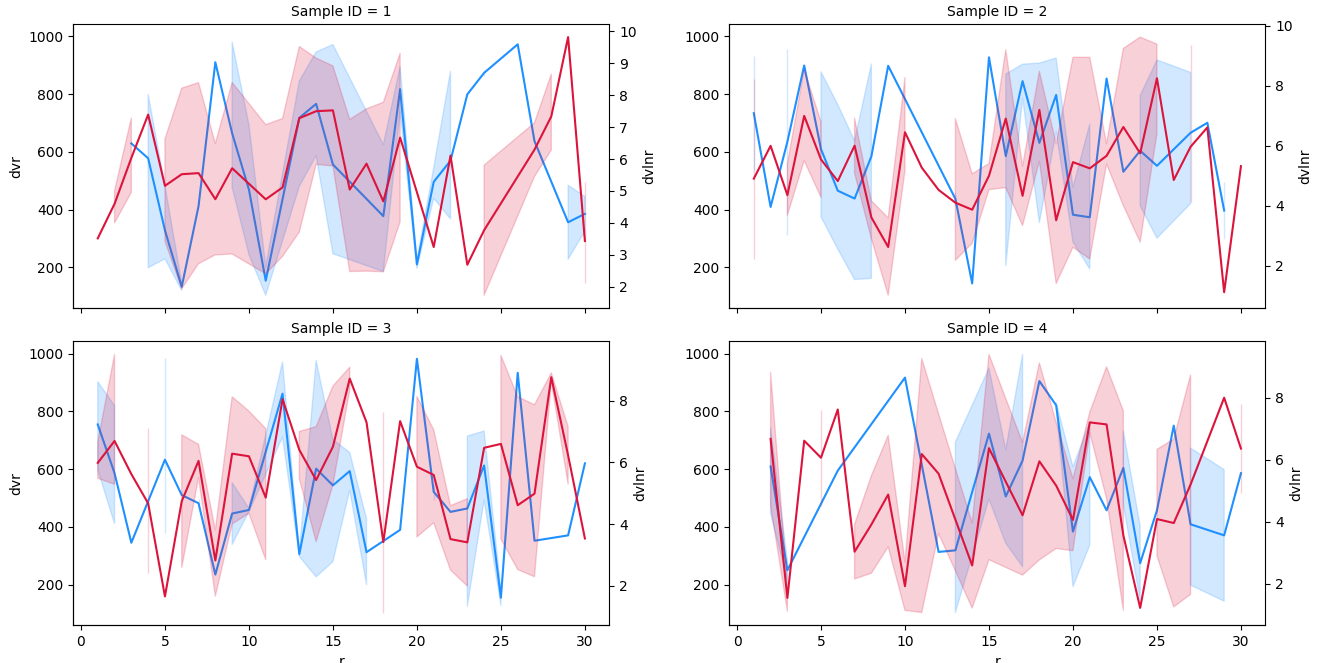
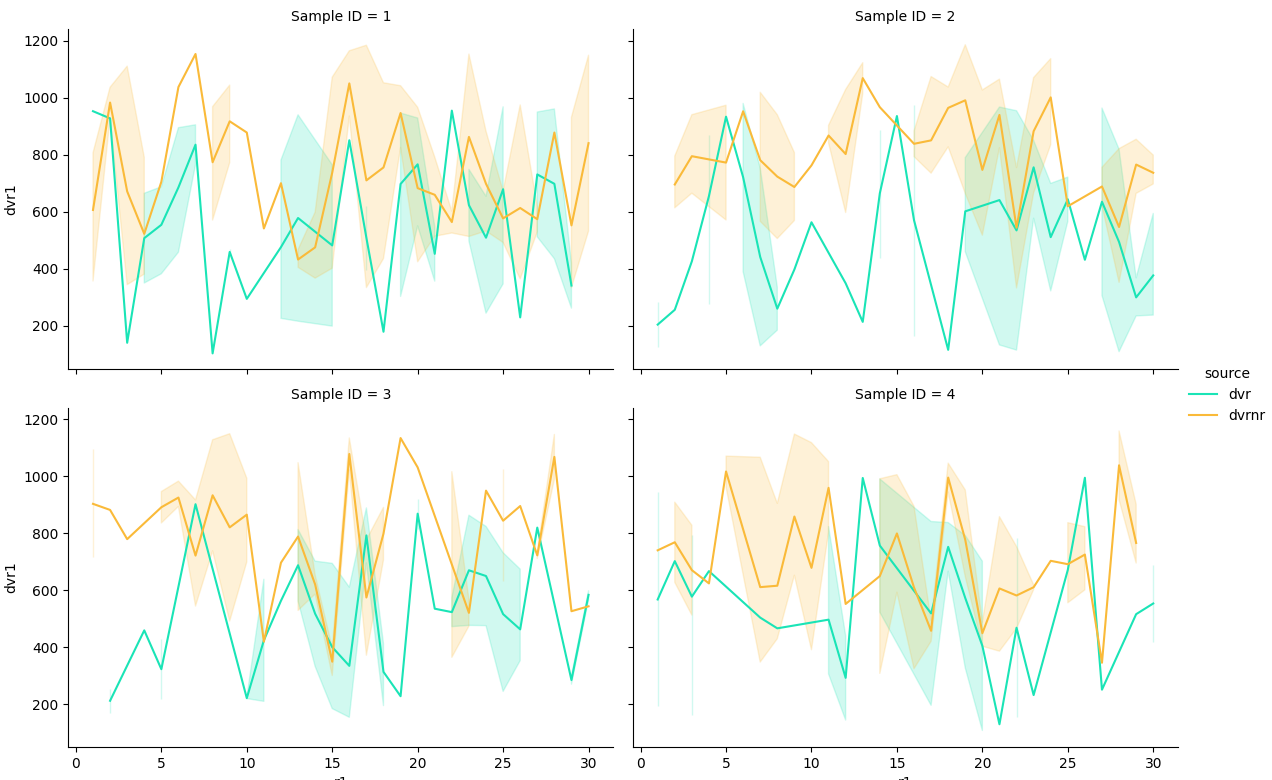
如果 y 資料的范圍足夠相似,您可以合并資料框并使用hue=. (這種方法也適用于更多資料幀。)
- 需要添加一個新列(例如“源”)以指示原始資料框
- 兩個資料框中的對應列需要相同的名稱
這是一些示例代碼:
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
import numpy as np
df1 = pd.DataFrame({'r1': np.random.randint(1, 31, 200),
'dvr1': np.random.uniform(100, 1000, 200),
'Sample ID': np.random.randint(1, 5, 200)})
df2 = pd.DataFrame({'r1': np.random.randint(1, 31, 300),
'dvlnr1': np.random.uniform(300, 1200, 300),
'Sample ID': np.random.randint(1, 5, 300)})
# add an extra column to tell to which df the data belongs
df1['source'] = 'dvr'
# the corresponding columns in both df need to have the same name for the merge
df2 = df2.rename(columns={'dvlnr1': 'dvr1'})
df2['source'] = 'dvrnr'
df_merged = pd.concat([df1, df2]).reset_index()
g = sns.relplot(data=df_merged, x='r1', y='dvr1', hue='source', col='Sample ID', col_wrap=2,
kind="line", height=4, aspect=1.5, palette='turbo')
plt.subplots_adjust(bottom=0.06, left=0.06) # plt.tight_layout() doesn't work due to legend
plt.show()
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/415775.html
標籤: