Hi,大家好,我是Mic,
一個作業5年的粉絲,在簡歷上寫精通Kafka,
結果在面試的時候直接打臉,
面試官問他:“什么是ISR,為什么需要設計ISR”
然后他一臉懵逼的看著面試官.
下面看看普通人和高手的回答,
普通人:
ISR好像是Kafka里面的一個機制吧,
為什么要引入,應該是跟資料同步有關系,
高手:
好的,關于這個問題,我需要從幾個方面來回答,
首先,發送到Kafka Broker上的訊息,最終是以Partition的物理形態來存盤到磁盤上的,
而Kafka為了保證Parititon的可靠性,提供了Paritition的副本機制,然后在這些Partition副本集里面,
存在Leader Partition和Flollower Partition,
生產者發送過來的訊息,會先存到Leader Partition里面,然后再把訊息復制到Follower Partition,
這樣設計的好處就是一旦Leader Partition所在的節點掛了,可以重新從剩余的Partition副本里面選舉出新的Leader,
然后消費者可以繼續從新的Leader Partition里面獲取未消費的資料,
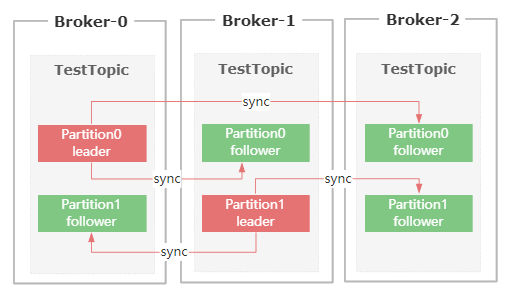
在Partition多副本設計的方案里面,有兩個很關鍵的需求,
- 副本資料的同步
- 新Leader的選舉
這兩個需求都需要涉及到網路通信,Kafka為了避免網路通信延遲帶來的性能問題,
以及盡可能的保證新選舉出來的Leader Partition里面的資料是最新的,所以設計了ISR這樣一個方案,
ISR全稱是 in-sync replica,它是一個集合串列,里面保存的是和Leader Parition節點資料最接近的Follower Partition
如果某個Follower Partition里面的資料落后Leader太多,就會被剔除ISR串列,
簡單來說,ISR串列里面的節點,同步的資料一定是最新的,所以后續的Leader選舉,只需要從ISR串列里面篩選就行了,
所以,我認為引入ISR這個方案的原因有兩個
- 盡可能的保證資料同步的效率,因為同步效率不高的節點都會被踢出ISR串列,
- 避免資料的丟失,因為ISR里面的節點資料是和Leader副本最接近的,
以上就是我對這個問題的理解,
總結
在我看來,這個問題非常有研究價值,
一般來說,副本資料同步,無非就是同步阻塞、或者異步非阻塞,
但是這兩種方案,要么帶來性能問題,要么帶來資料丟失問題,都不是特別合適,
而ISR,就非常完美解決了這個問題,在實際程序中,我們也可以借鑒類似的設計思路,
喜歡我作品的小伙伴,記得點贊收藏加關注,
著作權宣告:本博客所有文章除特別宣告外,均采用 CC BY-NC-SA 4.0 許可協議,轉載請注明來自
Mic帶你學架構!
如果本篇文章對您有幫助,還請幫忙點個關注和贊,您的堅持是我不斷創作的動力,歡迎關注「跟著Mic學架構」公眾號公眾號獲取更多技術干貨!
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/497685.html
標籤:Java