摘要:本篇我們將以分析歷史股價為例,介紹怎樣從檔案中載入資料,以及怎樣使用NumPy的基本數學和統計分析函式、學習讀寫檔案的方法,并嘗試函式式編程和NumPy線性代數運算,來學習NumPy的常用函式,
一、檔案讀入 :讀寫檔案是資料分析的一項基本技能
CSV(Comma-Separated Value,逗號分隔值)格式是一種常見的檔案格式,通常,資料庫的轉存檔案就是CSV格式的,檔案中的各個欄位對應于資料庫表中的列,
NumPy中的 loadtxt 函式可以方便地讀取CSV檔案,自動切分欄位,并將資料載入NumPy陣列,
1、保存或創建新檔案
import numpy as np i = np.eye(3) #eye(n)函式創建n維單位矩陣 print(i) np.savetxt('test.txt', i) #savetxt()創建并保存test.txt檔案
savetxt()函式,如果有已經檔案則更新,如目錄中沒有,則創建并保存test.txt檔案
運行結果如下:
[[1. 0. 0.] [0. 1. 0.] [0. 0. 1.]]
2、讀取csv檔案的函式loadtxt
1)先在保存程式的目錄下創建一個名稱為data.csv的檔案,并設定資料如下圖:

2)讀取檔案,如下:
c,v=np.loadtxt('data.csv', delimiter=',', usecols=(6,7), unpack=True)
usecols 的引數是一個元組,以獲取第7欄位至第8欄位的資料,也就是上述檔案中 股票的收盤價和成交量資料, unpack 引數設定為 True ,是分拆存盤不同列的資料,即分別將收盤價和成交量的陣列賦值給變數c和v,
3、常見的函式
成交量加權平均、時間加權、算術平均值、中位數、方差等
import numpy as np i = np.eye(3) #eye(n)函式創建n維單位矩陣 print(i) np.savetxt('test.txt', i) #savetxt創建并保存test.txt檔案 #讀取csv檔案 c,v=np.loadtxt('data.csv', delimiter=',', usecols=(6,7), unpack=True) """usecols 的引數為一個元組,以獲取第7欄位至第8欄位的資料,也就是股票的收盤價和成交量資料, unpack 引數設定為 True ,是分拆存盤不同列的資料,即分別將收 盤價和成交量的陣列賦值給變數c和v""" vwap = np.average(c, weights=v) #呼叫了average函式,將v作為權重引數使用, print(vwap) print('\n') print( np.mean(c)) #算術平均值 print('\n') t = np.arange(len(c)) print( t ) print('\n') twap =np.average(c, weights=t) #按時間權重 print( twap ) print('\n') h,l=np.loadtxt('data.csv',delimiter=',', usecols=(4,5), unpack=True) # 獲取第4欄位至第5欄位的資料,即股票的最高價和最低價 print ( np.max(h)) #獲取最大值max() print ( np.min(l)) #獲取最小值min() print('\n') print( np.ptp(h) ) # 用ptp()函式計算了極差,即最大值和最小值之間的差值 print( np.ptp(l) ) print('\n') print( np.median(c)) # 中位數median()函式,即多個資料中,處于中間的數 print( np.msort(c))#msort(( ))函式對價格陣列進行排序,可以驗證上述中位數 #方差的計算 variance = np.var(c) #方差函式var() print(variance)
用代碼、excel進行相關計算,運行結果如下:
為后面計算,將data.csv中的資料多增加幾行,修改如下并保存(為后面日期讀寫與修改,日期形式修改成如下):
603112,2022-4-1,,13.56,13.97,13.55,13.87,3750000
603112,2022-4-2,,13.75,14.25,13.69,14.03,4003500
603112,2022-4-3,,13.69,14.11,13.61,13.95,3956500
603112,2022-4-4,,14.3,14.3,13.73,13.89,4250000
603112,2022-4-5,,14.1,14.5,13.93,14,4013500
603112,2022-4-6,,14.5,15.4,14.35,15.4,9056500
603112,2022-4-7,,16,16.94,15.85,16.94,3750000
4、股票的收益率等
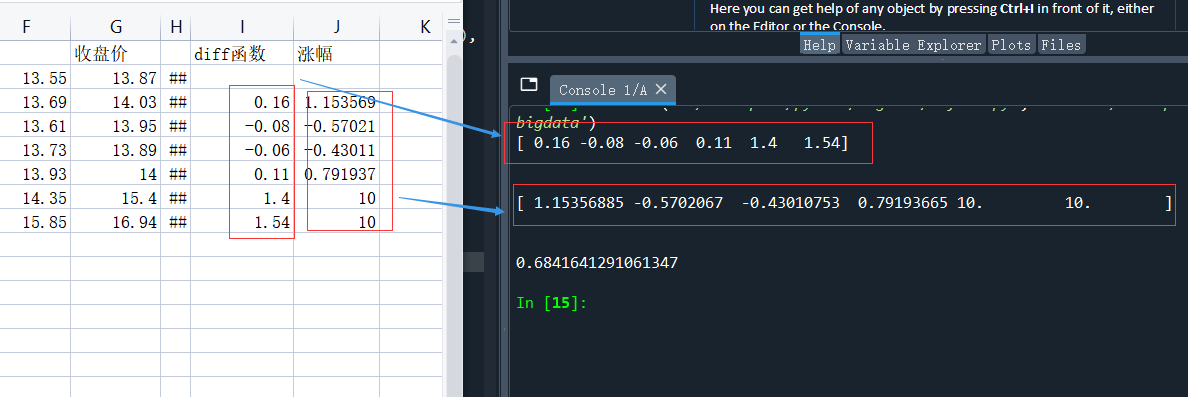
股市中最常見的就是漲幅,也就是今日收盤價相對昨日漲跌的比例,即 (今日收盤價-昨天收盤價)/昨日收盤價*100,numpy中的 diff() 函式可以回傳一個由相鄰陣列元素的差值構成的陣列,由于相鄰資料相減,因此diff()陣列資料較原陣列少一個,
如上述修改后,有7天的收盤價,diff()計算出的結果就只有6位,
import numpy as np #讀取csv檔案 c,v=np.loadtxt('data.csv', delimiter=',', usecols=(6,7), unpack=True) #股票的簡單收益率 # diff 函式可以回傳一個由相鄰陣列元素的差值構成的陣列 results = np.diff(c) print(results) print('\n') results1 = np.diff(c)/c[:-1]*100 #相對前一天的漲幅 print(results1) print('\n') Standard_deviation =np.std(results) # 計算出標準差 print(Standard_deviation)
運行結果,代碼、excel進行相比較:
5、對數收益與波動率
1)對數收益:log 函式得到每一個收盤價的對數,再對結果使用 diff 函式即可,
logreturns = np.diff( np.log(c) ) print(logreturns)
運行結果:
[ 0.01146966 -0.00571839 -0.00431035 0.00788817 0.09531018 0.09531018]
2) where的作用
where 函式可以根據指定的條件回傳所有滿足條件的序列索引值,比如上述logreturns中有兩個小于0的資料,
posretindices = np.where(results1 > 0) print('Indices with positive returns1',posretindices)
運行結果:
Indices with positive returns1 (array([0, 3, 4, 5], dtype=int64),)
3)波動率:波動率=對數收益率的標準差除以其均值,再除以交易周期倒數的平方根,下面代碼分別為以年、月進行統計的波動率.
annual_volatility =(np.std(logreturns)/np.mean(logreturns))/np.sqrt(1./252.)#使用浮點數才能得到正確的結果 print ( annual_volatility ) #月波動率 month_volatility =(np.std(logreturns)/np.mean(logreturns))/np.sqrt(1./12.) print ( month_volatility )
6、日期分析
處理日期總是很煩瑣,NumPy是面向浮點數運算的,因此需要對日期做一些專門的處理,
通過上述代碼,我們知道,修改函式np.loadtxt('data.csv', delimiter=',', usecols=(6,7), unpack=True)中的引數 usecols=(6,7)就可以讀取不同的列,日期是在第2列,即下標應該為1(數列下標是從0開始的),可以重新定義新日期數列并獲取后存入,
代碼如下:
dates, c=np.loadtxt('data.csv', delimiter=',', usecols=(1,6), unpack=True) #讀取下標為1、6的資料,分別存入到dates和c數列中,
但實際運行程序中會報錯,
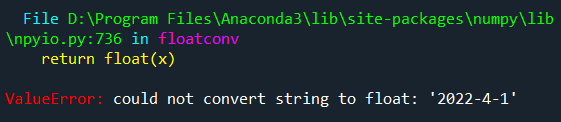
代碼需要作如下修改:
import numpy as np from datetime import datetime def datestr2num(s): #定義一個函式 return datetime.strptime(s.decode('ascii'),"%Y-%m-%d").date().weekday() #decode('ascii') 將字串s轉化為ascii碼 #讀取csv檔案 dates,close=np.loadtxt('data.csv',delimiter=',', usecols=(1,6),converters={1:datestr2num},unpack=True) print(dates)
運行結果:[4. 5. 6. 0. 1. 2. 3.],也是從0開始,到6結束,為了更好地說明資料,可以采用真實的資料,即從通信達軟體直接下載真實的交易資料,如下圖所示:

(注意:較原來少了一列空格列)
修改代碼如下:
import numpy as np from datetime import datetime def datestr2num(s): #定義一個函式 return datetime.strptime(s.decode('ascii'),"%Y-%m-%d").date().weekday() #decode('ascii') 將字串s轉化為ascii碼 #讀取csv檔案 dates,c=np.loadtxt('data.csv',delimiter=',', usecols=(1,5), converters={1:datestr2num},unpack=True) print(dates) print(len(dates)) #統計匯出的天數
運行結果:
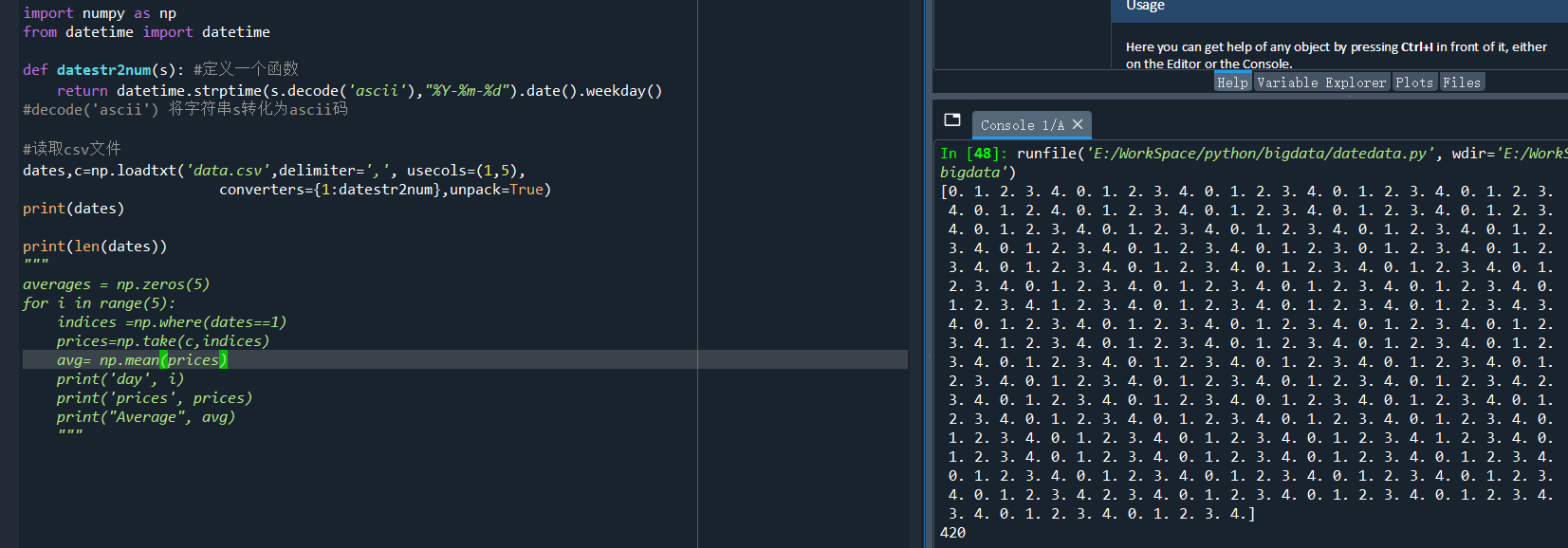
如上圖,匯出有420天資料,
按周一到周五,統計相關資料:
averages = np.zeros(5) #創建包含5個元素的陣列,保存交易日收盤價,0-4分別代表周一到周五五個交易日 for i in range(5): #遍歷0到4的日期標識 indices =np.where(dates==i) #where函式得到各作業日的索引值并存盤在 indices 陣列 prices=np.take(c,indices) #take函式獲取各個作業日的收盤價, avg= np.mean(prices) #每個作業日計算出平均值存放在 averages 陣列 averages[i] = avg #每個作業日計算出平均值存放在 averages 陣列 print('day', i) #print('prices', prices) print("Average", avg) print(averages)
當然除了上述外,還可以求得420天里的最大值、最小值以及交易日平均值中最大值、最小值等,對代碼進行如下修:
import numpy as np from datetime import datetime def datestr2num(s): #定義一個函式 return datetime.strptime(s.decode('ascii'),"%Y-%m-%d").date().weekday() #decode('ascii') 將字串s轉化為ascii碼 #讀取csv檔案 dates,c=np.loadtxt('data.csv',delimiter=',', usecols=(1,5), converters={1:datestr2num},unpack=True) averages = np.zeros(5) #創建包含5個元素的陣列,保存交易日收盤價,0-4分別代表周一到周五五個交易日 for i in range(5): #遍歷0到4的日期標識 indices =np.where(dates==i) #where函式得到各作業日的索引值并存盤在 indices 陣列 prices=np.take(c,indices) #take函式獲取各個作業日的收盤價, avg= np.mean(prices) averages[i] = avg #每個作業日計算出平均值存放在 averages 陣列,共有5個數值 print('day', i) #print('prices', prices) print("Average", avg) print(averages) print('\n') print('the top close price:',np.max(c)) #最高收盤價 print('the low close price:',np.min(c)) #最低收盤價 print('\n') top = np.max(averages) #找出averages數列中的最大值 print ("Highest average", top) print ("Top day of the week", np.argmax(averages)) #argmax函式回傳的是averages陣列中最大元素的索引值 print('\n') bottom = np.min(averages) #找出averages數列中的最小值 print ("Lowest average", bottom) print ( "Bottom day of the week", np.argmin(averages))#argmin函式回傳的是averages陣列中最小元素的索引值
運行結果如下:

本篇初步匯入了真實的股票交易資訊,并利用numpy常見函式對進行了初步的計算,列舉了下列常用函式:
loadtxt() 函式可以方便地讀取CSV檔案,自動切分欄位,并將資料載入NumPy陣列,
savetxt()創建并保存test.txt檔案
np.loadtxt('data.csv', delimiter=',', usecols=(6,7),)usecols引數用來選擇讀取的數列
np.average(c, weights=v) 加權平均,將v作為權重引數使用,
np.mean(c)) #算術平均值
np.max(h)) #獲取最大值max()
np.min(l)) #獲取最小值min()
np.ptp(h) ) 用ptp()函式計算了極值差,
np.median(c)) 中位數median()函式,即多個資料中,處于中間的數
np.msort(c))函式對價格陣列進行排序,
np.var(c) 方差函式var()
np.diff(c) 函式可以回傳一個由相鄰陣列元素的差值構成的陣列
np.std(results) # 標準差
np.diff( np.log(c) )
np.where(results1 > 0) 選擇
np.sqrt()#平方根sqrt(),浮點數
s.decode('ascii') 將字串s轉化為ascii碼
np.take(c,indices) #take函式獲取各個作業日的收盤價,
np.argmax(averages)) #argmax函式回傳陣列中最大元素的索引值
np.argmin(averages))#argmin函式回傳陣列中最小元素的索引值
下一篇將介紹股市中常見的幾個指標線,如移動均線、布林線等,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/479230.html
標籤:Python