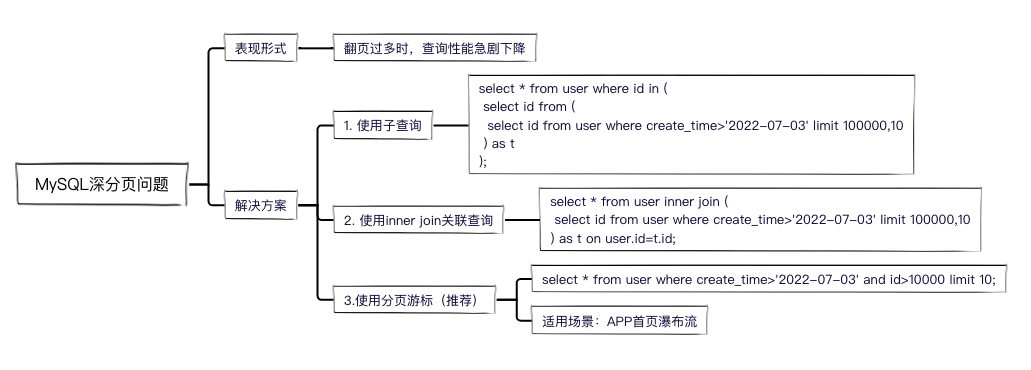
開發經常遇到分頁查詢的需求,但是當翻頁過多的時候,就會產生深分頁,導致查詢效率急劇下降,
有沒有什么辦法,能解決深分頁的問題呢?
本文總結了三種優化方案,查詢效率直接提升10倍,一起學習一下,
1. 準備資料
先創建一張用戶表,只在create_time欄位上加索引:
CREATE TABLE `user` (
`id` int NOT NULL AUTO_INCREMENT COMMENT '主鍵',
`name` varchar(255) DEFAULT NULL COMMENT '姓名',
`create_time` timestamp NULL DEFAULT NULL COMMENT '創建時間',
PRIMARY KEY (`id`),
KEY `idx_create_time` (`create_time`)
) ENGINE=InnoDB COMMENT='用戶表';
然后往用戶表中插入100萬條測驗資料,這里可以使用存盤程序:
drop PROCEDURE IF EXISTS insertData;
DELIMITER $$
create procedure insertData()
begin
declare i int default 1;
while i <= 100000 do
INSERT into user (name,create_time) VALUES (CONCAT("name",i), now());
set i = i + 1;
end while;
end $$
call insertData() $$
2. 驗證深分頁問題
每頁10條,當我們查詢第一頁的時候,速度很快:
select * from user
where create_time>'2022-07-03'
limit 0,10;
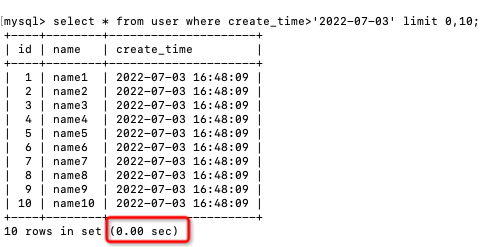
在不到0.01秒內直接回傳了,所以沒顯示出執行時間,
當我們翻到第10000頁的時候,查詢效率急劇下降:
select * from user
where create_time>'2022-07-03'
limit 100000,10;
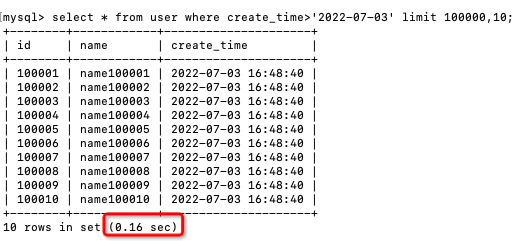
執行時間變成了0.16秒,性能至少下降了幾十倍,
耗時主要花在哪里了?
- 需要掃描前10條資料,資料量較大,比較耗時
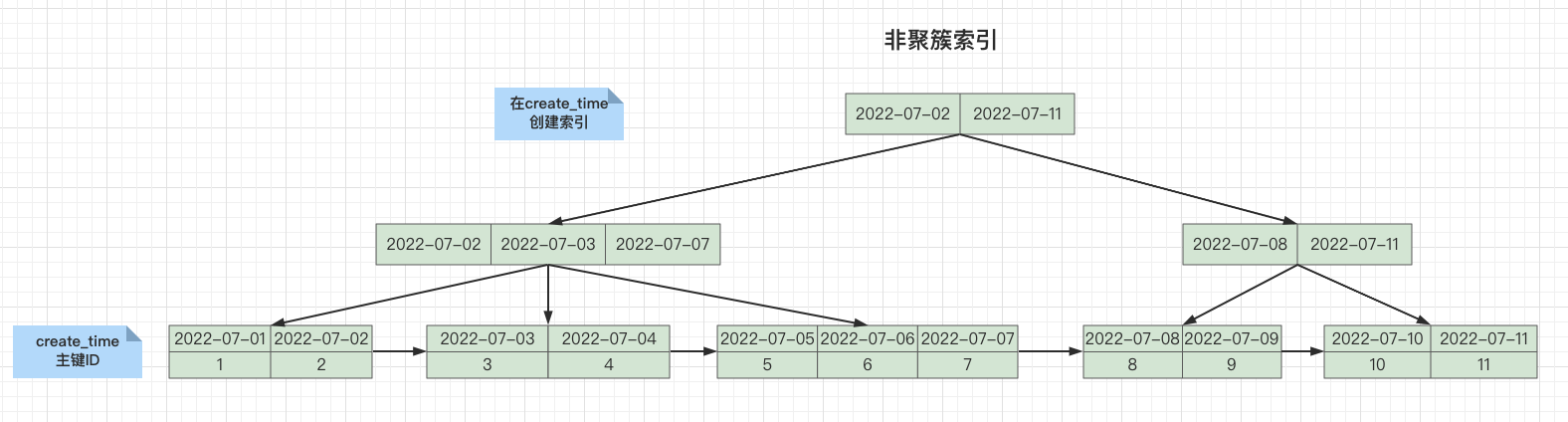
- create_time是非聚簇索引,需要先查詢出主鍵ID,再回表查詢,通過主鍵ID查詢出所有欄位
畫一下回表查詢流程:
1. 先通過create_time查詢出主鍵ID
2. 再通過主鍵ID查詢出表中所有欄位
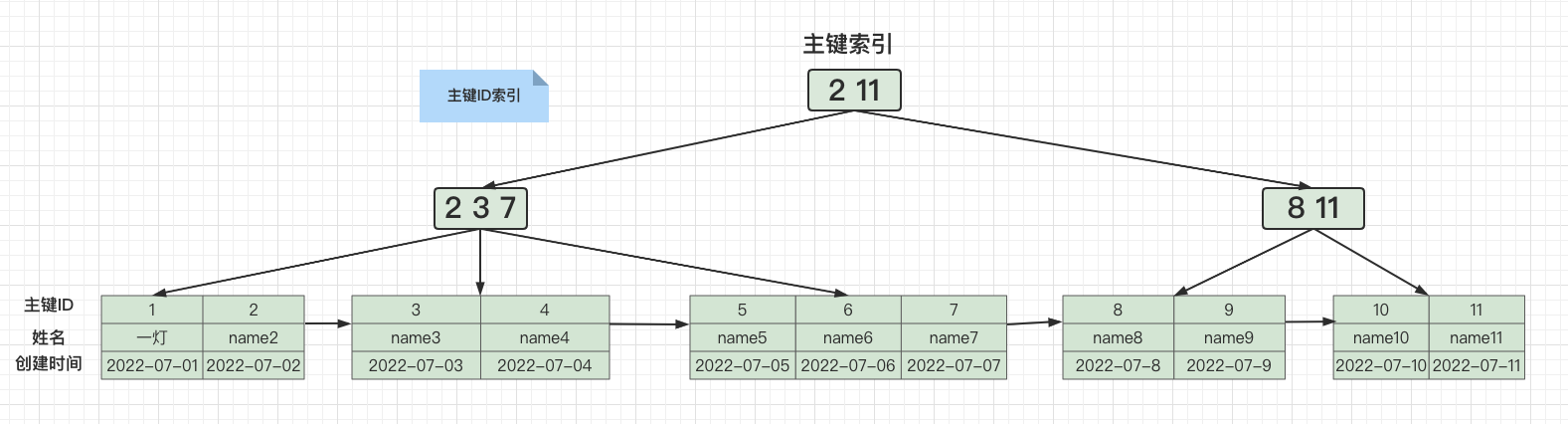
別問為什么B+樹的結構是這樣的?問就是規定,
可以看一下前兩篇文章,
MySQL索引底層實作為什么要用B+樹?
一篇文章講清楚MySQL的聚簇/聯合/覆寫索引、回表、索引下推
然后我們就針對這兩個耗時原因進行優化,
3. 優化查詢
3.1 使用子查詢
先用子查詢查出符合條件的主鍵,再用主鍵ID做條件查出所有欄位,
select * from user
where id in (
select id from user
where create_time>'2022-07-03'
limit 100000,10
);
不過這樣查詢會報錯,說是子查詢中不支持使用limit,

我們加一層子查詢嵌套,就可以了:
select * from user
where id in (
select id from (
select id from user
where create_time>'2022-07-03'
limit 100000,10
) as t
);

執行時間縮短到0.05秒,減少了0.12秒,相當于查詢性能提升了3倍,
為什么先用子查詢查出符合條件的主鍵ID,就能縮短查詢時間呢?
我們用explain查看一下執行計劃就明白了:
explain select * from user
where id in (
select id from (
select id from user
where create_time>'2022-07-03'
limit 100000,10
) as t
);

可以看到Extra列顯示子查詢中用到Using index,表示用到了覆寫索引,所以子查詢無需回表查詢,加快了查詢效率,
3.2 使用inner join關聯查詢
把子查詢的結果當成一張臨時表,然后和原表進行關聯查詢,
select * from user
inner join (
select id from user
where create_time>'2022-07-03'
limit 100000,10
) as t on user.id=t.id;
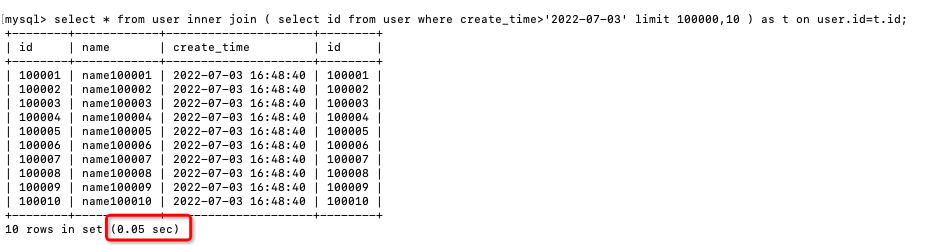
查詢性能跟使用子查詢一樣,
3.3 使用分頁游標(推薦)
實作方式就是:當我們查詢第二頁的時候,把第一頁的查詢結果放到第二頁的查詢條件中,
例如:首先查詢第一頁
select * from user
where create_time>'2022-07-03'
limit 10;
然后查詢第二頁,把第一頁的查詢結果放到第二頁查詢條件中:
select * from user
where create_time>'2022-07-03' and id>10
limit 10;
這樣相當于每次都是查詢第一頁,也就不存在深分頁的問題了,推薦使用,
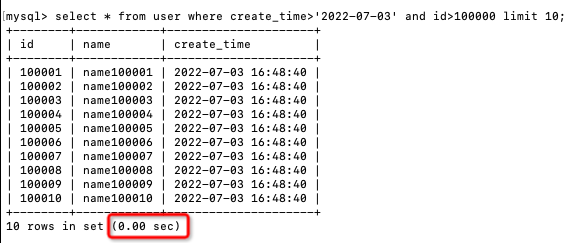
執行耗時是0秒,查詢性能直接提升了幾十倍,
這樣的查詢方式雖然好用,但是又帶來一個問題,就是無法跳轉到指定頁數,只能一頁頁向下翻,
所以這種查詢只適合特定場景,比如資訊類APP的首頁,
互聯網APP一般采用瀑布流的形式,比如百度首頁、頭條首頁,都是一直向下滑動翻頁,并沒有跳轉到制定頁數的需求,
不信的話,可以看一下,這是頭條的瀑布流:
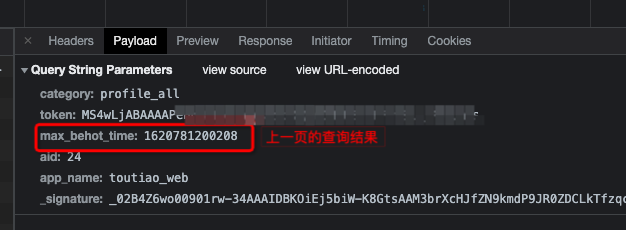
傳參中帶了上一頁的查詢結果,
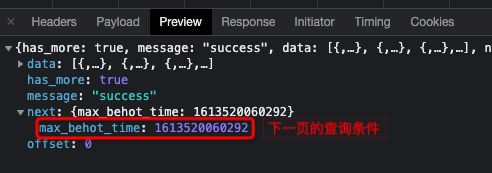
回應資料中,回傳了下一頁查詢條件,
所以這種查詢方式的應用場景還是挺廣的,趕快用起來吧,
知識點總結:
文章持續更新,可以微信搜一搜「 一燈架構 」第一時間閱讀更多技術干貨,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/498479.html
標籤:Java