分享概要
本次分享儒猿專欄《從零開始帶你成為MySQL實戰優化高手》中Mysql索引的內容,本次會先從一個資料頁中如何存盤和查詢資料開始,拓展到多個資料頁中查詢資料,分析無索引查詢時的低效率問題,然后通過頁分裂過渡到主鍵目錄以及索引頁相關內容,見證一顆索引樹是如何一步步生長起來的,
最后站在更高的角度看下常見的一些索引名詞、索引的優缺點以及如何才能設計出更好的索引來,開始分析前我們先來思考下如下的一些面試題:
1.InnoDB的索引資料結構是什么?為什么用這種資料結構?2.聚簇索引和普通索引的區別是什么?3.什么是回表操作?它對索引有什么影響嗎?Mysql索引的B+樹的生長流程如下圖所示:
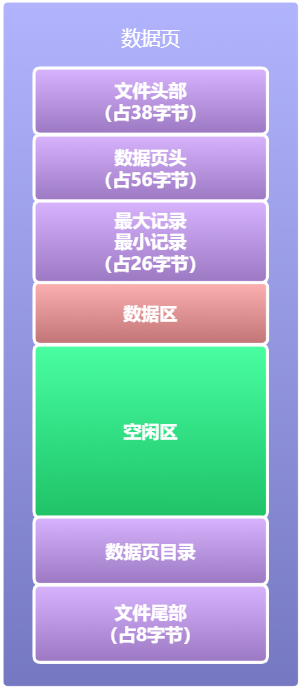
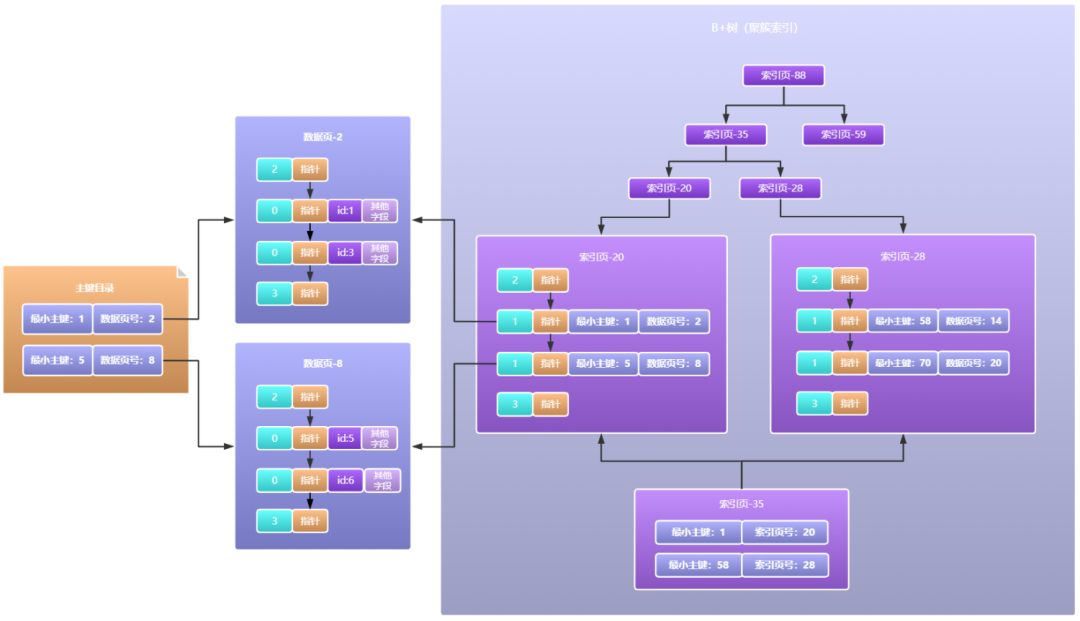 2.B+索引樹是如何生長的2.1 無索引時的資料查詢資料頁是Mysql中資料管理的最小單元,既然我們要研究索引是如何高效查詢資料的,首先我們肯定要搞清楚資料是如何存放的,資料頁的結構通過上篇文章我們了解到大概是這樣的:
2.B+索引樹是如何生長的2.1 無索引時的資料查詢資料頁是Mysql中資料管理的最小單元,既然我們要研究索引是如何高效查詢資料的,首先我們肯定要搞清楚資料是如何存放的,資料頁的結構通過上篇文章我們了解到大概是這樣的:
而資料表中的每行資料就存放在資料區中,資料區中每行資料以單向鏈表的方式,通過指標連接起來,如下圖所示: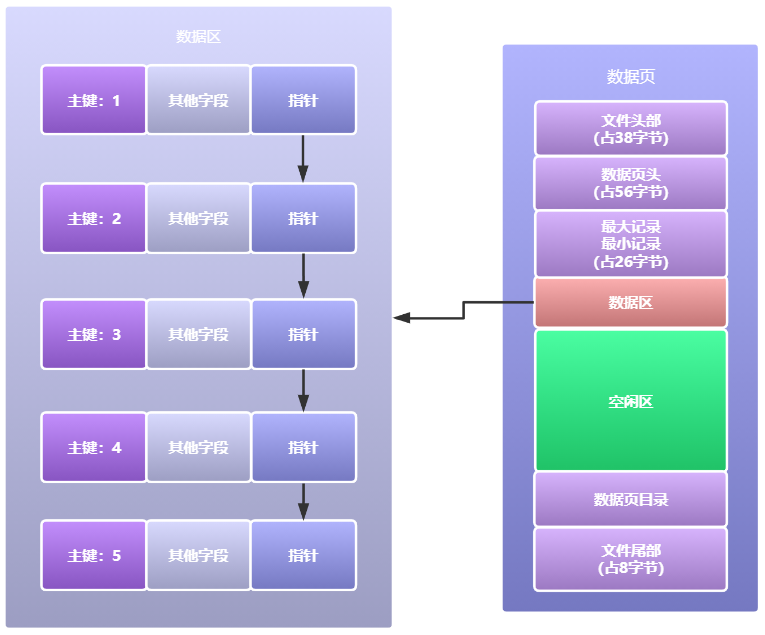
同時每個資料頁之間再通過雙向鏈表的方式組織連接起來,如下圖所示: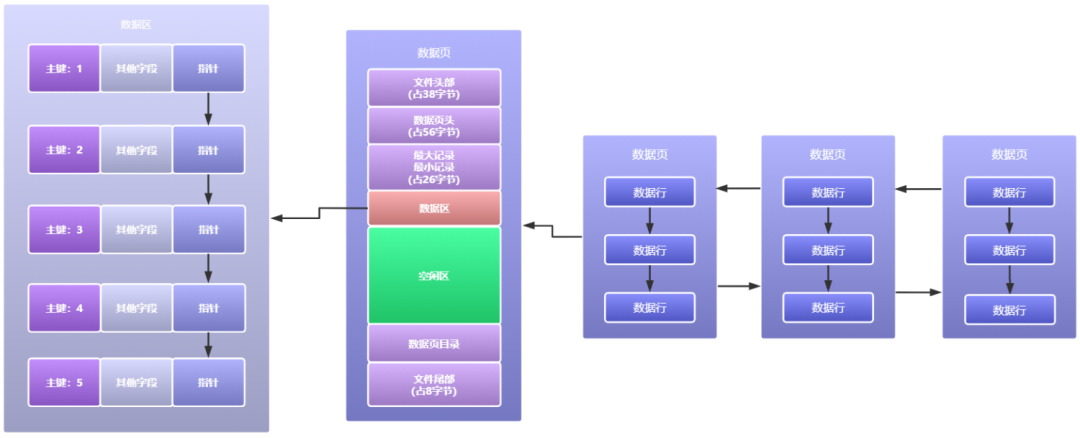
(1)無索引時的資料查詢
通過以上對資料頁以及資料頁內部資料結構初步的分析,現在我們就可以看下,如果說要查詢某張表的某行資料會經過什么樣的流程,資料頁一開始當然是存放在磁盤中的,一張表對一般會應著多個資料頁,查詢資料時從磁盤中依次加載資料頁到InnoDB的緩沖池中,然后對緩沖池中快取頁的每行資料,通過資料頁的單向鏈表一個一個去遍歷查找,如果沒有找到,那么就會順著資料頁的雙向鏈表資料結構,依次遍歷加載磁盤中的其他資料頁到緩沖池中遍歷查詢,
大家可以看到,像上面這樣的查詢方式就有點傻了,因為如果恰好你要查的資料行在這張表最后一個資料頁的最后一行,那豈不是所有的資料頁都要被掃描一遍,然后每個資料頁中也是遍歷鏈表,整體的效果就是以O(n)的時間復雜度在遍歷鏈表了,這樣查詢的性能肯定是不行的,
(2)優化資料頁內查詢效率-槽位我們先把目光轉移到單個資料頁內的資料查詢,假如說我們現在已經鎖定資料就在某個資料頁中了,但是我們該怎樣快速的從這個資料頁中找到我們想要的那行資料呢?通過之前的分析我們可以知道,最傻的一種方式就是遍歷資料頁中的單向鏈表查詢,一個節點一個節點去掃描,相對應的查詢效率是肉眼可見的低,但是如果說可以像翻書一樣,根據目錄來減小我們查詢的范圍,相對應的查詢效率不就上來了嗎,根據這種想法,InnoDB存盤引擎設計了槽位這種方式來組織資料頁中的多個資料行,槽位資訊存放在資料頁中的資料頁目錄中,
槽位簡單來說就是將資料頁中的多個資料行分組劃分,每個資料行組都找這個組中的主鍵值最大的那個資料行的地址作為槽位的資訊,這樣資料頁目錄中的一個個槽位不就是像是一個個目錄了嗎,標記好了多個資料行分組的位置資訊,如下圖所示:
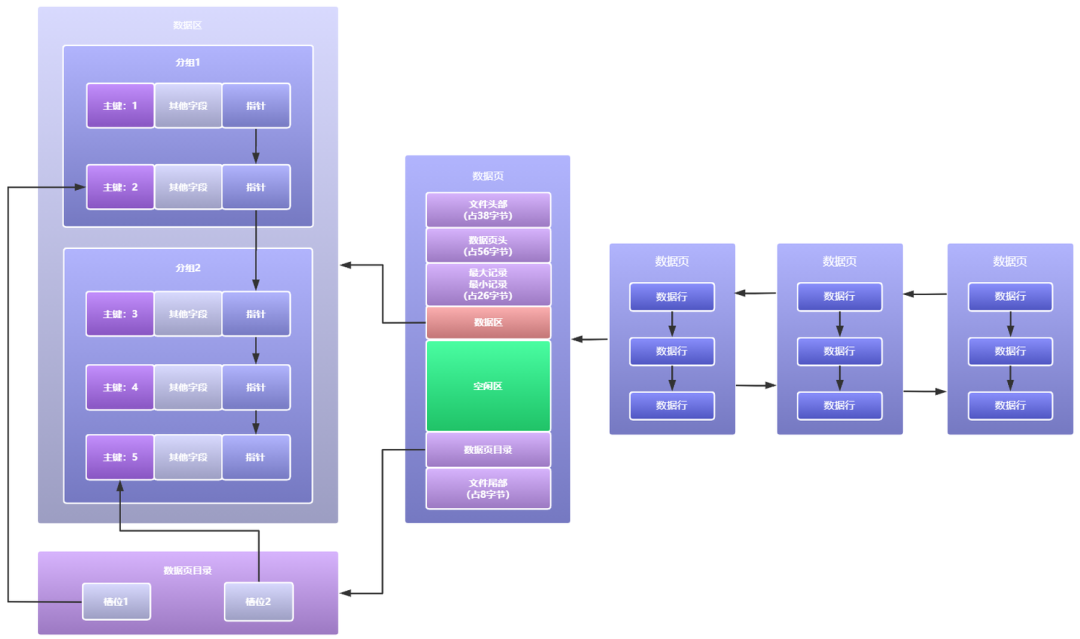
這下有了資料頁目錄中的槽位資訊,此時要查詢資料頁中的某行資料不就很簡答了,比如我們要查詢主鍵為4的那行資料,直接通過二分法以O(logn)的時間復雜度鎖定資料頁目錄中的槽位2,因為槽位之間都是緊密連接的,可以通過槽位2找到槽位1,從槽位1末尾開始,對分組2中的資料開始遍歷,因為每個分組中的資料量都很少,此時在這么小的范圍內簡單遍歷下就可以快速找到主鍵為4的那行資料,時間復雜度從之前的O(n)降低到O(logn)效率還是挺可觀的,但是如果你不是通過主鍵去查詢的,槽位此時就排不上用場,你還得一個一個遍歷資料頁中的單向鏈表去找到你想要的那行資料,
2.2 索引的前夕-頁分裂
這里我們先來個小插曲,簡單了解下頁分裂,這塊內容也是后面索引機制能夠正常運行的基礎,我們都知道一個資料頁就是16KB大小,當一個資料頁中的資料行足夠多時就會重新創建一個資料頁繼續寫資料行,如果說我們沒有用到索引還好,但是如果我們要在表中創建索引,那么對多個資料頁中的資料就有約束了,
如果新創建的資料頁中的資料行的主鍵值,存在比它上一個資料頁的主鍵值還小的情況,這種情況是不被允許的,如下圖所示: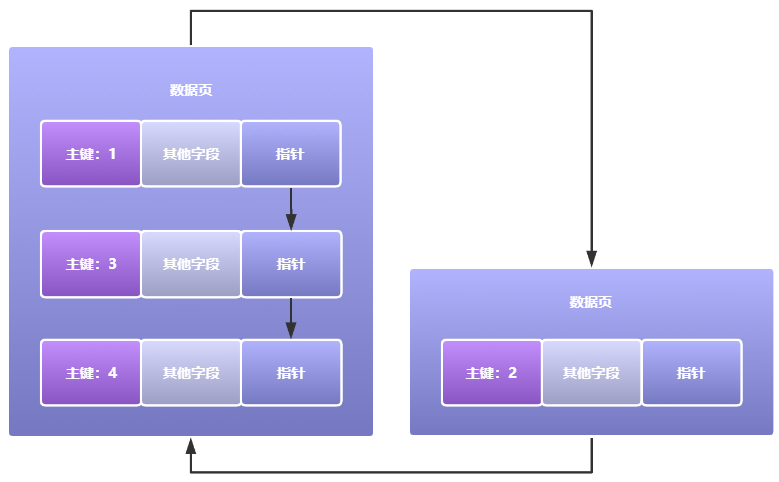 如果出現上圖的情況,多個資料頁之間的主鍵就無序了,而索引機制的實作是要基于多個資料頁主鍵的大小是依次遞增的,所以此時就會出現頁分裂的情況,
如果出現上圖的情況,多個資料頁之間的主鍵就無序了,而索引機制的實作是要基于多個資料頁主鍵的大小是依次遞增的,所以此時就會出現頁分裂的情況,
其實頁分裂目的也很明確,就是調整下不同資料頁的資料順序,使得最終按順序創建的索引頁之間,后一個資料頁中的每一個資料行的主鍵值都要大于上一個資料頁,當然一個資料頁中當然是按照單向鏈表的方式依次遞增的,頁分裂流程如下圖所示: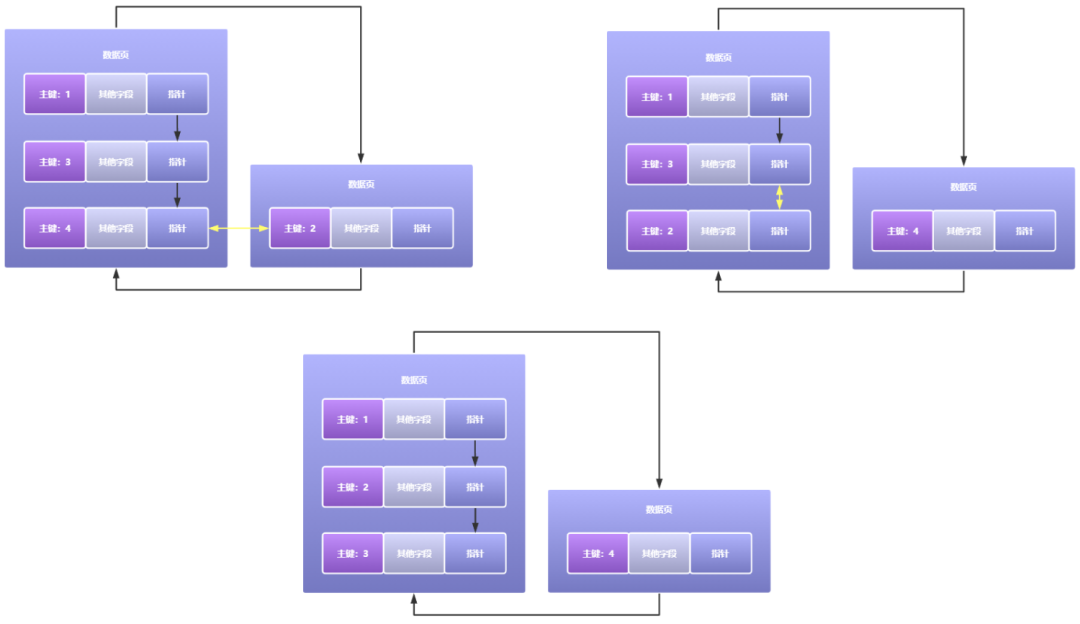
我們可以看到頁分裂主要就是調整了下資料頁之間資料行的資料的順序,使得多個資料頁之間的主鍵值是按照順序來存放的,在這樣有序的資料中,高效查詢才變得可能,頻繁的出現頁分裂情況,畢竟頁分裂要涉及到資料的移動,在性能上也是會有損耗的,這也警示我們減少頁分裂的出現概率是非常有必要的,在設計表結構時我們可以盡量使用主鍵自增長的方式,而不是用很難保證主鍵順序的自定義創建主鍵的方式,使用主鍵自增長方式,能大大避免說資料頁之間主鍵大小出現順序錯亂的問題,減少頁分裂發生的概率,
2.2 從主鍵目錄到索引頁
查詢一行資料,在物理層面就是定位到哪一個資料頁中的哪一行資料,在資料頁中定位資料的問題,在之前我們已經通過槽位的方式優化了查詢的效率,現在我們要解決的是如何在大量的資料頁中定位資料頁,這就是索引的目標,
(1)主鍵目錄
InnoDB存盤引擎一開始是使用主鍵目錄的方式,將資料頁號和資料頁最小的主鍵值作為一條記錄,如下圖所示: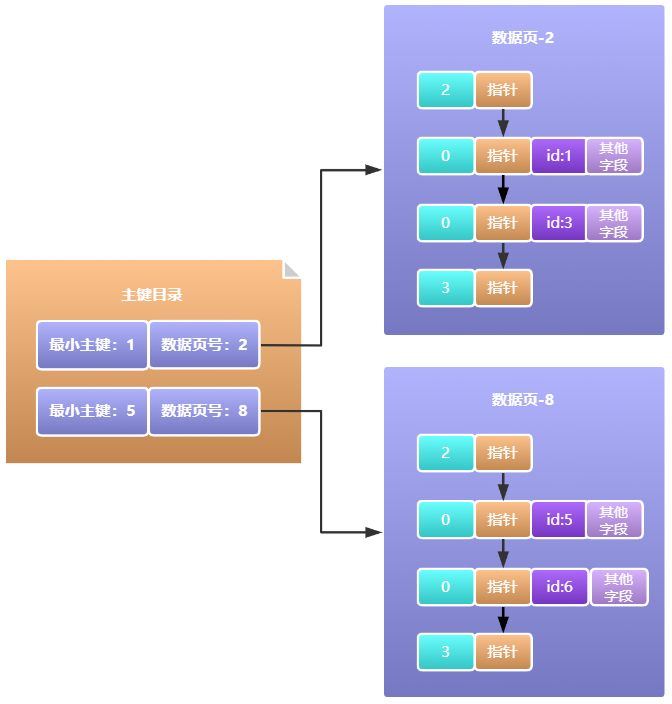 這樣的話,我們要查哪一條資料就不用掃描一個資料頁內的所有資料再掃描下一個了,直接通過id去主鍵目錄看一下,通過二分查找定位到具體哪個資料頁,然后資料頁內部通過定位槽位,遍歷那個槽位對應資料行分組找到具體的一行資料,
這樣的話,我們要查哪一條資料就不用掃描一個資料頁內的所有資料再掃描下一個了,直接通過id去主鍵目錄看一下,通過二分查找定位到具體哪個資料頁,然后資料頁內部通過定位槽位,遍歷那個槽位對應資料行分組找到具體的一行資料,
(2)索引頁
現在有一個問題就是,每張表對應的資料頁都有很多,主鍵目錄就會有大量的資料、就有可能放不下,這時InnoDB設計者們就想存放目錄資料也是資料啊,為什么不可以使用資料頁來放呢,就這樣主鍵目錄的資訊就被移到資料頁來了,而這些資料頁就被稱為索引頁,如下圖所示: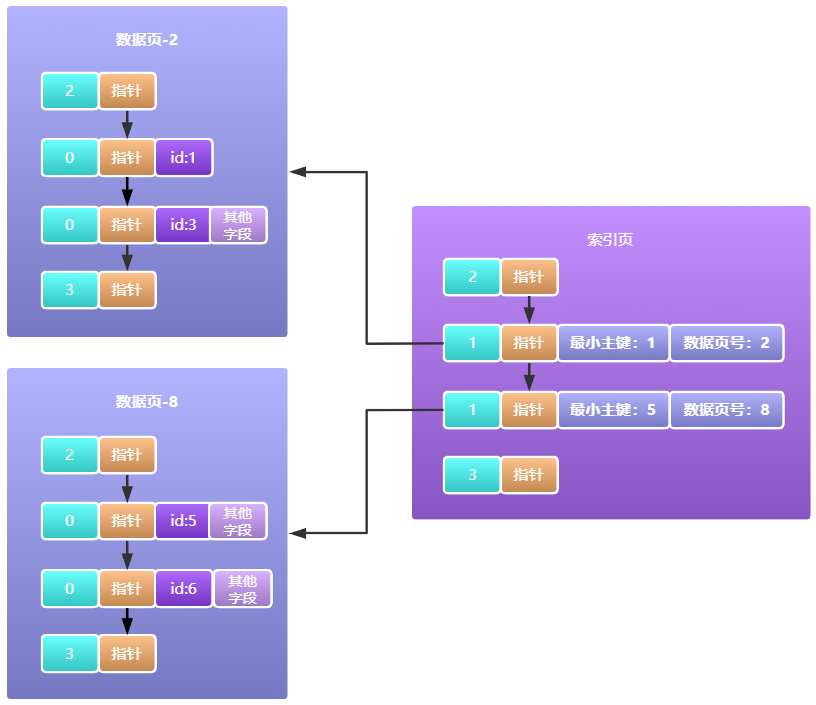
從這里我們可以知道資料頁肯定不是簡單只存放資料表中的資料的,好了,現在主鍵目錄由于容量有限,我們把主鍵目錄資訊移動到了資料頁中形成了索引頁,但同樣的問題不還是會出現嗎,一個資料頁的大小也才16KB,索引頁本身的容量也是有限的,容量不夠了該怎么辦呢?
為了解決索引頁容量不夠的問題,索引頁會重新創建和升級,先把超出容量的資料放到一個新的索引頁中,然后再加一層索引頁,如下圖所示:
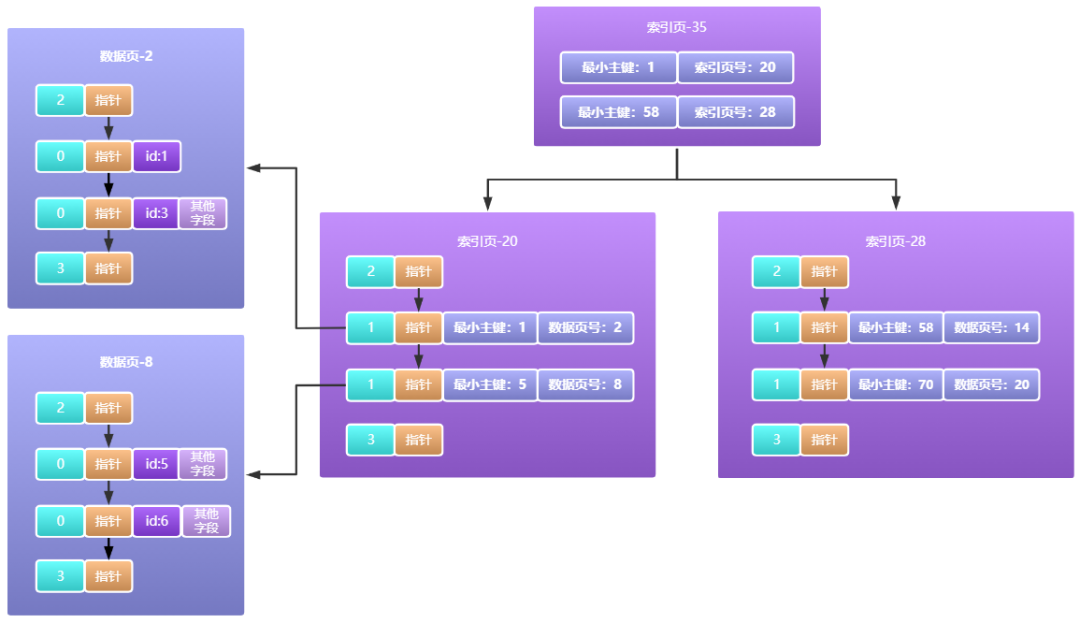
由上圖我們可以看到,新的一層索引頁35它存放的就不是最小主鍵對應的資料頁目錄了,而是最小主鍵對應的索引頁目錄了,以此類推如果索引頁35這里容量也不夠呢,那就繼續往上一層擴展啊,最終效果看起來就像下面一樣: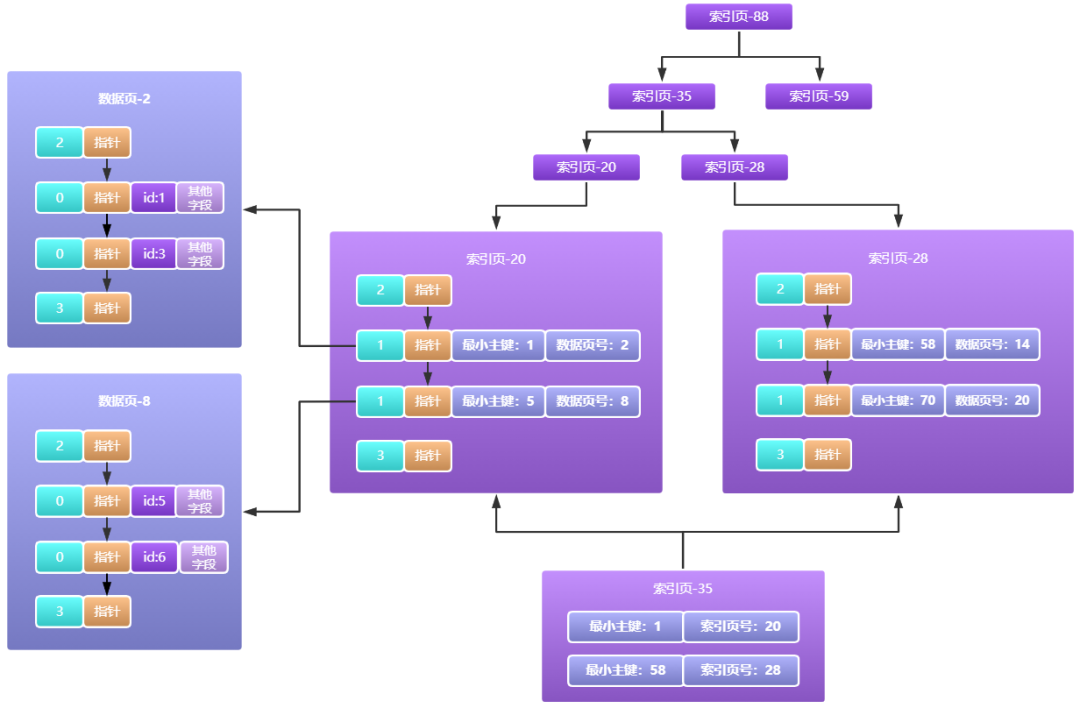
大家看出來了嗎,由索引頁一層一層組成的結構不就是我們經常說的索引樹嗎,而這棵樹在mysql中稱之為B+索引樹,樹這種資料結構天然可以使用二分法查詢,所以現在如果我們要查詢一條資料,從樹的根節點開始通過二分法查找,以O(logn)的時間復雜度鎖定資料頁,然后在資料頁中同樣使用二分法鎖定槽位,在槽位中簡單遍歷下不就找到資料了嗎,相比于沒有索引的場景,速度那可是相當快了,
3.聚簇索引、普通索引和覆寫索引關于索引有一些常見的名詞我們需要加以區分,首先聚簇索引就是像我們上面看到的一棵樹一樣,它的葉子節點是一個個資料頁,這些資料頁中存放的都是資料表中每一行的完整資料,所以說如果B+樹是以完整資料的資料頁為葉子節點的,我們把這個索引樹稱為聚簇索引;如果一個索引的索引樹,葉子節點不是以資料頁為葉子節點的,就稱為二級索引或普通索引,
聚簇索引和普通索引最大的區別就是,聚簇索引的葉子節點存放了資料行的完整資料,而二級索引葉子節點只有資料的部分欄位,
而覆寫索引本身并不是一種索引,而是一種查詢資料的方式,比如我們對表table中的欄位name建立了索引,然后我們執行查詢如:select name from table where name like '張%',此時直接從name欄位對應的B+樹種查詢到對應的一批name值,然后直接就回傳就行了,也就是說我們想要的欄位name它本來就在索引上,我們直接通過二分法高效的從樹上直接摘下來就行了,而這種查詢方式就稱為覆寫索引,
當然相比于覆寫索引方式,如果查詢改為:select * from table where name like '張%',這就不是覆寫索引了,因為此時你不光要從索引樹上找到具體的name,還要利用id值回表查詢所有的欄位,
4.索引的優缺點分析索引的優點當然就是高效查詢資料,索引將遍歷鏈表的O(n)的查詢時間復雜度優化為了O(logn)的時間復雜度,但是索引的缺點也是很明顯的,首先在時間角度上,它必須要求主鍵是要按順序增長的,無序的主鍵會帶來頻繁的頁分裂,影響效率;對資料庫表的增刪改操作的同時也需要維護索引,這部分的維護也是一塊性能損耗點;在空間角度上:索引相關的資料和實際資料一樣都是要占記憶體空間的,所以索引雖然能夠提高查詢效率,但是同時也要承擔它給我們的系統帶來的性能損耗,從這點上來看索引并不是建的越多越好,
5.三個維度設計好索引
下面我們從以下三個維度優化下索引的設計
(1)首先我們從時間角度上我們需要為了避免頻繁的頁分裂,需要盡可能使用主鍵自增長等方式,保證新增的資料頁中的資料行的主鍵都是遞增,避免不必要的頁分裂帶來的性能損耗和拖慢查詢效率,
另外選擇合適的欄位作為索引欄位也很重要,需要選擇基數較大的欄位,也就是一個欄位可能出現的值比較多,這樣我們在B+樹中查詢時,才能最高效的發揮出二分法查詢的威力,如果建立索引的欄位基數比較小可能查詢時二分查找就會退化成時間復雜度為O(n)的線性查詢了,
(2)空間的角度上
因為索引資料本身也是要占空間的,可以選擇欄位長度較小的作為索引欄位,這樣整棵B+樹不至于那么占空間,但是如果非得要以長欄位作為索引也不是不行,可以采用折中的以欄位的前綴作為索引,這樣的索引也稱為前綴索引,但是這樣可能只能用在模糊查詢上了,用在group by和order by上就不太適合了,
(3)作用范圍上
當然我們設計索引的目的,當然是為了更好的用上索引,索引在設計時,盡可能讓where、group by、order by這些陳述句都能用上索引,
本文由博客一文多發平臺 OpenWrite 發布!
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/491977.html
標籤:Java