java集合
學習資源:b站 人人都是程式員 《看影片學java集合》
b站 韓順平 《java集合》 感謝二位的開源視頻,本博客為個人筆記,如有錯誤還請包涵
學習方法:推薦觀看視頻,自己用idea敲一遍然后debug一步步看,最后自己寫筆記和畫流程圖,
前 言
-
目的:為了方便和高效地存盤大批量的資料,變數和陣列是遠遠不夠的,我們需要能動態擴容的容器來存盤,
-
java的集合
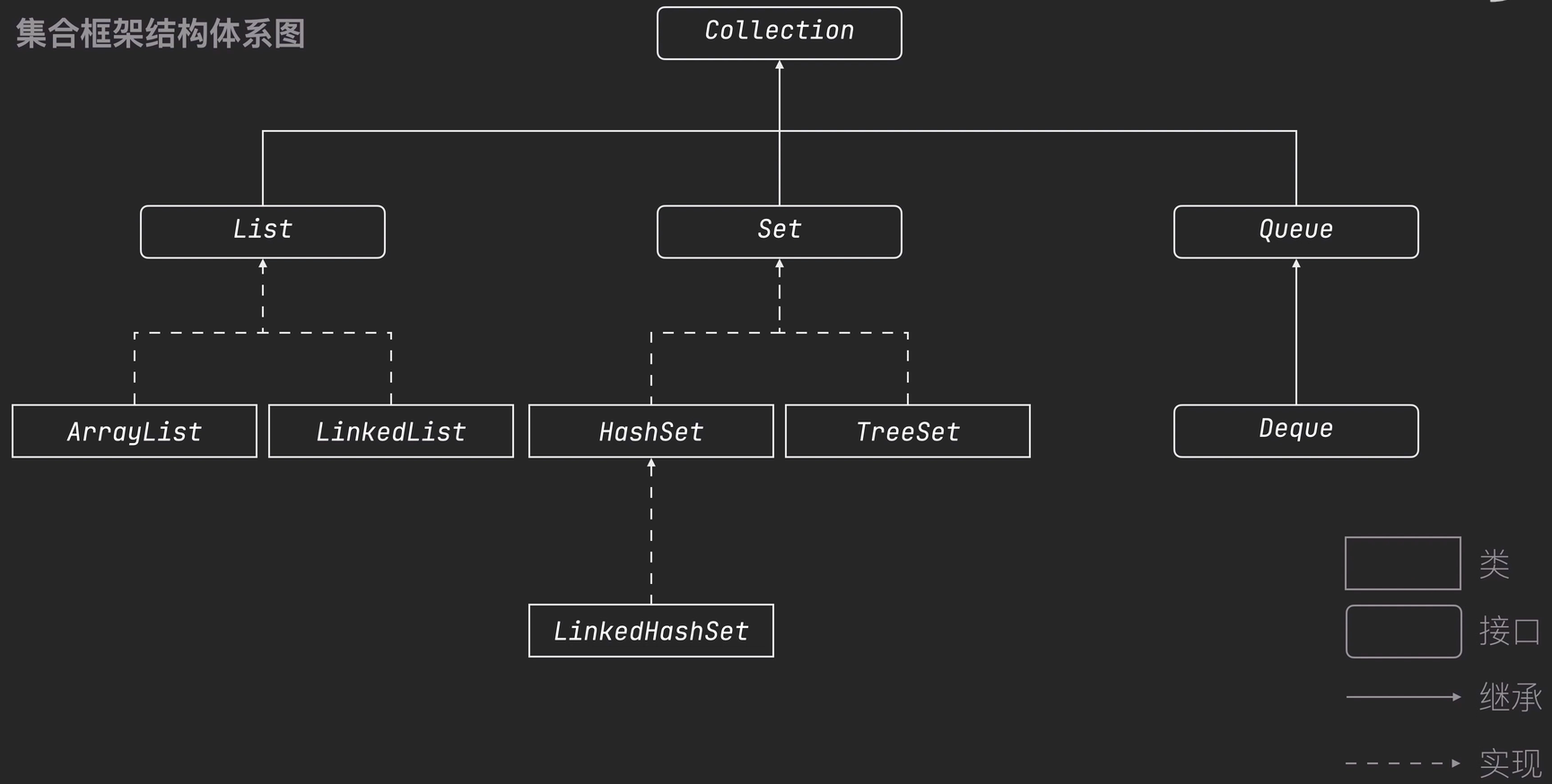
-
鍵值對
Collection
- 分類

- Collecion工具類
- 排序方法

- 查找替換

- 排序方法
- 迭代器Iterator
- 所有的集合都實作了迭代器Iterable介面,迭代器是遍歷集合的元素,并且回傳,
- 實作:1. 先新建迭代器 2. 呼叫hashnext方法 3. 呼叫next方法
- 增強型for回圈的底層實作也是迭代器
Collection
Set
- HashSet,由HashMap實作
-
無序,存取順序不一致,其他特點與HashMap一致
-
區別,HashMap是以key-value存放,而HashSet則是把key當value用,而value則由統一的值代替,
-
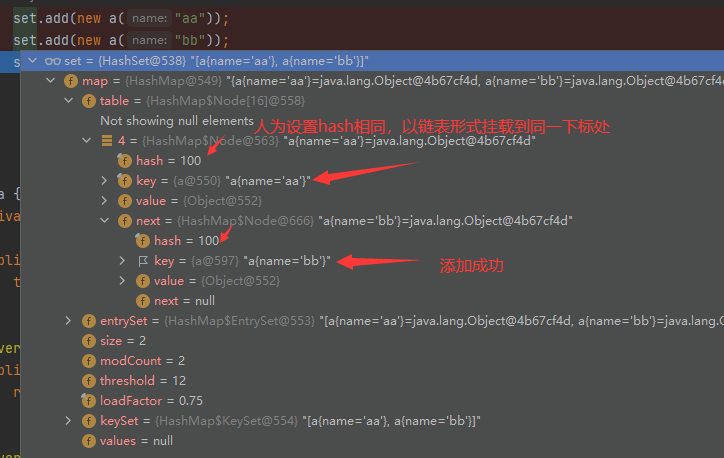
添加元素時,如果在同一個下標處有別的值,則用equals進行比較,如果相同則放棄添加,不同則添加到后面,
-
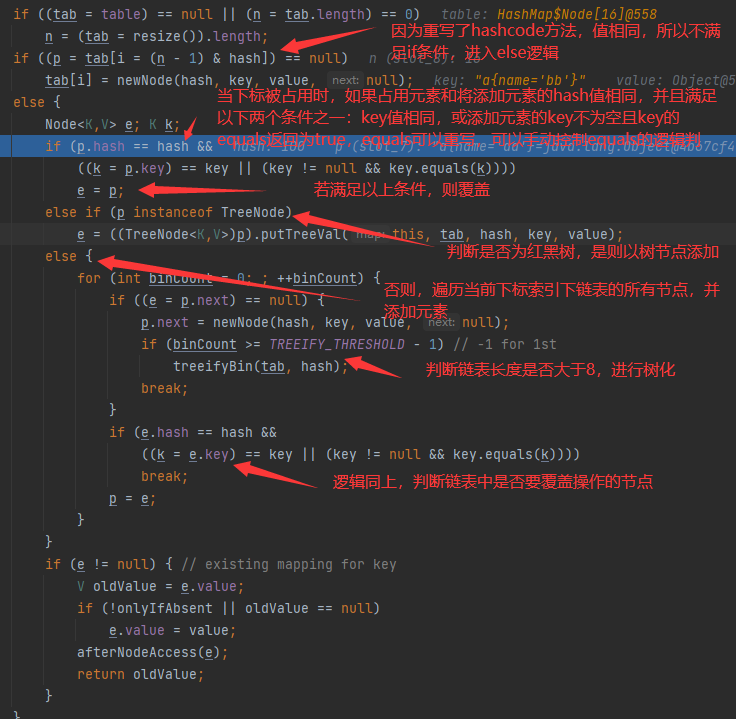
add方法初次添加,原始碼及流程分析

-
add方法再次添加流程
-
-
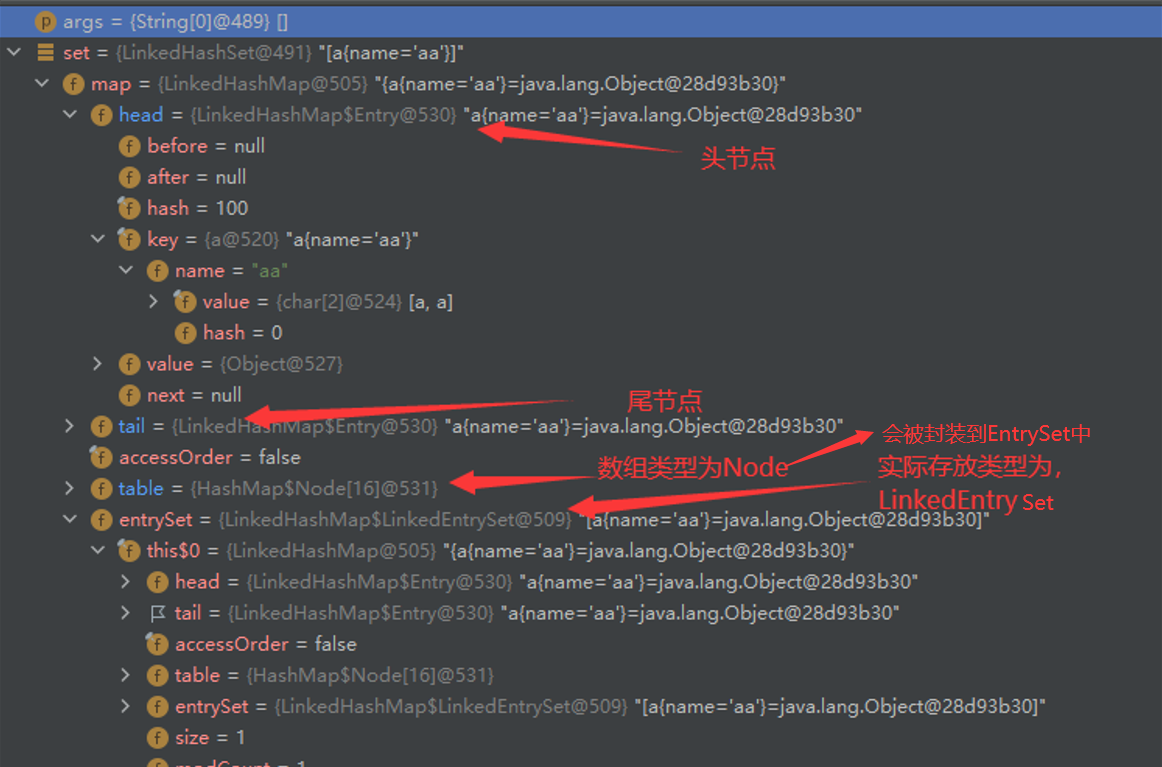
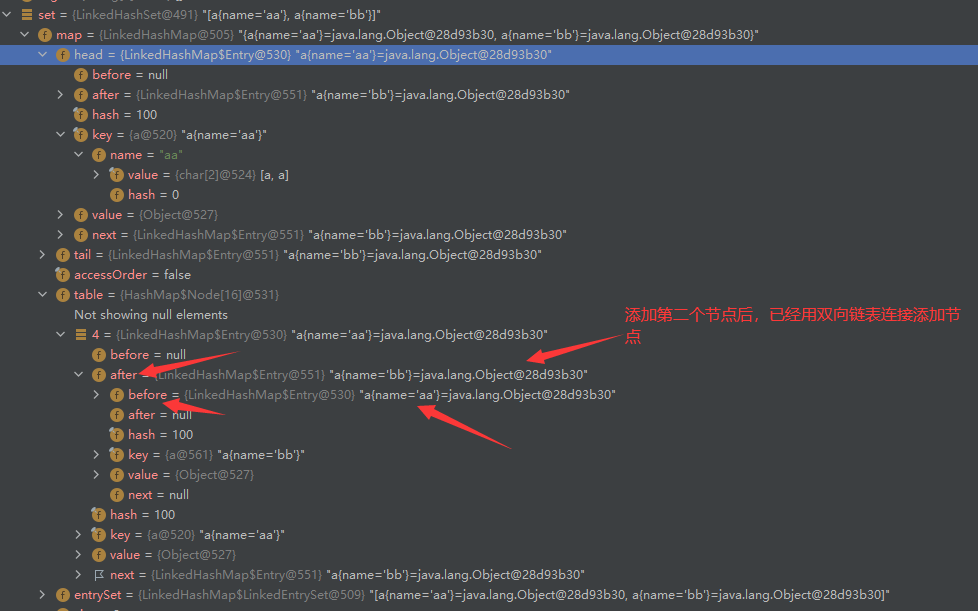
LinkedHashMap,繼承自HashSet,但是由LinkedHashMap實作及陣列+雙向鏈表,因此具有LinkedHashMap的特點
-
有序,由雙向鏈表維護添加順序,即存取順序一致
-
其他特點與LinkedHashMap相同,key唯一,key可為null
-
區別:

-
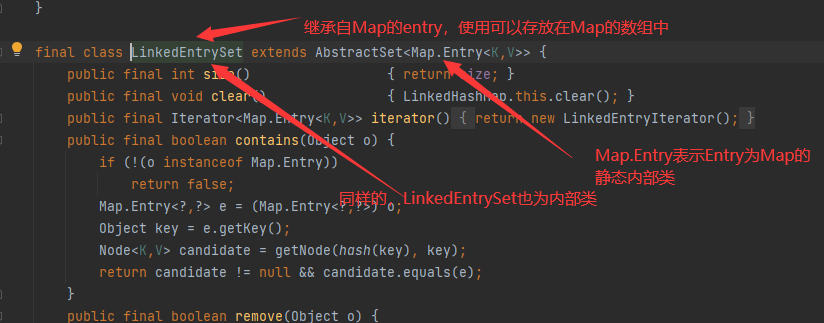
LinkedHashMap陣列存放的節點為LinkedEntry,$表示內部類,
-
-
TreeSet
-
無序,存取順序不一致,其他特點于TreeMap相同
-
實作了NavigableSet和SortedSet介面,可以使用Comparator的compareTo方法進行排序
-
HashSet,LinkedHashSet,TreeSet的區別:
HashSet,添加查詢快性能優于后兩者,LinkedHashSet添加修改洗掉快,有序
TreeSet只有在需要對元素進行排序時使用
-
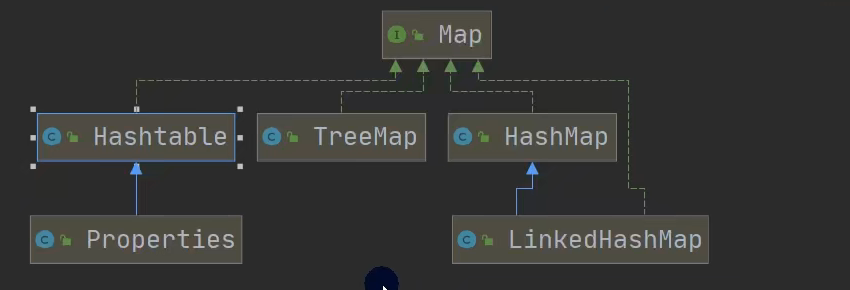
Map
-
Map的遍歷
-
基于EntrySet機制,可以分別拿到所有單獨的Key或所有Value,以及k-v,
Hashmap map = new HashMap(); Set entrySet = map.entrySet(); Collection values = map.values(); Set keySet = map.keySet(); //example for(Object key : keySet) { System.out.println(key); } -
可以使用增強for/迭代器Iterator來遍歷指定的集合(keyset,values,entryset)
-
-
HashMap,基于陣列與鏈表(JDK1.7)/鏈表+紅黑樹(JDK1.8)實作,初始容量16,增刪改查快
-
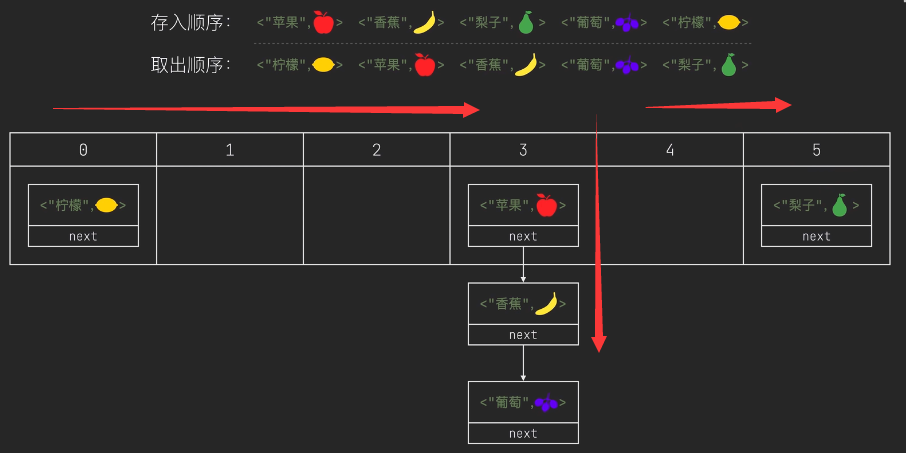
無序,key可以為null但只能有一個,并且hash值為0,key不可以重復,value可以重復,以鍵值對的形式存盤,會被封裝到HashMap$Node中,元素的下標由資料的hash值&(陣列容量-1)得到,因此存放的順序是無序的,如果有重復的值則會覆寫,
-
Map介面的特點:key-value會以Node型別存放,但是為了方便遍歷會創建EntrySet集合,該集合存放的型別為Entry,即 transient Set<Map.Entry<K,V>> entrySet; 然而entrySet中定義的型別是Map.Entry,但實際上存放的仍是Node,因為Node實作了Entry介面,之所以能夠存放進EntrySet中是此處是做了向下轉型的操作,并且資料只會存放一份在Node中,EntrySet存放的是參考,(先看圖再看文字)
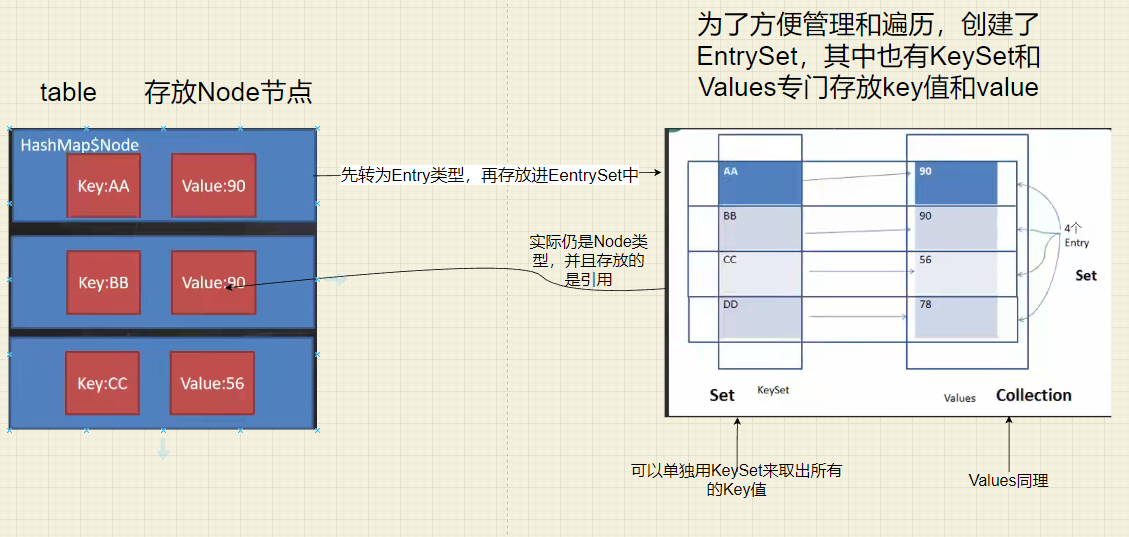
-
哈希沖突,當同一個下標有多個資料時,會以鏈表的形式存放資料
- 樹(紅黑樹)化,當鏈表長度大于8且陣列容量大于64時,鏈表會轉化為紅黑樹(自平衡二叉樹),以此提高查詢速度,新增資料時需要計算節點的位置
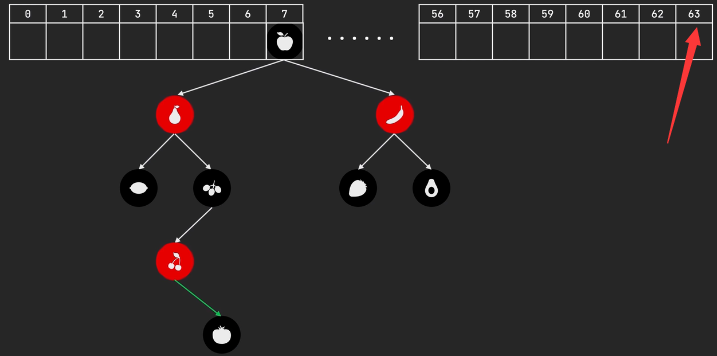
- 鏈化,當紅黑樹中的節點小等于6時,樹將轉化為鏈表,因為此時節點數很少,用紅黑樹查詢的速度不比鏈表快,并且在新增元素的適合,鏈表不需要計算節點的位置,可以直接插入隊尾,
- 樹(紅黑樹)化,當鏈表長度大于8且陣列容量大于64時,鏈表會轉化為紅黑樹(自平衡二叉樹),以此提高查詢速度,新增資料時需要計算節點的位置
-
擴容,當元素個數超過臨界值時就需要擴容,臨界值 = 容量 * 負載因子(默認0.75),擴容后的容量是之前的兩倍
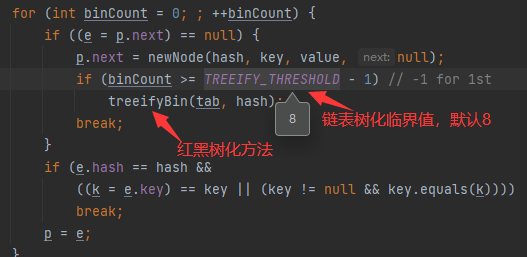
-
-
LinkedHashMap,繼承自HashMap,用雙向鏈表解決了HashMap無序的問題,
- 有序,key唯一,key可為null
- 維護的元素排序順序:默認維護添加順序
- 添加順序,元素添加和取出的順序一致,頭節點為第一個元素,尾節點為最后一個元素
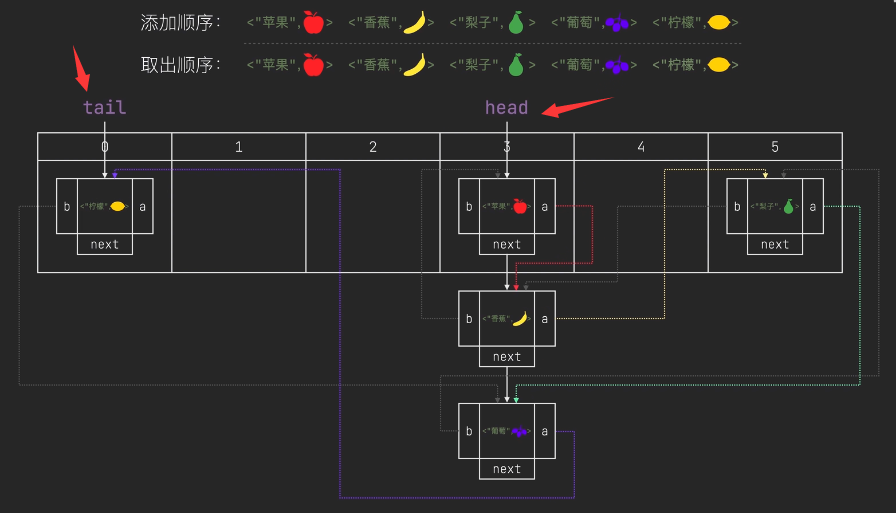
- 訪問順序,用get訪問某元素,則該元素為尾節點,該元素的next節點為頭節點
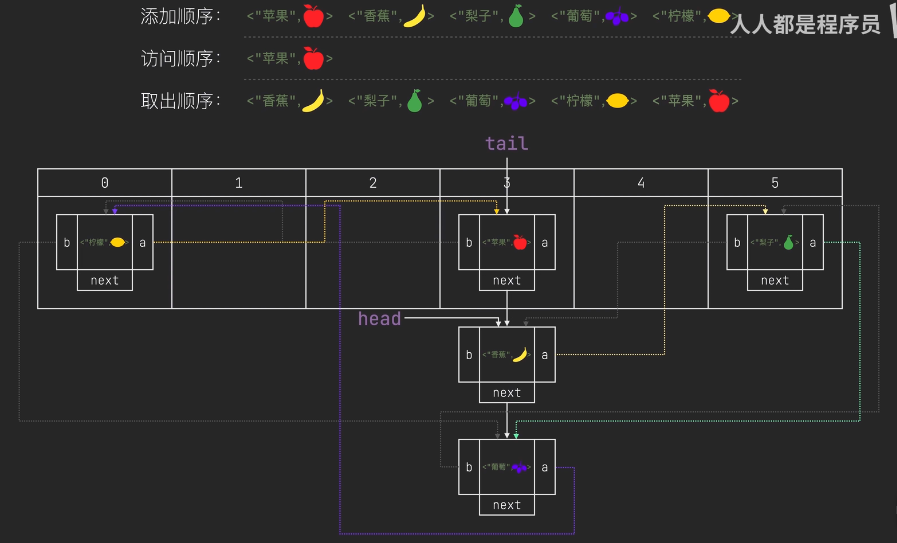
- 添加順序,元素添加和取出的順序一致,頭節點為第一個元素,尾節點為最后一個元素
-
TreeMap,基于紅黑樹實作的Map,
-
無序并會對key排序,key唯一,key不可以為null,因為紅黑樹是自平衡二叉樹,會先比較,而null不能比較,會拋出NullPointerException,
-
可以自定義的比較器來排序,put流程原始碼如下圖
TreeMap<Object, Object> treeMap = new TreeMap<>(new Comparator<Object>() { @Override public int compare(Object o1, Object o2) { return ((String)o1).length() - ((String)o2).length(); } }); treeMap.put("aa","aa"); treeMap.put("1213","3"); treeMap.put("z","aa");
-
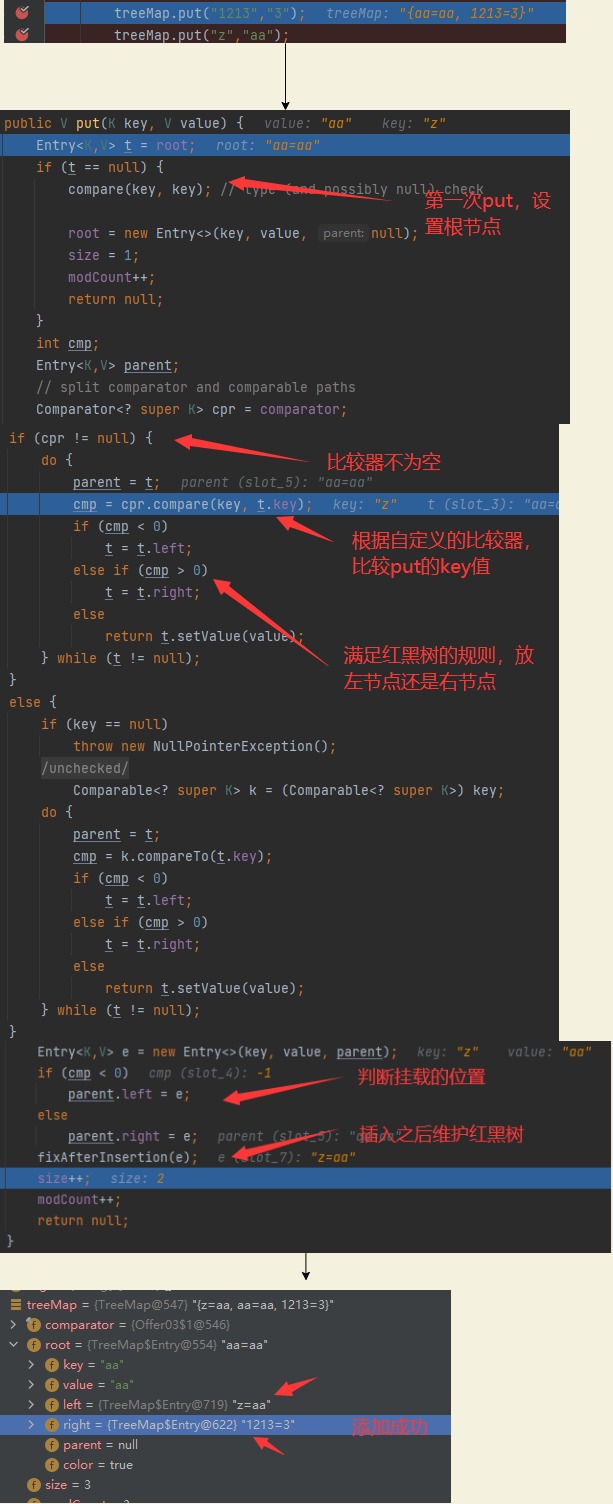
-
紅黑樹的特點,在插入時依次先比較,然后再根據規則左右旋,

-
Hashtable,繼承Dictionary<K,V> 實作了Map<K,V>
-
初始化大小是11,負載因子為0.75,擴容按自己的機制來
-
Key和Value都不能為null,否則會拋出空指標例外
-
是執行緒安全的,hashMap是執行緒不安全的
-
-
Properties,繼承自Hashtable,實作了Map介面,也是K-V形式
- 通常用于組態檔
List
-
ArraysList,基于陣列實作,默認容量為10,擴容時會先創建一個原始1.5倍的陣列,然后再把元素復制過去,特點:
- 有序,可存重復元素,可存null
- 查詢快,增刪慢,適合查詢較多的場景
- 如果使用無參構造器,則初始elementData容量為0,第一次添加時則擴容為10,如需再次擴容,則擴容1.5倍
- 如果使用指定大小的構造器,則初始elementData為指定大小,擴容仍為1.5倍,
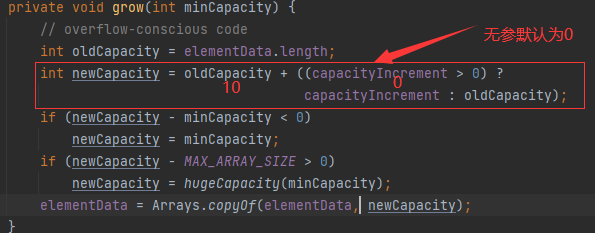
add方法,擴容機制,原始碼和流程分析
public static void main(String[] args) { ArrayList<Object> list = new ArrayList<>(); for (int i = 0; i < 10; i++) { list.add(i); } list.add(11); list.add(12); }創建ArrayList,回圈添加元素,因為初始容量為10,當添加11時會擴容,觀察原始碼執行情況,
- 先進入int的自動裝箱
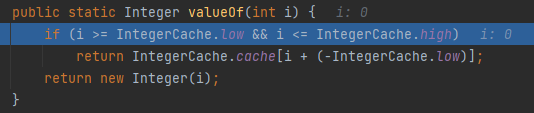
- 進入add方法,注意此時的size為0
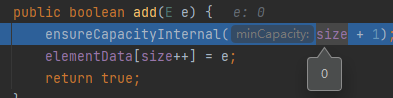
- 呼叫ensureCapacityInternal方法,這里分為了三步計算容量
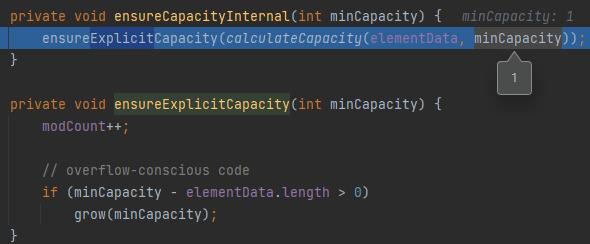
- 計算容量,回傳minCapacity,初始值為10

- modCount標記修改次數,在需要考慮執行緒安全時起作用,if判斷當前容量是否進行擴容
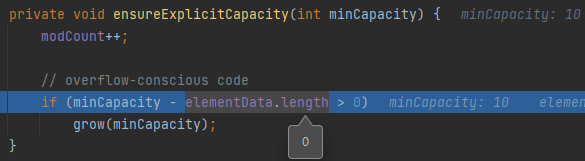
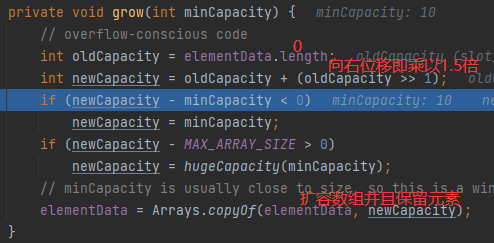
- 呼叫Grow方法,第一個if保證初次擴容時,容量為10,擴容后回傳
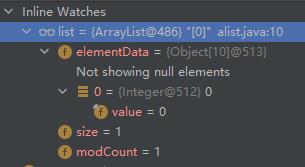
- 添加成功
-
LinkedList,基于雙向鏈表實作,增加則直接在尾部插入
- 有序,可存重復元素,可存null
- 查詢慢,增刪快,適合增刪較多的場景
- 和ArraysList相比需要記錄前后節點,所以記憶體消耗比ArraysList大
-
Vector,執行緒安全的,效率不高,無參構造默認是10,2倍擴容
fail-fast快速失敗機制
-
為了避免多個執行緒對同一容器并發修改時造成的資料例外,
-
實作機制:在容器類種定義一個modCount屬性,記錄容器修改的次數,當容器有添加或洗掉的操作modCount就++,在迭代的時候比較,如果不相同說明有多個執行緒同時修改,則拋出ConcurrentModificationException例外,
-
采用執行緒安全的容器即可避免并發的問題,
執行緒不安全 執行緒安全 ArrayList CopyOnWriteArrayList HashMap ConcurrentHashMap HashSet CopyOnWriteArraySet -
執行緒安全容器ConcurrentHashMap
- 同步,僅對頭節點加鎖,因此并發度為陣列容量
- 統計元素個數,為了解決執行緒安全問題,使用CAS(compare and swap)演算法,同一時刻只允許一個執行緒更新個數,其余執行緒更新失敗,失敗的執行緒再回圈更新直到成功為止,但這樣效率也很低,因此讓更新失敗的執行緒先把值累加到陣列中,最后的個數由baseCount和CounterCell陣列累加
- 多執行緒協同擴容,每個執行緒負責一段步長的資料遷移,
- key,value不為null,避免出現不知道是拿出來value為null還是key根本不存在,
- 只針對位置加鎖
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/497686.html
標籤:Java