1、ElasticSearch簡介
1.1 Lucene
- Doug Cutting開發
- 是apache軟體基金會4 jakarta專案組的一個子專案
- 是一個開放源代碼的全文檢索引擎工具包
- 不是一個完整的全文檢索引擎,而是一個全文檢索引擎的架構,提供了完整的查詢引擎和索引引擎,部分文本分析引擎(英文與德文兩種西方語言)
- 當前以及最近幾年最受歡迎的免費Java資訊檢索程式庫,
Lucene和ElasticSearch的關系:
- ElasticSearch是基于Lucene 做了一下封裝和增強
1.2 ElasticSearch 概述
官網:https://www.elastic.co/cn/downloads/elasticsearch
Elaticsearch,簡稱為es,es是一個開源的高擴展的分布式全文檢索引擎,它可以近乎實時的存盤、檢索資料;本身擴展性很好,可以擴展到上百臺服務器,處理PB級別(大資料時代)的資料,es也使用java開發并使用Lucene作為其核心來實作所有索引和搜索的功能,但是它的目的是通過簡單的RESTful API來隱藏Lucene的復雜性,從而讓全文搜索變得簡單,
據國際權威的資料庫產品評測機構DB Engines的統計,在2016年1月,ElasticSearch已超過Solr等,成為排名第一的搜索引擎類應用,
ELK技術: elasticsearch+logstash+kibana
1.3 ES和Solr
1.3.1 ElasticSearch簡介
- Elasticsearch是一個實時分布式搜索和分析引擎, 它讓你以前所未有的速度處理大資料成為可能,
- 它用于全文搜索、結構化搜索、分析以及將這三者混合使用:
維基百科使用Elasticsearch提供全文搜索并高亮關鍵字,以及輸入實時搜索(search-asyou-type)和搜索糾錯(did-you-mean)等搜索建議功能,英國衛報使用Elasticsearch結合用戶日志和社交網路資料提供給他們的編輯以實時的反饋,以便及時了解公眾對新發表的文章的回應,StackOverflow結合全文搜索與地理位置查詢,以及more-like-this功能來找到相關的問題和答案,Github使用Elasticsearch檢索1300億行的代碼,- 但是Elasticsearch不僅用于大型企業,它還讓像
DataDog以及Klout這樣的創業公司將最初的想法變成可擴展的解決方案, - Elasticsearch可以在你的筆記本上運行,也可以在數以百計的服務器上處理PB級別的資料,
- Elasticsearch是一個基于Apache Lucene(TM)的開源搜索引擎,無論在開源還是專有領域, Lucene可被認為是迄今為止最先進、性能最好的、功能最全的搜索引擎庫,
- 但是, Lucene只是一個庫, 想要使用它,你必須使用Java來作為開發語言并將其直接集成到你的應用中,更糟糕的是, Lucene非常復雜,你需要深入了解檢索的相關知識來理解它是如何作業的,
- Elasticsearch也使用Java開發并使用Lucene作為其核心來實作所有索引和搜索的功能,但是它的目的是通過簡單的RESTful API來隱藏Lucene的復雜性,從而讓全文搜索變得簡單,
1.3.2 Solr簡介
- Solr是Apache下的一個頂級開源專案,采用Java開發,它是基于Lucene的全文搜索服務器,Solr提供了比Lucene更為豐富的查詢語言,同時實作了可配置、可擴展,并對索引、搜索性能進行了優化
- Solr可以獨立運行,運行在letty. Tomcat等這些Selrvlet容器中 , Solr 索引的實作方法很簡單,用POST方法向Solr服務器發送一個描述Field及其內容的XML檔案, Solr根據xml檔案添加、洗掉、更新索引,Solr 搜索只需要發送HTTP GET請求,然后對Solr回傳xml、json等格式的查詢結果進行決議,組織頁面布局,
- Solr不提供構建UI的功能, Solr提供了一個管理界面,通過管理界面可以查詢Solr的配置和運行情況,
- Solr是基于lucene開發企業級搜索服務器,實際上就是封裝了lucene.
- Solr是一個獨立的企業級搜索應用服務器,它對外提供類似于Web-service的API介面,用戶可以通過http請求,向搜索引擎服務器提交-定格式的檔案,生成索引;也可以通過提出查找請求,并得到回傳結果,
1.3.3 ElasticSearch與Solr比較
當單純的對已有資料進行搜索時,Solr更快
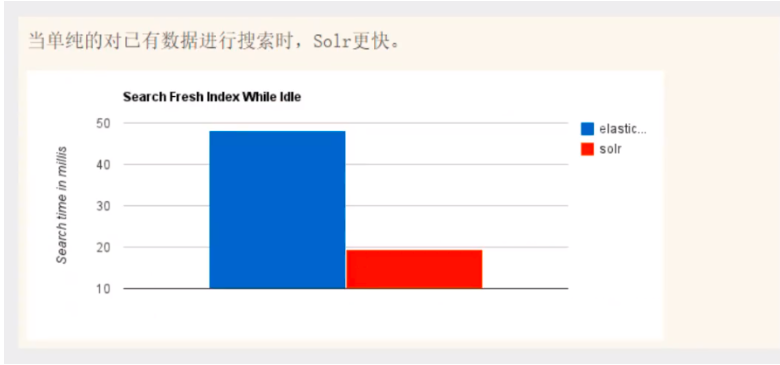
2.當實時建立索引時,Solr會產生io阻塞,查詢性能較差,ElasticSearch具有明顯的優勢
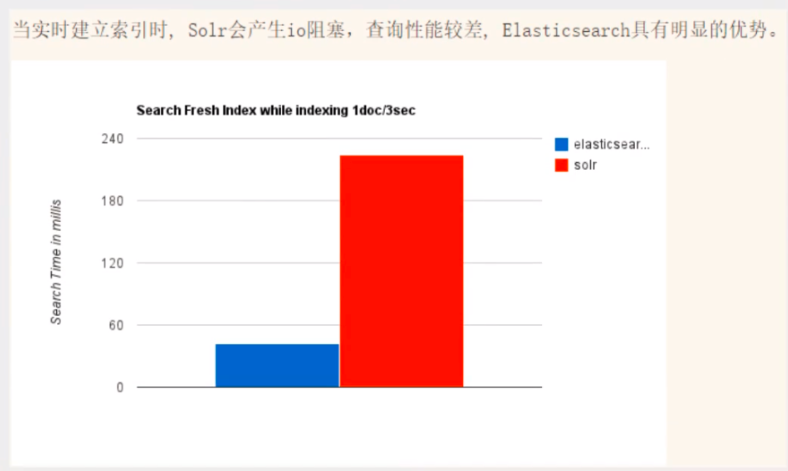
3.隨著資料量的增加,Solr的搜索效率會變得更低,而ElasticSearch卻沒有明顯的變化
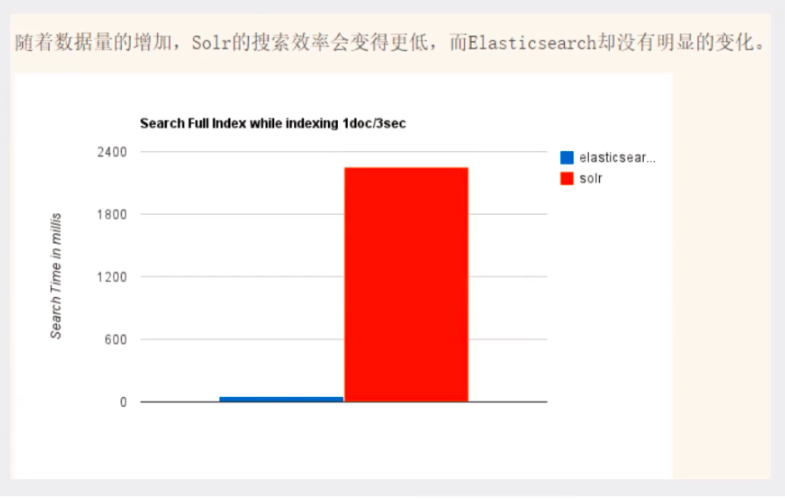
4.轉變我們的搜索基礎設施后從Solr ElasticSearch,我們看見一個即時~ 50x提高搜索性能!
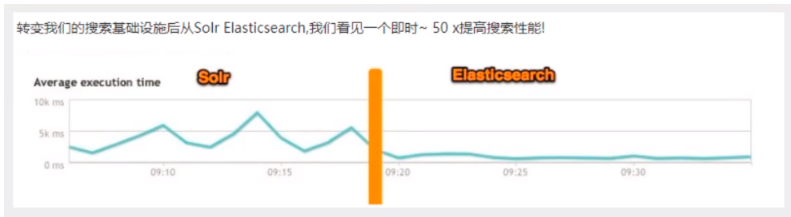
1.3.4 總結
1、es基本是開箱即用(解壓就可以用!) ,非常簡單,Solr安裝略微復雜一丟丟!
2、Solr 利用Zookeeper進行分布式管理,而Elasticsearch自身帶有分布式協調管理功能,
3、Solr 支持更多格式的資料,比如JSON、XML、 CSV ,而Elasticsearch僅支持json檔案格式,
4、Solr 官方提供的功能更多,而Elasticsearch本身更注重于核心功能,高級功能多有第三方插件提供,例如圖形化界面需要kibana友好支撐
5、Solr 查詢快,但更新索引時慢(即插入洗掉慢) ,用于電商等查詢多的應用;
- ES建立索引快(即查詢慢) ,即實時性查詢快,用于facebook新浪等搜索,
- Solr是傳統搜索應用的有力解決方案,但Elasticsearch更適用于新興的實時搜索應用,
6、Solr比較成熟,有一個更大,更成熟的用戶、開發和貢獻者社區,而Elasticsearch相對開發維護者較少,更新太快,學習使用成本較高,
2、ElasticSearch安裝
JDK8,最低要求;
使用Java開發,必須保證ElasticSearch的版本與Java的核心jar包版本對應!(Java環境保證沒錯)
2.1 ElasticSearch
2.1.1 下載
ElasticSearch下載地址:https://mirrors.huaweicloud.com/elasticsearch/7.6.1
下載完解壓即可;
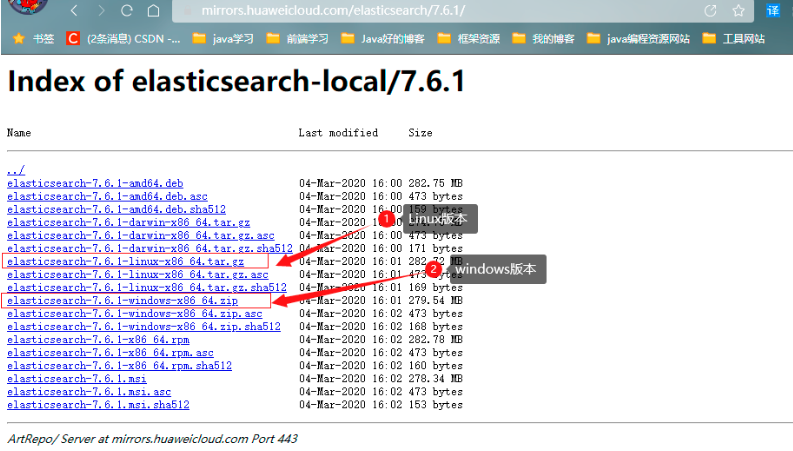
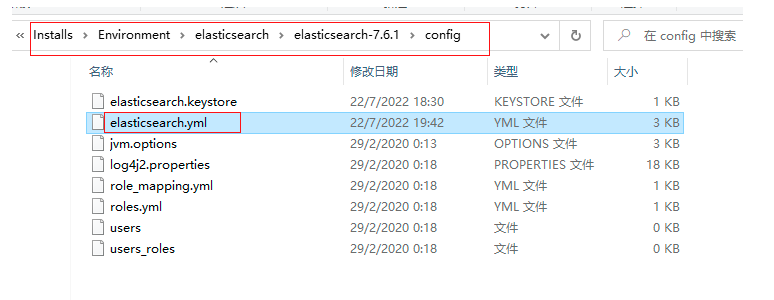
2.1.2 熟悉目錄
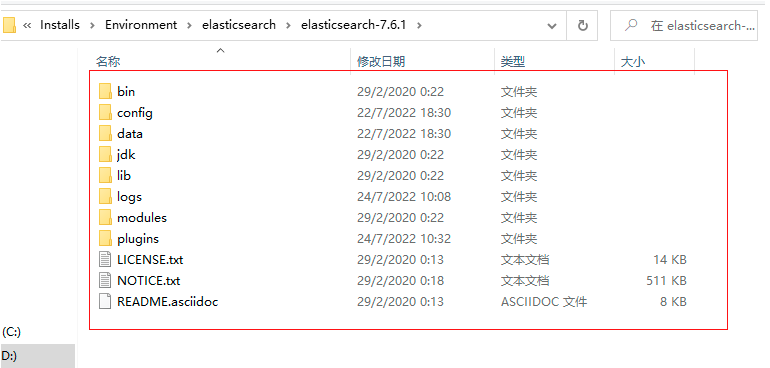
bin 啟動檔案目錄
config 組態檔目錄
1og4j2 日志組態檔
jvm.options java 虛擬機相關的配置(默認啟動占1g記憶體,內容不夠需要自己調整)
elasticsearch.ym1 elasticsearch 的組態檔! 默認9200埠!跨域!
1ib
相關jar包
modules 功能模塊目錄
plugins 插件目錄
ik分詞器
2.1.3 啟動
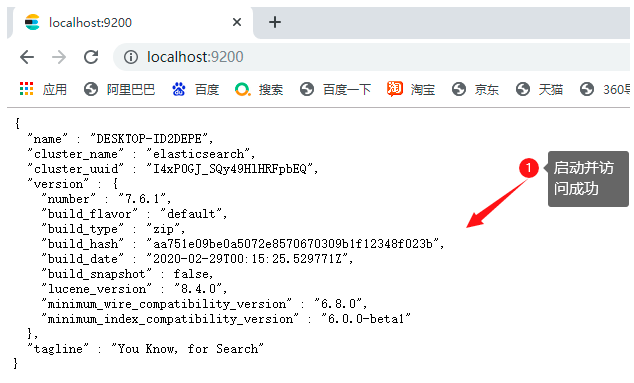
1.點擊:elasticsearch.bat
2.訪問地址:127.0.0.1:9200
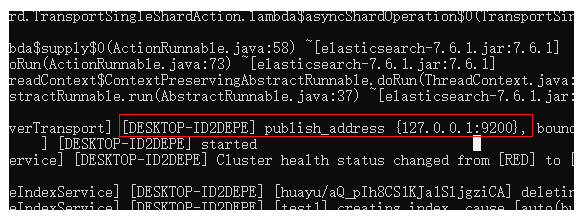
3.訪問測驗成功
2.2 安裝elasticsearch-head可視化界面
elasticsearch-head
使用前提:需要安裝node.js
2.2.1 下載
elasticsearch-head下載地址:https://github.com/mobz/elasticsearch-head/archive/master.zip
下載完解壓即可;
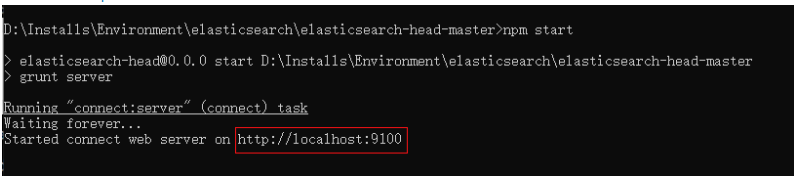
2.2.2安裝依賴與啟動
cd elasticsearch-head
# 安裝依賴
npm install
# 啟動
npm run start
# 訪問
http://localhost:9100/
訪問地址:http://loacalhost:9100
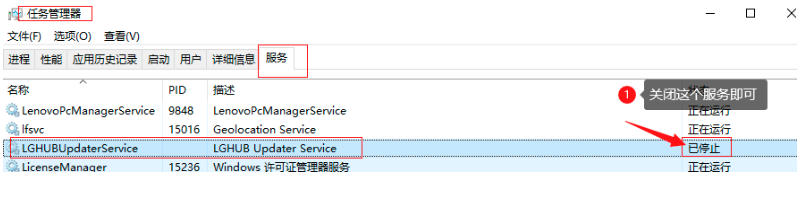
使用羅技滑鼠插件的可能會占用9100埠
關閉LGHUBUpdateService服務即可;或者修改elasticsearch-head的埠,反正兩個不用埠沖突就好;
2.2.3訪問
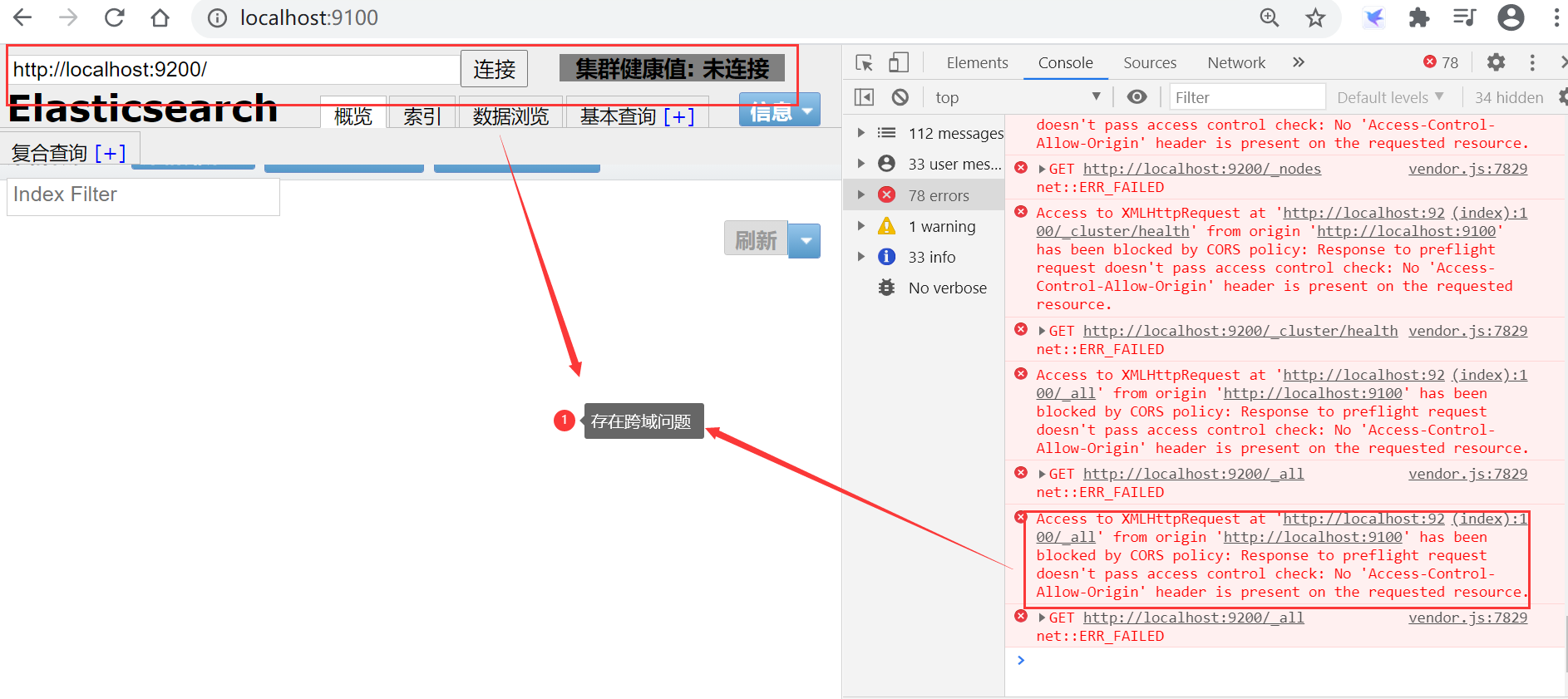
存在跨域問題(只有當兩個頁面同源,才能互動);
同源(埠,主機,協議三者都相同);
開啟跨域(在elasticsearch解壓目錄config下elasticsearch.yml中添加)
# 開啟跨域
http.cors.enabled: true
# 所有人訪問
http.cors.allow-origin: "*"
再次連接,連接成功
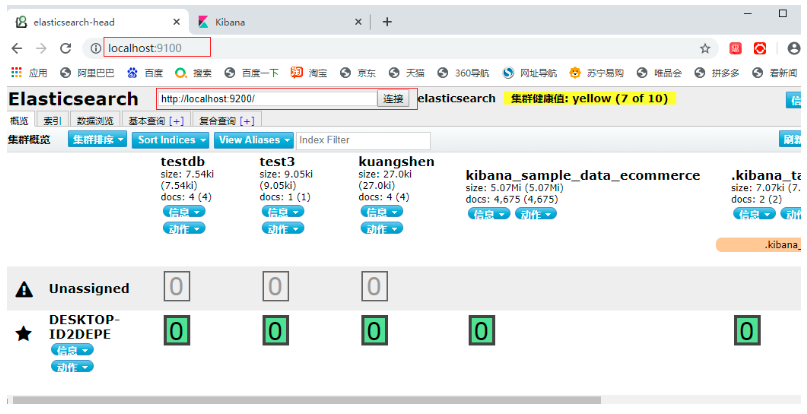
如何理解上圖:
-
如果你是初學者
- 索引 可以看做 “資料庫”
- 型別 可以看做 “表”
- 檔案 可以看做 “庫中的資料(表中的行)”
-
這個head,我們只是把它當做可視化資料展示工具,之后所有的查詢都在kibana中進行
- 因為不支持json格式化,不方便
2.3安裝 kibana
Kibana是一個針對ElasticSearch的開源分析及可視化平臺,用來搜索、查看互動存盤在Elasticsearch索引中的資料,使用Kibana ,可以通過各種圖表進行高級資料分析及展示,Kibana讓海量資料更容易理解,它操作簡單,基于瀏覽器的用戶界面可以快速創建儀表板( dashboard )實時顯示Elasticsearch查詢動態,設置Kibana非常簡單,無需編碼或者額外的基礎架構,幾分鐘內就可以完成Kibana安裝并啟動Elasticsearch索引監測,
2.3.1 下載
kibana下載地址:https://mirrors.huaweicloud.com/kibana/7.6.1/
下載后解壓即可;
2.3.2 啟動
點擊kibana.bat;
訪問:http://localhost:5601

訪問成功
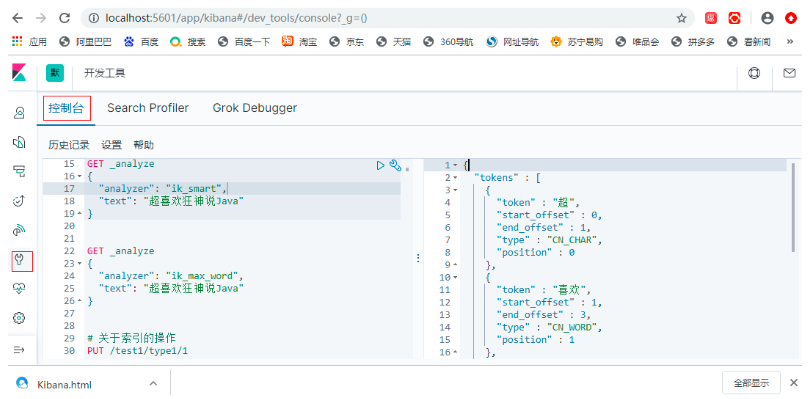
2.3.3 控制臺
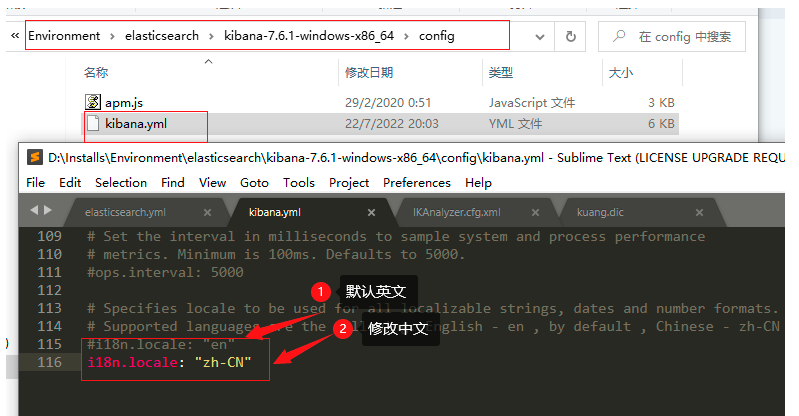
2.3.4kibana 漢化
編輯器打開kibana解壓目錄/config/kibana.yml,添加 i18n.locale: "zh-CN"
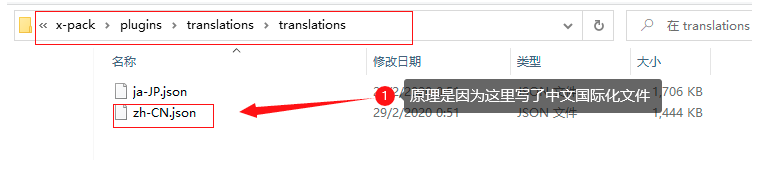
zh-CH.json檔案
2.3.5 了解ELK
-
ELK是
-
Elasticsearch、Logstash、 Kibana三大開源框架首字母大寫簡稱
-
市面上也被成為Elastic Stack,
- 其中Elasticsearch是一個基于Lucene、分布式、通過Restful方式進行互動的近實時搜索平臺框架,
- 像類似百度、谷歌這種大資料全文搜索引擎的場景都可以使用Elasticsearch作為底層支持框架,可見Elasticsearch提供的搜索能力確實強大,市面上很多時候我們簡稱Elasticsearch為es,
- Logstash是ELK的中央資料流引擎,用于從不同目標(檔案/資料存盤/MQ )收集的不同格式資料,經過過濾后支持輸出到不同目的地(檔案/MQ/redis/elasticsearch/kafka等),
- Kibana可以將elasticsearch的資料通過友好的頁面展示出來 ,提供實時分析的功能,
-
-
市面上很多開發只要提到ELK能夠一致說出它是一個日志分析架構技術堆疊總稱 ,但實際上ELK不僅僅適用于日志分析,它還可以支持其它任何資料分析和收集的場景,日志分析和收集只是更具有代表性,并非唯一性,
收集清洗資料(Logstash) ==> 搜索、存盤(ElasticSearch) ==> 展示(Kibana)
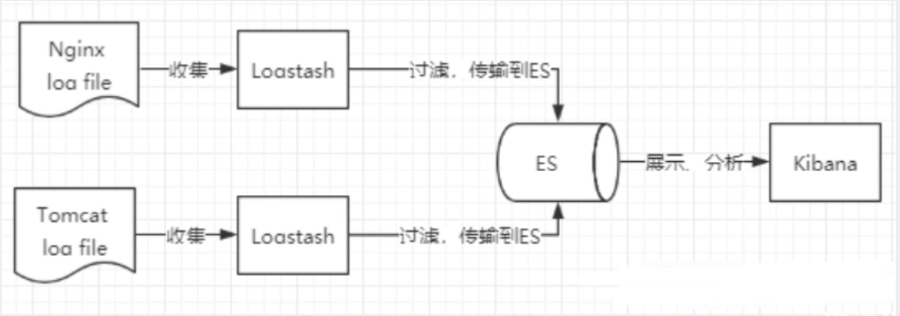
3、ElasticSearch核心概念
3.1 概述
- 索引
- 包含多個分片
- 欄位型別(mapping)
- 檔案(documents)
- 分片(Lucence索引,倒排索引)
集群,節點,索引,型別,檔案,分片,映射是什么?
3.2 關系行資料庫和ElasticSearch客觀對比
ElasticSearch是面向檔案,關系行資料庫和ElasticSearch客觀對比!一切都是JSON!
| Relational DB | ElasticSearch |
|---|---|
| 資料庫(database) | 索引(indices) |
| 表(tables) | types <慢慢會被棄用!> |
| 行(rows) | documents |
| 欄位(columns) | fields |
elasticsearch(集群)中可以包含多個索引(資料庫) ,每個索引中可以包含多個型別(表) ,每個型別下又包含多個檔案(行) ,每個檔案中又包含多個欄位(列),
3.3 物理設計:
elasticsearch在后臺把每個索引劃分成多個分片,每分分片可以在集群中的不同服務器間遷移
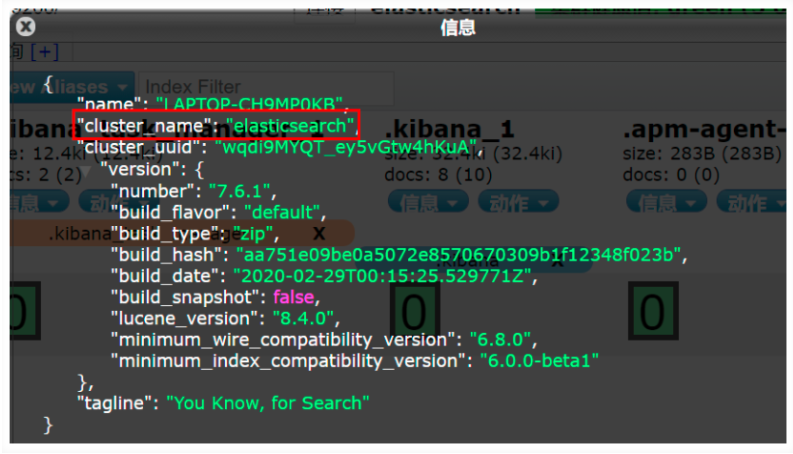
一個人就是一個集群! ,即啟動的ElasticSearch服務,默認就是一個集群,且默認集群名為elasticsearch;
3.4 邏輯設計:
一個索引型別中,包含多個檔案,比如說檔案1,檔案2,當我們索引一篇檔案時,可以通過這樣的順序找到它:索引 => 型別 => 檔案ID ,通過這個組合我們就能索引到某個具體的檔案, 注意:ID不必是整數,實際上它是個字串,
3.4.1 檔案(”行“)
之前說elasticsearch是面向檔案的,那么就意味著索引和搜索資料的最小單位是檔案,elasticsearch中,檔案有幾個重要屬性:
- 自我包含,一篇檔案同時包含欄位和對應的值,也就是同時包含key:value !
- 可以是層次型的,一個檔案中包含自檔案,復雜的邏輯物體就是這么來的! {就是一個json物件 ! fastjson進行自動轉換 !}
- 靈活的結構,檔案不依賴預先定義的模式,我們知道關系型資料庫中,要提前定義欄位才能使用,在elasticsearch中,對于欄位是非常靈活的,有時候,我們可以忽略該欄位,或者動態的添加一個新的欄位,
盡管我們可以隨意的新增或者忽略某個欄位,但是,每個欄位的型別非常重要,比如一個年齡欄位型別,可以是字串也可以是整形,因為elasticsearch會保存欄位和型別之間的映射及其他的設定,這種映射具體到每個映射的每種型別,這也是為什么在elasticsearch中,型別有時候也稱為映射型別,
3.4.2 型別(“表”)
型別是檔案的邏輯容器,就像關系型資料庫一樣,表格是行的容器,型別中對于欄位的定義稱為映射,比如name映射為字串型別,我們說檔案是無模式的,它們不需要擁有映射中所定義的所有欄位,比如新增一個欄位,那么elasticsearch是怎么做的呢?
- elasticsearch會自動的將新欄位加入映射,但是這個欄位的不確定它是什么型別,elasticsearch就開始猜,如果這個值是18,那么elasticsearch會認為它是整形,但是elasticsearch也可能猜不對,所以最安全的方式就是提前定義好所需要的映射,這點跟關系型資料庫殊途同歸了,先定義好欄位,然后再使用,別整什么幺蛾子,
3.4.3 索引(“庫”)
引是映射型別的容器, elasticsearch中的索引是一個非常大的檔案集合, 索引存盤了映射型別的欄位和其他設定,然后它們被存盤到了各個分片上了,我們來研究下分片是如何作業的,
物理設計:節點和分片 如何作業
創建新索引
一個集群至少有一個節點,而一個節點就是一個elasricsearch行程,節點可以有多個索引默認的,如果你創建索引,那么索引將會有個5個分片(primary shard ,又稱主分片)構成的,每一個主分片會有一個副本(replica shard,又稱復制分片);

上圖是一個有3個節點的集群,可以看到主分片和對應的復制分片都不會在同一個節點內,這樣有利于某個節點掛掉了,資料也不至于丟失,實際上,一個分片是一個Lucene索引(一個ElasticSearch索引包含多個Lucene索引) ,一個包含倒排索引的檔案目錄,倒排索引的結構使得elasticsearch在不掃描全部檔案的情況下,就能告訴你哪些檔案包含特定的關鍵字,不過,等等,倒排索引是什么鬼?
3.4.3.1 倒排索引(Lucene索引底層)
簡單說就是 按(文章關鍵字,對應的檔案<0個或多個>)形式建立索引,根據關鍵字就可直接查詢對應的檔案(含關鍵字的),無需查詢每一個檔案,如下圖
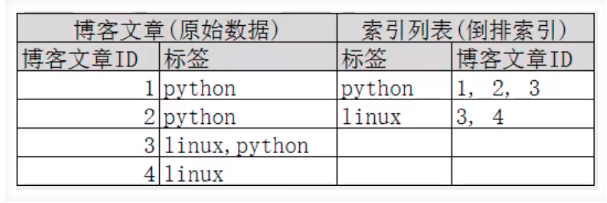
如果要搜索含有python標簽的文章,那相對于查找所有原資料而言,查找倒排索引后的資料將會快的多,只需要查看標簽這一欄,然后獲取相關的文章ID即可,完全過濾無關的所有資料,提高效率!
3.4.3.2 elasticsearch的索引和Lucene的索引對比
在elasticsearch中,索引(庫)這個詞被頻繁使用,這就是術語的使用,在elasticsearch中,索引被分為多個分片,每份 分片是 一個Lucence的索引,所以一個elasticsearch索引是 由多個Lucence索引組成的,別問問什么,因為elasticsearch的Lucence作為底層呢!,如無特指,說起索引都是指elasticsearch的索引,
4、IK分詞器(elasticsearch插件)
4.1 IK分詞器:中文分詞器
分詞:即把一段中文或者別的文字劃分成一個個的關鍵字,我們在搜索時候會把自己的資訊進行分詞,會把資料庫中或者索引庫中的資料進行分詞,然后進行一一個匹配操作,默認的中文分詞是將每個字看成一個詞(不使用用IK分詞器的情況下),比如“我愛狂神”會被分為”我”,”愛”,”狂”,”神” ,這顯然是不符合要求的,所以我們需要安裝中文分詞器ik來解決這個問題,
IK提供了兩個分詞演算法: ik_smart和ik_max_word ,其中ik_smart為最少切分, ik_max_word為最細粒度劃分!
4.2 下載
elasticsearch-analysis-ik下載地址:https://github.com/medcl/elasticsearch-analysis-ik/releases/tag/v7.6.1
下載后解壓到ElasticSearch的plugins目錄ik(自己添加一個名為ik的檔案夾)檔案夾下:
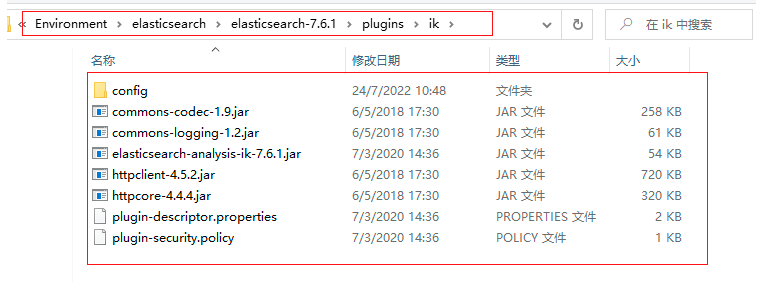
4.3 重啟ElasticSearch
加載了IK分詞器

4.4 elasticsearch-plugin list 命令 查看插件

4.5 使用kibana測驗
4.5.1 查看不同的分詞效果
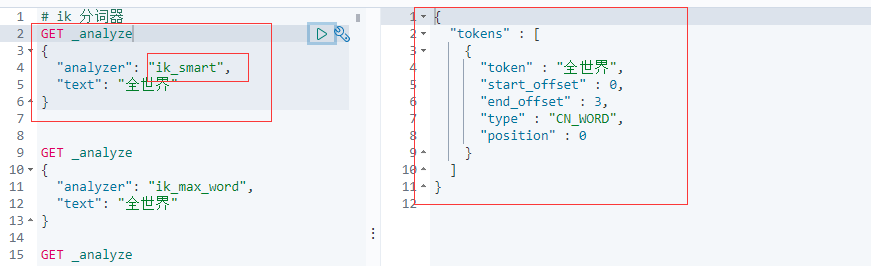
ik_smart:最少切分
GET _analyze
{
"analyzer": "ik_smart",
"text": "全世界"
}
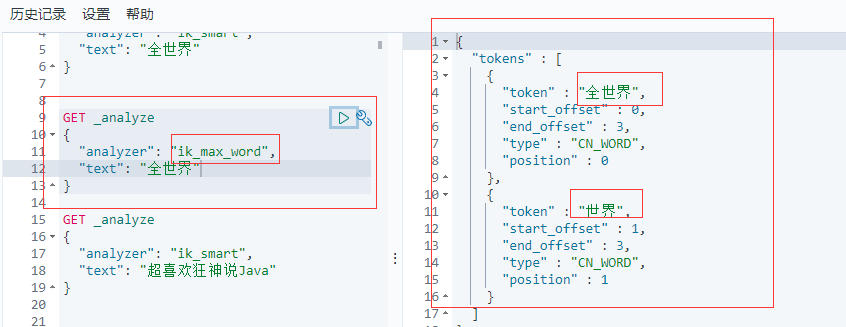
ik_max_word:最細粒度劃分(窮盡詞庫的可能)
GET _analyze
{
"analyzer": "ik_max_word",
"text": "全世界"
}
4.5.2 添加自定義的詞添加到擴展字典中
從上面看,感覺分詞都比較正常,但是大多數,分詞都滿足不了我們的想法,如下例;
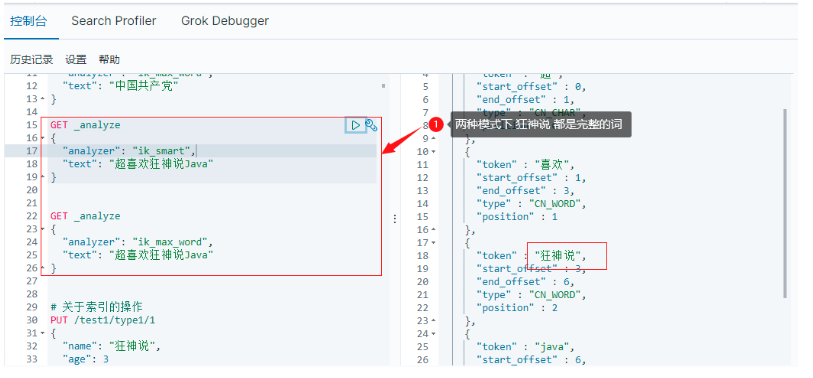
GET _analyze
{
"analyzer": "ik_max_word",
"text": "超喜歡狂神說Java"
}
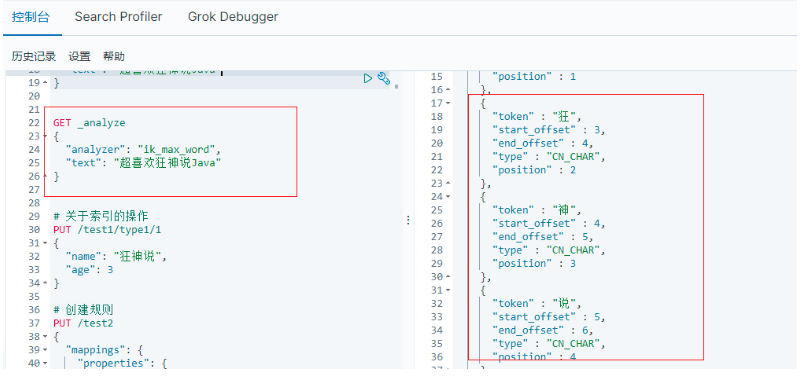
發現問題:狂神說被拆開了;
這種自己需要的詞,需要自己加到我們的分詞器的字典中!
1.創建字典檔案
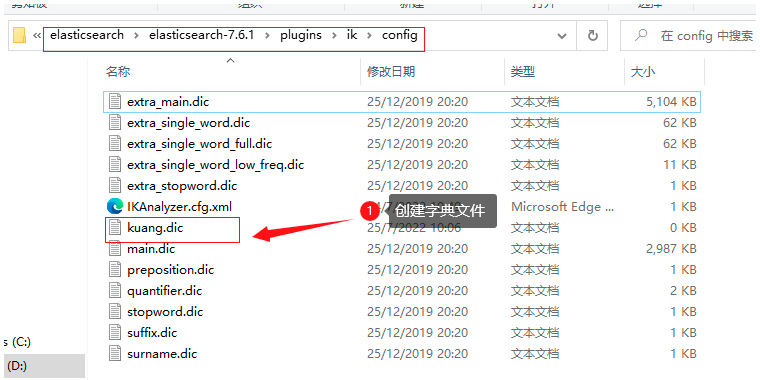
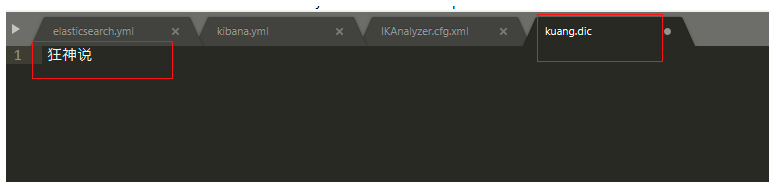
2.添加字典內容:kuang.dic
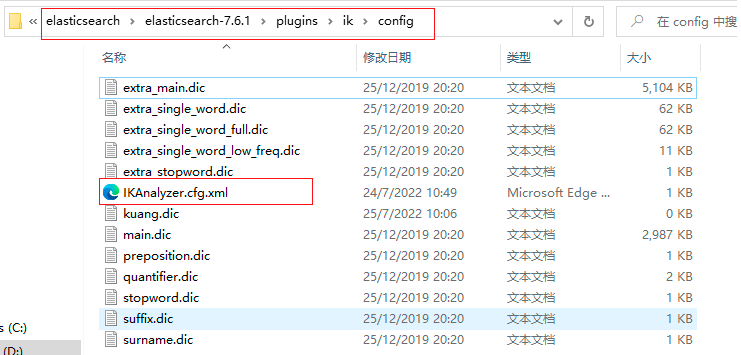
3.將自己的字典檔案配置到ik分詞器的組態檔中:
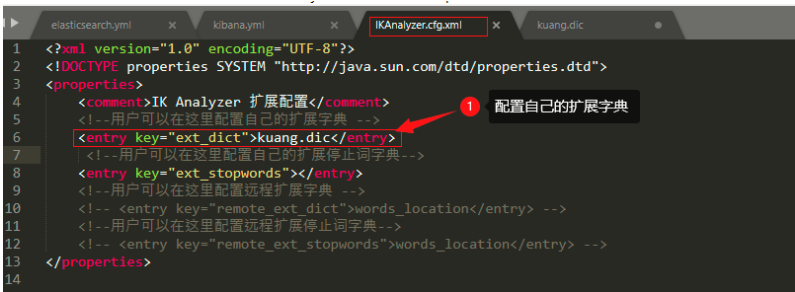
配置自己的擴展字典:
4.重啟,再次測驗
再次測驗一下狂神說,看下效果
以后的話,我們需要將自己配置 分詞就在自己定義的dic檔案中進行配置即可;
5、關于索引的基本操作
5.1Rest風格說明
一種軟體架構風格,而不是標準,只是提供了一組設計原則和約束條件,它主要用于客戶端和服務器互動類的軟體,基于這個風格設計的軟體可以更簡潔,更有層次,更易于實作快取等機制,
基本Rest命令說明:
| method | url地址 | 描述 |
|---|---|---|
| PUT(創建,修改) | localhost:9200/索引名稱/型別名稱/檔案id | 創建檔案(指定檔案id) |
| POST(創建) | localhost:9200/索引名稱/型別名稱 | 創建檔案(隨機檔案id) |
| POST(修改) | localhost:9200/索引名稱/型別名稱/檔案id/_update | 修改檔案 |
| DELETE(洗掉) | localhost:9200/索引名稱/型別名稱/檔案id | 洗掉檔案 |
| GET(查詢) | localhost:9200/索引名稱/型別名稱/檔案id | 查詢檔案通過檔案ID |
| POST(查詢) | localhost:9200/索引名稱/型別名稱/檔案id/_search | 查詢所有資料 |
5.2 增刪改查
5.2.1 創建索引
PUT /索引名/~型別名~/檔案id #型別名后面棄用了
{
請求體
}
PUT /test1/type1/1
{
"name": "狂神說",
"age": 3
}
執行命令
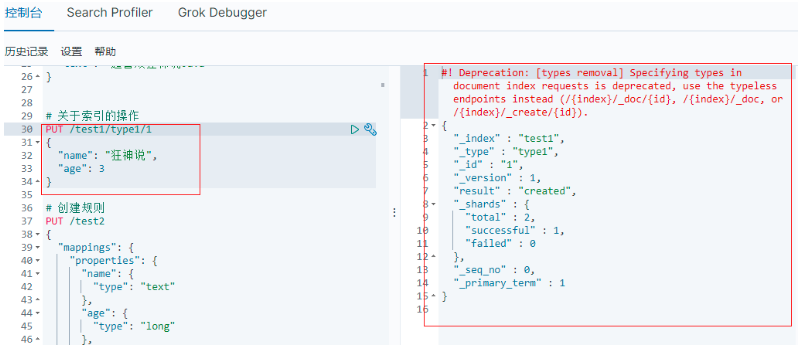
完成了自動增加索引,資料也添加了, 添加了檔案 (“行”)![image-20220725111741302]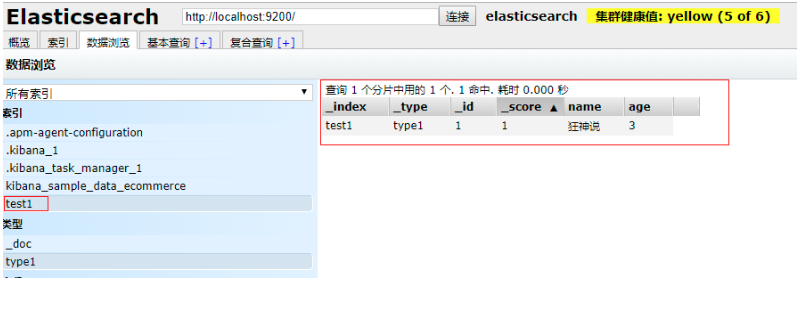
5.2.2 欄位資料型別
- 字串型別
- text、keyword
- text:支持分詞,全文檢索,支持模糊、精確查詢,不支持聚合,排序操作;text型別的最大支持的字符長度無限制,適合大欄位存盤;
- keyword:不進行分詞,直接索引、支持模糊、支持精確匹配,支持聚合、排序操作,keyword型別的最大支持的長度為——32766個UTF-8型別的字符,可以通過設定ignore_above指定自持字符長度,超過給定長度后的資料將不被索引,無法通過term精確匹配檢索回傳結果,
- text、keyword
- 數值型
- long、Integer、short、byte、double、float、half float、scaled float
- 日期型別
- date
- te布爾型別
- boolean
- 二進制型別
- binary
- 等等…
5.2.3 指定欄位的型別
創建規則
# 創建規則
PUT /test2
{
"mappings": {
"properties": {
"name": {
"type": "text"
},
"age": {
"type": "long"
},
"birthday": {
"type": "date"
}
}
}
}
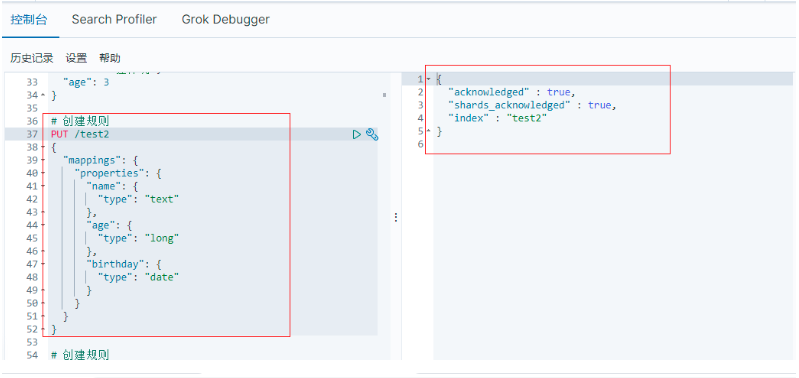
GET test2 查看規則資訊
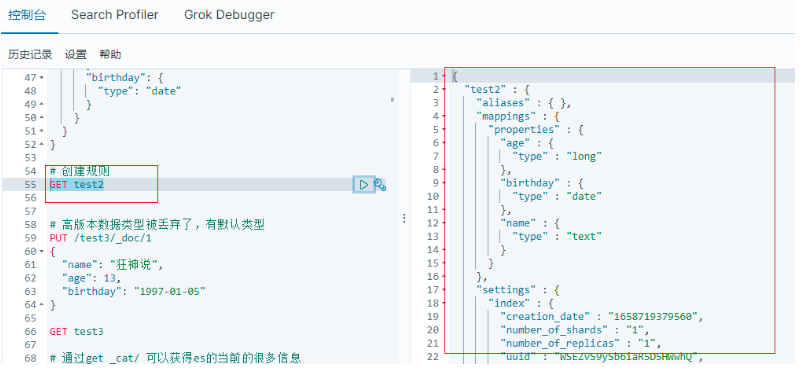
5.3.4 查看默認資訊
直接插入資料,不創建規則,自動匹配資料型別;
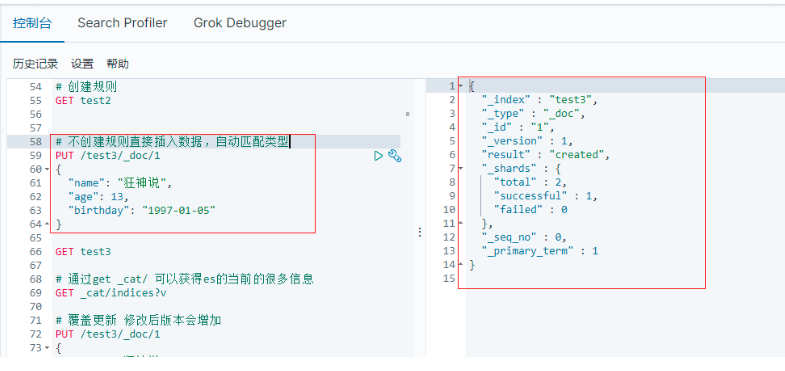
查看test索引的默認匹配資料型別:
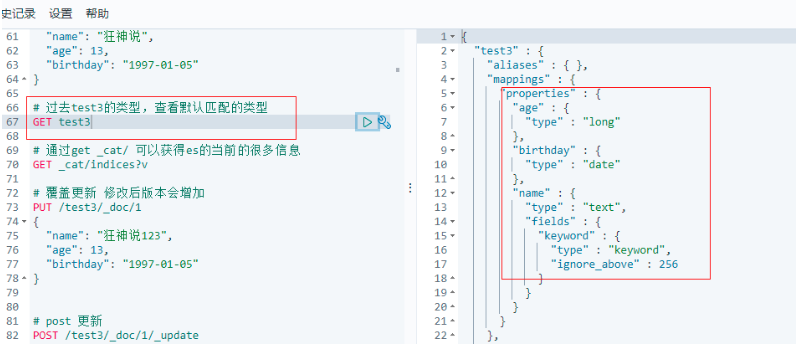
如果自己的檔案欄位沒有指定,那么es就會給我們默認匹配欄位型別;
5.3.5 擴展:get _cat/
通過get _cat/可以獲取ElasticSearch的當前的很多資訊!
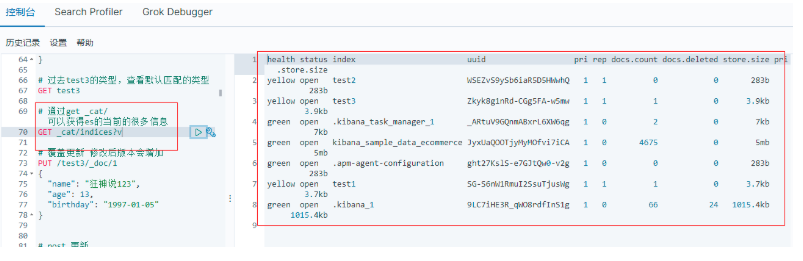
GET _cat/indices
GET _cat/aliases
GET _cat/allocation
GET _cat/count
GET _cat/fielddata
GET _cat/health
GET _cat/indices
GET _cat/master
GET _cat/nodeattrs
GET _cat/nodes
GET _cat/pending_tasks
GET _cat/plugins
GET _cat/recovery
GET _cat/repositories
GET _cat/segments
GET _cat/shards
GET _cat/snapshots
GET _cat/tasks
GET _cat/templates
GET _cat/thread_pool
5.3.6 修改
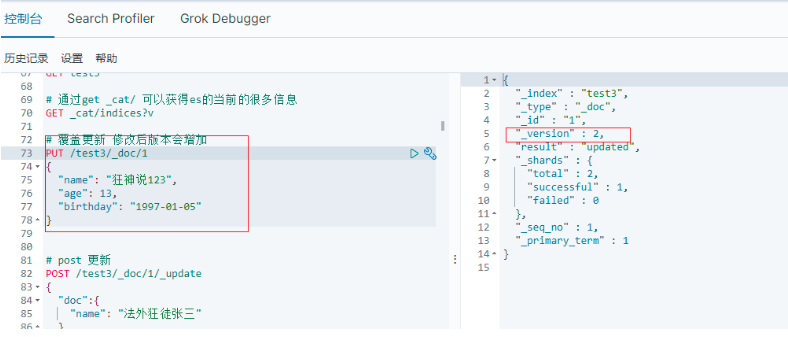
5.3.6.1 使用put覆寫原來的值 (舊方法)
注意:覆寫修改,會資料丟失,如果原來的資料有多個欄位,但是新資料只有一個欄位,則其他沒有新資料的欄位會沒有資料;(原理先洗掉后增加)
# 覆寫更新 修改后版本會增加
PUT /test3/_doc/1
{
"name": "狂神說123",
"age": 13,
"birthday": "1997-01-05"
}
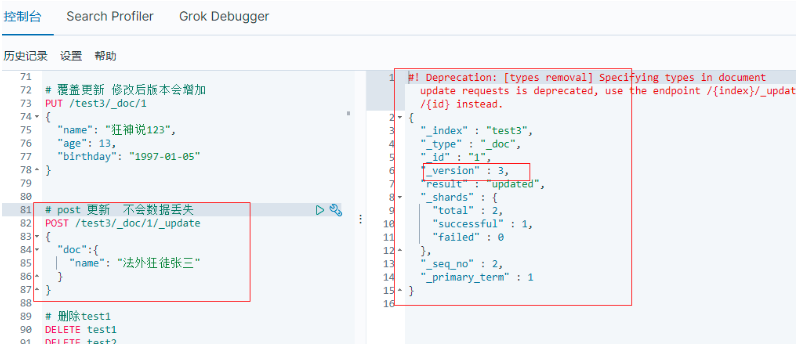
5.3.6.2 使用post的update跟新
- 需要注意doc
- 不會丟失欄位
# post 更新 不會資料丟失
POST /test3/_doc/1/_update
{
"doc":{
"name": "法外狂徒張三"
}
}
5.3.7 洗掉索引
# 洗掉test1
DELETE test1
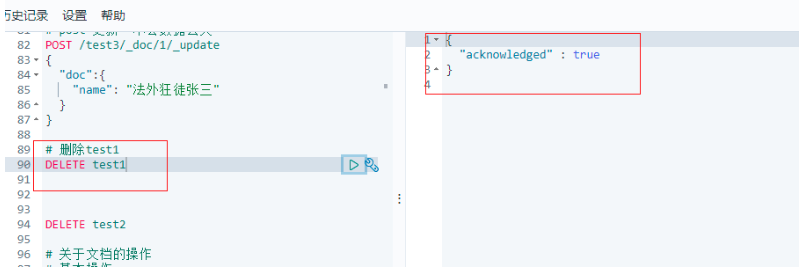
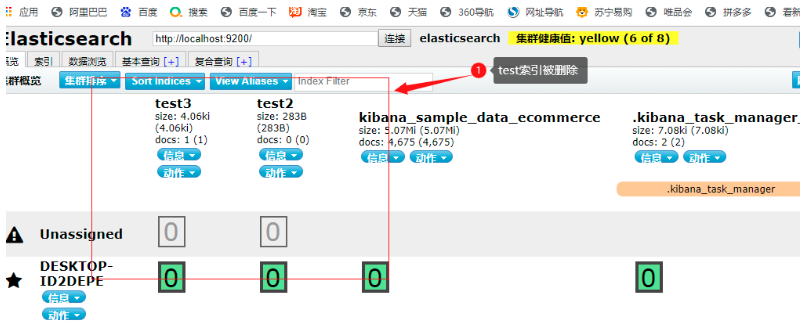
通過DELETE命令實作洗掉,根據你的請求判斷是洗掉索引還是洗掉檔案記錄;
使用RESTFUL風格是我們ES推薦大家使用的;
6、關于檔案的基本操作
添加資料
# 關于檔案的操作
# 基本操作
# 添加資料
PUT /kuangshen/user/1
{
"name": "狂神說",
"age": 23,
"desc": "一頓操作猛如虎再看工資2500",
"tags": ["技術宅","溫暖","指男"]
}
PUT /kuangshen/user/2
{
"name": "張三",
"age": 3,
"desc": "法外狂徒",
"tags": ["交友","旅游","渣男"]
}
PUT /kuangshen/user/3
{
"name": "李四",
"age": 30,
"desc": "mpm,不知道怎么形容",
"tags": ["靚女","旅游","唱歌"]
}
PUT /kuangshen/user/4
{
"name": "狂神說前端",
"age": 3,
"desc": "一頓操作猛如虎再看工資2500",
"tags": ["技術宅","溫暖","指男"]
}
6.1 條件查詢(簡單查詢)
簡單的條件查詢,可以根據默認的映射規則,產生的查詢!
# 簡單的搜索
GET kuangshen/user/1
# 簡單的條件查詢
GET kuangshen/user/_search?q=name:狂神說
GET kuangshen/user/_search?q=name:狂神說Java
6.2 復雜查詢
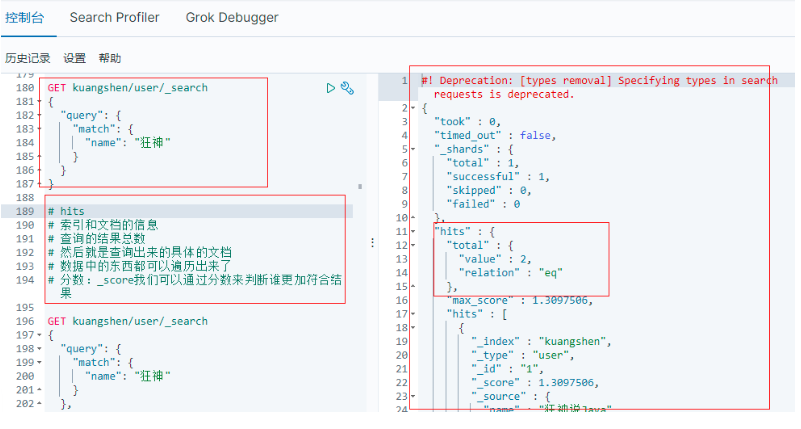
GET kuangshen/user/_search
{
"query": {
"match": {
"name": "狂神"
}
}
}
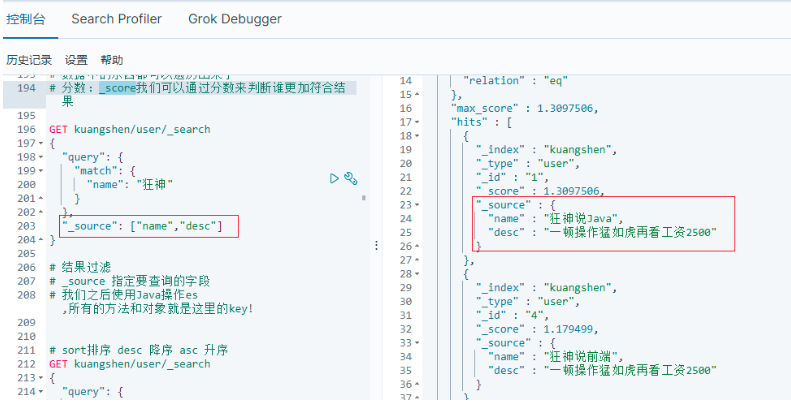
6.2.1 _score 欄位過濾
GET kuangshen/user/_search
{
"query": {
"match": {
"name": "狂神"
}
},
"_source": ["name","desc"]
}
6.2.2 sort排序
desc 降序 asc 升序
# sort排序 desc 降序 asc 升序
GET kuangshen/user/_search
{
"query": {
"match": {
"name": "狂神"
}
},
"sort": [
{
"age": {
"order": "desc"
}
}
]
}
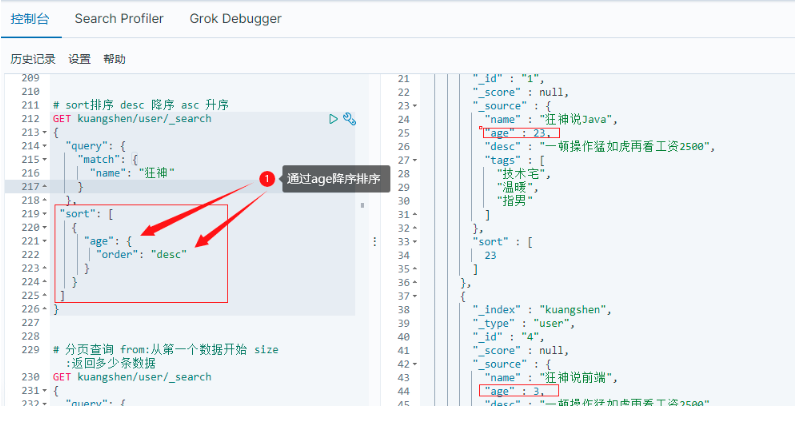
6.2.3 form size 分頁查詢
# 分頁查詢 from:從第一個資料開始 size:回傳多少條資料
GET kuangshen/user/_search
{
"query": {
"match": {
"name": "狂神"
}
},
"sort": [
{
"age": {
"order": "desc"
}
}
],
"from": 0,
"size": 2
}
# 資料下標從0開始
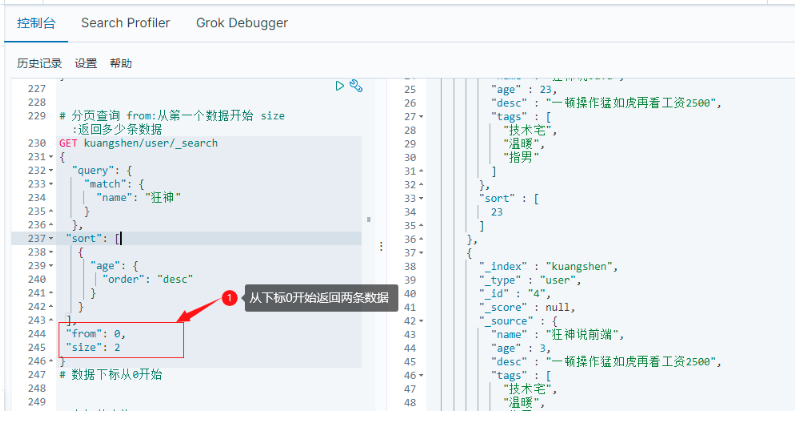
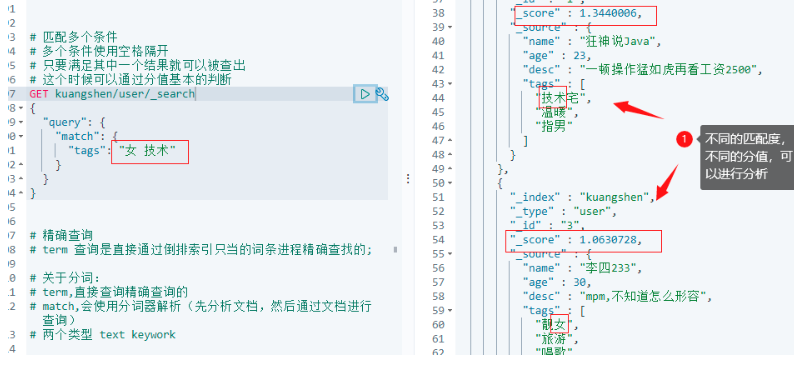
6.2.4 布林值查詢
6.2.4.1 match 匹配查詢
# 多個條件使用空格隔開 (類似 in)
# 只要滿足其中一個結果舊可以被查出來
# 這個時候可以通過分值基本的判斷
GET kuangshen/user/_search
{
"query": {
"match": {
"tags": "男 技術"
}
}
}
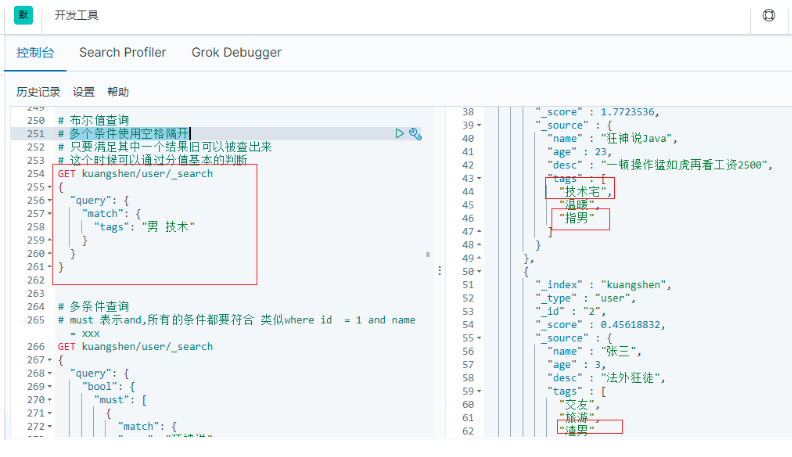
6.2.4.2 must 等價 and
# 多條件查詢
# must 表示and,所有的條件都要符合 類似where id = 1 and name = xxx
GET kuangshen/user/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"name": "狂神說"
}
},
{
"match": {
"age": "23"
}
}
]
}
}
}
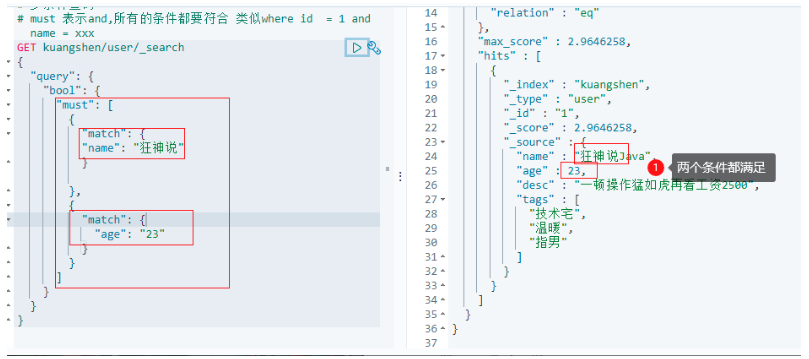
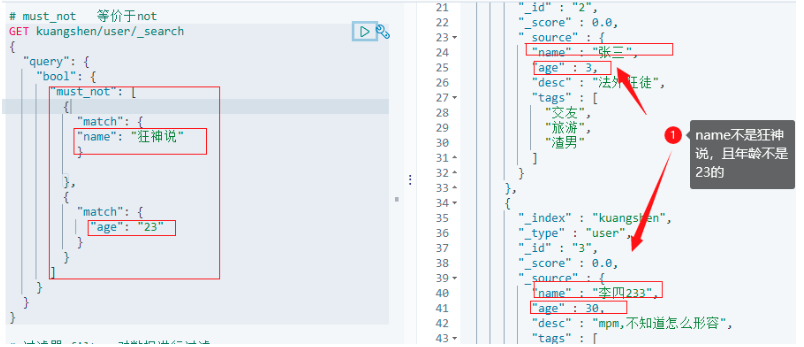
6.2.4.3 should 等價or
# should 表示or
GET kuangshen/user/_search
{
"query": {
"bool": {
"should": [
{
"match": {
"name": "狂神說"
}
},
{
"match": {
"age": "23"
}
}
]
}
}
}
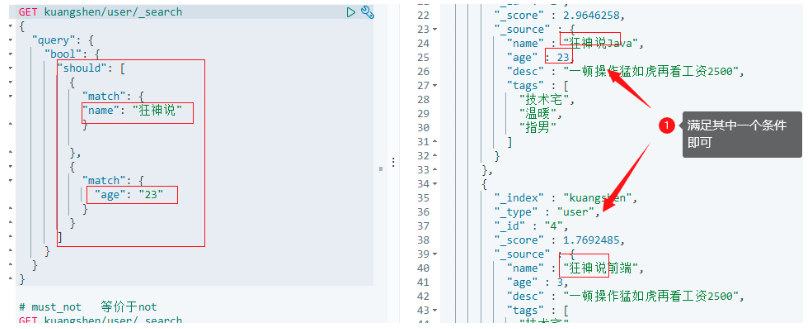
6.2.4.4 must_not 等價 not
# must_not 等價于not
GET kuangshen/user/_search
{
"query": {
"bool": {
"must_not": [
{
"match": {
"name": "狂神說"
}
},
{
"match": {
"age": "23"
}
}
]
}
}
}
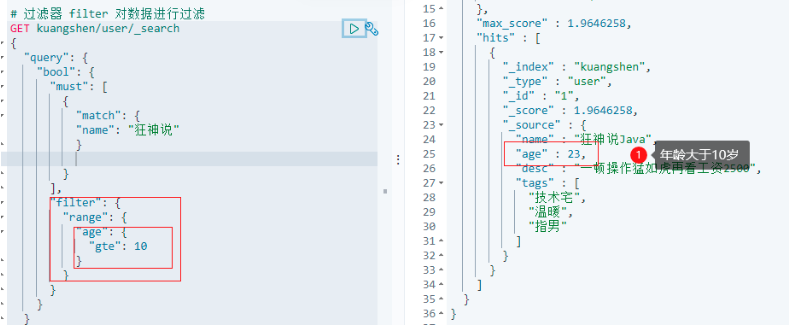
6.2.4.5 filter 對資料進行過濾
# 過濾器 filter 對資料進行過濾
GET kuangshen/user/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"name": "狂神說"
}
}
],
"filter": {
"range": {
"age": {
"gte": 10
}
}
}
}
}
}
# gt 大于
# gte 大于等于
# lt 小于
# lte 小于等于
6.2.4.6 匹配多個條件
# 匹配多個條件
# 多個條件使用空格隔開
# 只要滿足其中一個結果就可以被查出
# 這個時候可以通過分值基本的判斷
GET kuangshen/user/_search
{
"query": {
"match": {
"tags": "女 技術"
}
}
}
6.2.4.7 term 精確查詢
term查詢是直接通過倒排索引指定的詞條進行精確的查找;
關于分詞:
- trem:直接查詢精確的
- match:會使用分詞器決議!(先分析檔案,然后通過分析的檔案進行查詢;)
- 兩個型別 text keywork
# 測驗
# 創建索引
PUT testdb
{
"mappings": {
"properties": {
"name": {
"type": "text"
},
"desc": {
"type": "keyword"
}
}
}
}
# 插入資料
PUT testdb/_doc/1
{
"name": "狂神說 Java name",
"desc": "狂神說 Java desc"
}
PUT testdb/_doc/2
{
"name": "狂神說 Java name2",
"desc": "狂神說 Java desc2"
}
6.2.4.6.1 "analyzer": "keyword" 模式
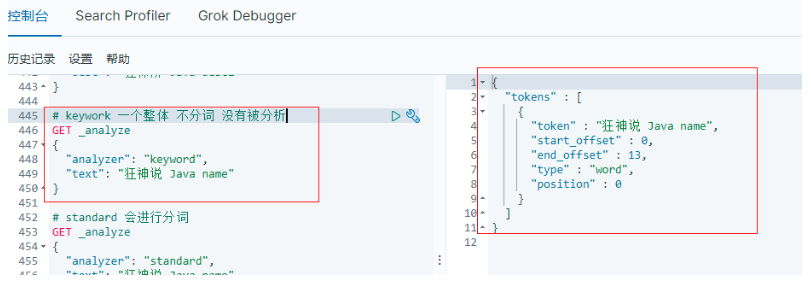
# keywork 模式 一個整體 不分詞 沒有被分析
GET _analyze
{
"analyzer": "keyword",
"text": "狂神說 Java name"
}
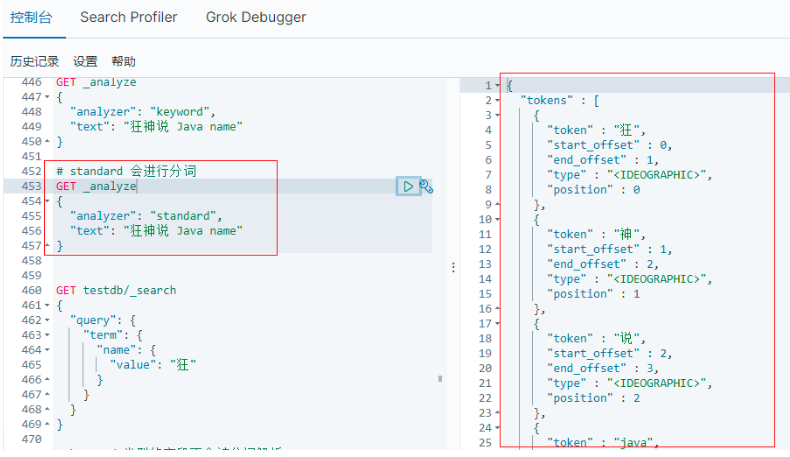
6.2.4.6.2 "analyzer": "standard"模式
# standard 模式 會進行分詞
GET _analyze
{
"analyzer": "standard",
"text": "狂神說 Java name"
}
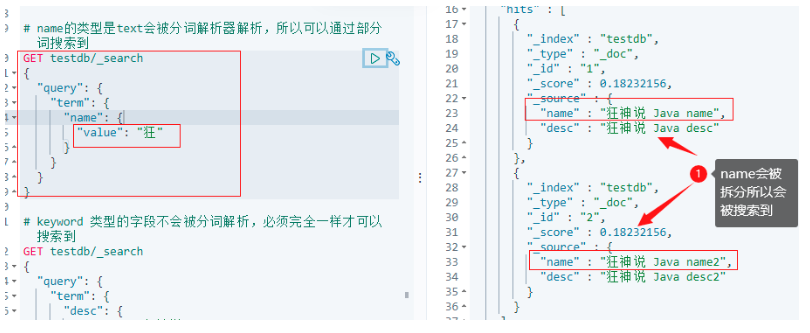
6.2.4.6.3 text 和 keywork 型別區別
# name的型別是text會被分詞決議器決議,所以可以通過部分詞搜索到
GET testdb/_search
{
"query": {
"term": {
"name": {
"value": "狂"
}
}
}
}
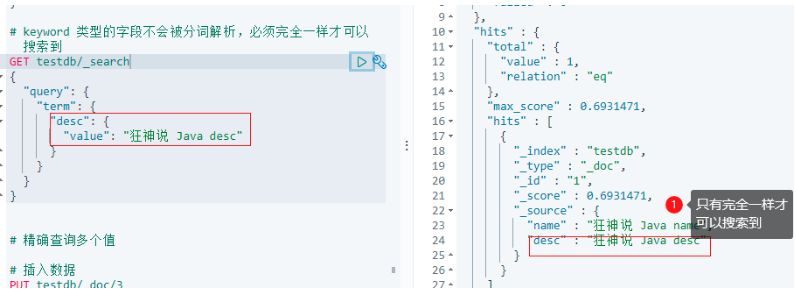
# keyword 型別的欄位不會被分詞決議,必須完全一樣才可以搜索到
GET testdb/_search
{
"query": {
"term": {
"desc": {
"value": "狂神說 Java desc"
}
}
}
}
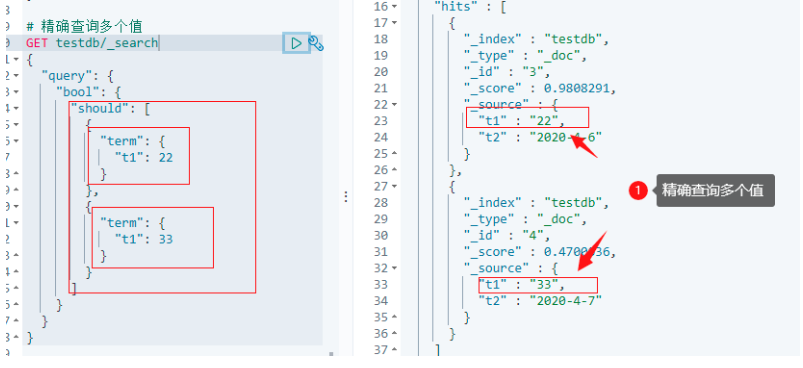
6.2.4.6.4 多個值匹配精確查詢
# 精確查詢多個值
# 插入資料
PUT testdb/_doc/3
{
"t1": "22",
"t2": "2020-4-6"
}
PUT testdb/_doc/4
{
"t1": "33",
"t2": "2020-4-7"
}
GET testdb/_search
{
"query": {
"bool": {
"should": [
{
"term": {
"t1": 22
}
},
{
"term": {
"t1": 3
}
}
]
}
}
}
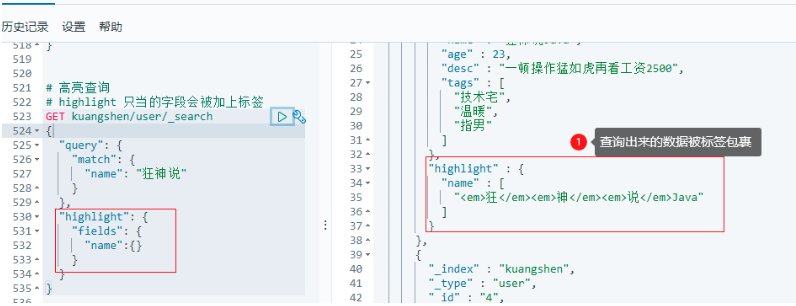
6.2.5 高亮查詢 highlight
6.2.5.1 高亮查詢
# 高亮查詢
# highlight 只當的欄位會被加上標簽
GET kuangshen/user/_search
{
"query": {
"match": {
"name": "狂神說"
}
},
"highlight": {
"fields": {
"name":{}
}
}
}
6.2.5.2 自定義高亮標簽
# 自定義搜索高亮條件 ,自定義標簽
GET kuangshen/user/_search
{
"query": {
"match": {
"name": "狂神說"
}
},
"highlight": {
"pre_tags": "<p class='key' style='color:red'>",
"post_tags": "</p>",
"fields": {
"name":{}
}
}
}

7、SpringBoot整合
7.1 官方API
Java REST Client->https://www.elastic.co/guide/en/elasticsearch/client/java-rest/7.6/index.html
7.2 基本配置
7.2.1 找到原生的依賴
API中原生依賴的位置
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>7.6.2</version>
</dependency>
7.2.2 找物件
AIP中物件位置
RestHighLevelClient client = new RestHighLevelClient(
RestClient.builder(
new HttpHost("localhost", 9200, "http"),
new HttpHost("localhost", 9201, "http")));
client.close();
7.2.3 分析這個類中的方法
配置基本的專案
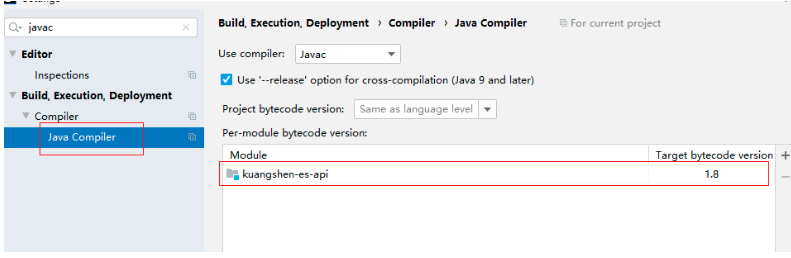
注意幾個配置
JDK版本:
Javac編譯版本
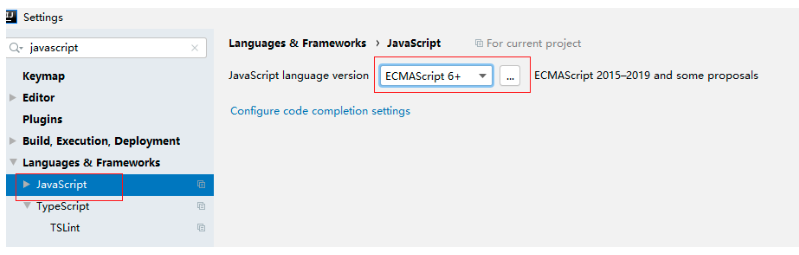
JavaScript版本
7.3 搭建環境
7.3.1 依賴
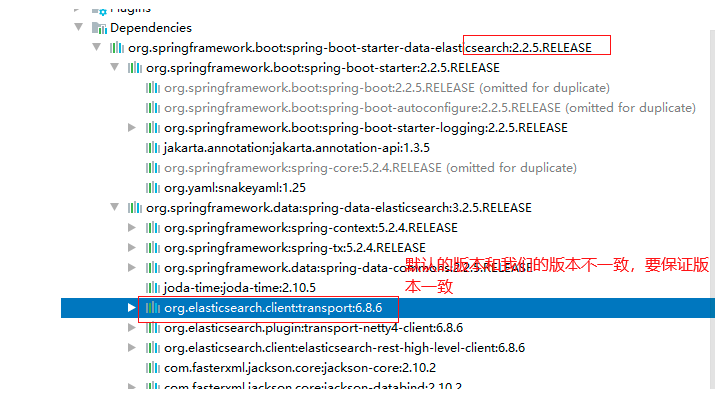
7.3.1.1 確保elasticsearch的版本和我們本地版本一致
1 查看版本是否一致:
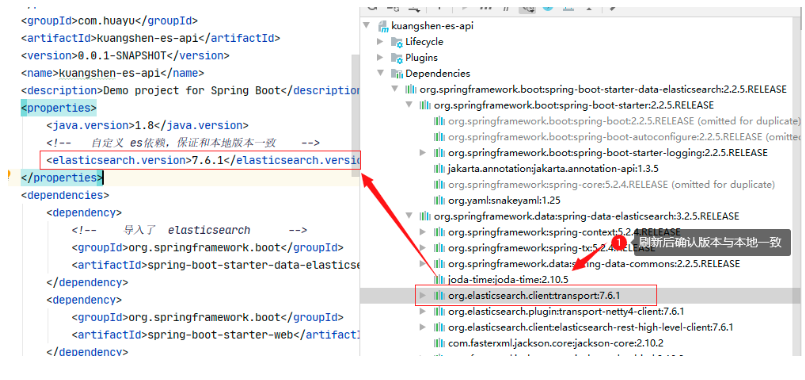
2 自定義我們需要的版本7.6.1:
<properties>
<java.version>1.8</java.version>
<!-- 自定義 es依賴,保證和本地版本一致 -->
<elasticsearch.version>7.6.1</elasticsearch.version>
</properties>
7.3.2注入物件
自定義配置類
@Configuration
public class ElasticSearchClientConfig {
@Bean
public RestHighLevelClient restHighLevelClient(){
RestHighLevelClient client = new RestHighLevelClient(
RestClient.builder(
new HttpHost("localhost", 9200, "http")));
return client;
}
}
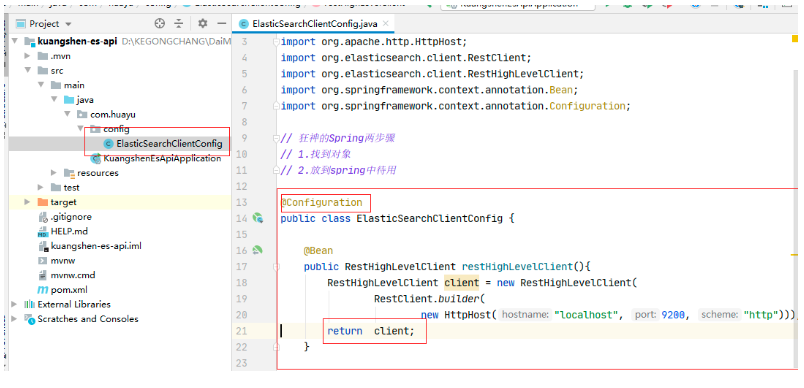
原始碼中提供的物件(可以直接拿來用)
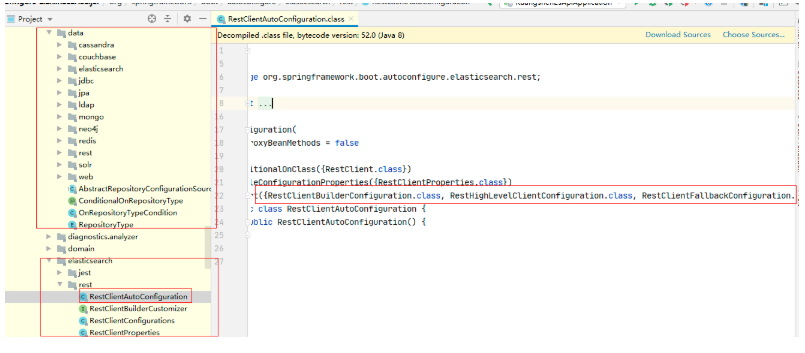
雖然這里匯入了3個類,靜態內部類,但是核心類就只有一個:
class RestClientConfigurations {
RestClientConfigurations() {
}
@Configuration(
proxyBeanMethods = false
)
static class RestClientFallbackConfiguration {
RestClientFallbackConfiguration() {
}
@Bean
@ConditionalOnMissingBean
RestClient elasticsearchRestClient(RestClientBuilder builder) {
return builder.build();
}
}
@Configuration(
proxyBeanMethods = false
)
@ConditionalOnClass({RestHighLevelClient.class})
static class RestHighLevelClientConfiguration {
RestHighLevelClientConfiguration() {
}
//RestHighLevelClient 高級客戶端,也是我們這里要講,后面專案會用到的客戶端
@Bean
@ConditionalOnMissingBean
RestHighLevelClient elasticsearchRestHighLevelClient(RestClientBuilder restClientBuilder) {
return new RestHighLevelClient(restClientBuilder);
}
//RestClient 普通客戶端
@Bean
@ConditionalOnMissingBean
RestClient elasticsearchRestClient(RestClientBuilder builder, ObjectProvider<RestHighLevelClient> restHighLevelClient) {
RestHighLevelClient client = (RestHighLevelClient)restHighLevelClient.getIfUnique();
return client != null ? client.getLowLevelClient() : builder.build();
}
}
@Configuration(
proxyBeanMethods = false
)
static class RestClientBuilderConfiguration {
RestClientBuilderConfiguration() {
}
//RestClientBuilder
@Bean
@ConditionalOnMissingBean
RestClientBuilder elasticsearchRestClientBuilder(RestClientProperties properties, ObjectProvider<RestClientBuilderCustomizer> builderCustomizers) {
HttpHost[] hosts = (HttpHost[])properties.getUris().stream().map(HttpHost::create).toArray((x$0) -> {
return new HttpHost[x$0];
});
RestClientBuilder builder = RestClient.builder(hosts);
PropertyMapper map = PropertyMapper.get();
map.from(properties::getUsername).whenHasText().to((username) -> {
CredentialsProvider credentialsProvider = new BasicCredentialsProvider();
Credentials credentials = new UsernamePasswordCredentials(properties.getUsername(), properties.getPassword());
credentialsProvider.setCredentials(AuthScope.ANY, credentials);
builder.setHttpClientConfigCallback((httpClientBuilder) -> {
return httpClientBuilder.setDefaultCredentialsProvider(credentialsProvider);
});
});
builder.setRequestConfigCallback((requestConfigBuilder) -> {
properties.getClass();
map.from(properties::getConnectionTimeout).whenNonNull().asInt(Duration::toMillis).to(requestConfigBuilder::setConnectTimeout);
properties.getClass();
map.from(properties::getReadTimeout).whenNonNull().asInt(Duration::toMillis).to(requestConfigBuilder::setSocketTimeout);
return requestConfigBuilder;
});
builderCustomizers.orderedStream().forEach((customizer) -> {
customizer.customize(builder);
});
return builder;
}
}
}
7.4 測驗API
7.4.1 創建索引
//測驗索引的創建 Request PUT kuang_index
@Test
void testCreateIndex() throws IOException {
// 1.創建索引物件
CreateIndexRequest request = new CreateIndexRequest("kuang_index");
// 2.客戶端執行請求 IndicesClient
CreateIndexResponse createIndexResponse = client.indices().create(request, RequestOptions.DEFAULT);
System.out.println(createIndexResponse);
}
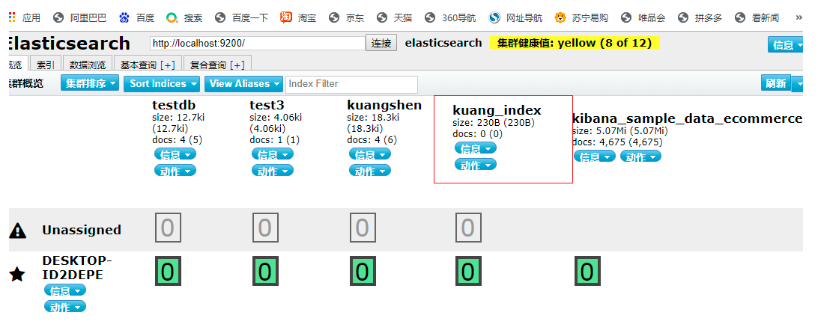
7.4.2 判斷索引是否存在
//測驗獲取索引,只能判斷其是否存在
@Test
void testExistIndex() throws IOException {
GetIndexRequest request = new GetIndexRequest("kuang_index");
boolean exists = client.indices().exists(request, RequestOptions.DEFAULT);
System.out.println("kuang_index是否存在:"+exists);
}
7.4.3 洗掉索引
//測驗洗掉索引
@Test
void testDeleteIndex() throws IOException {
DeleteIndexRequest request = new DeleteIndexRequest("kuang_index");
//洗掉
AcknowledgedResponse delete = client.indices().delete(request, RequestOptions.DEFAULT);
System.out.println("洗掉 kuang_index 是否成功:"+delete.isAcknowledged());
}
7.4.4 添加檔案
7.4.4.1 匯入依賴
<!-- fastjson -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.62</version>
</dependency>
7.4.4.2 創建物體類
@Data
@AllArgsConstructor
@NoArgsConstructor
@Component
public class User {
private String name;
private int age;
}
7.4.4.3 添加檔案
//測驗添加檔案
@Test
void testAddDocument() throws IOException {
//創建物件
User user = new User("狂神", 3);
//創建請求
IndexRequest request = new IndexRequest("kuang_index");
//規則 put /kuang_index/_doc/1
request.id("1");
request.timeout(TimeValue.timeValueSeconds(1));
request.timeout("1s");
//將我們的資料放入請求 json
IndexRequest source = request.source(JSON.toJSON(user), XContentType.JSON);
//客戶端發請求,獲取相應的結果
IndexResponse indexResponse = client.index(request, RequestOptions.DEFAULT);
System.out.println(indexResponse.toString());
//IndexResponse[index=kuang_index,type=_doc,id=1,version=1,result=created,seqNo=0,primaryTerm=1,shards={"total":2,"successful":1,"failed":0}]
System.out.println(indexResponse.status()); //對應回傳的狀態 CREATED
}
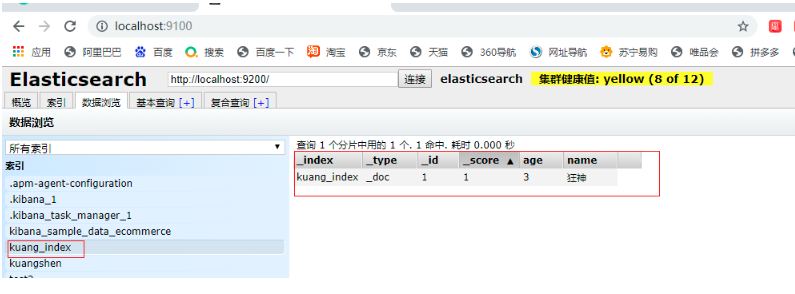
7.4.5 判斷檔案是否存在
//判斷檔案是否存在
@Test
void testIsExists() throws IOException {
GetRequest getRequest = new GetRequest("kuang_index", "1");
//不獲取回傳值,_source 的背景關系
getRequest.fetchSourceContext(new FetchSourceContext(false));
getRequest.storedFields("_none_");
boolean exists = client.exists(getRequest, RequestOptions.DEFAULT);
System.out.println("判斷1號檔案是否存在:" + exists);
//判斷1號檔案是否存在:true
}
7.4.6 獲得檔案的資訊
//獲取檔案資訊
@Test
void testGetDocument() throws IOException {
GetRequest getRequest = new GetRequest("kuang_index", "1");
GetResponse getResponse = client.get(getRequest, RequestOptions.DEFAULT);
System.out.println(getResponse.getSourceAsString()); //列印檔案內容
//
}
7.4.7 更新檔案資訊
//更新檔案的資訊
@Test
void testUpdateDocument() throws IOException{
UpdateRequest updateRequest = new UpdateRequest("kuang_index", "1");
updateRequest.timeout("1s");
User user = new User("狂神說Java", 18);
updateRequest.doc(JSON.toJSONString(user),XContentType.JSON); //XContentType.JSON 傳入的資料型別
UpdateResponse updateResponse = client.update(updateRequest, RequestOptions.DEFAULT);
System.out.println("檔案是否跟新成功:"+updateResponse.status());
}
7.4.8 洗掉檔案
//洗掉檔案記錄
@Test
void testDeleteDocument() throws IOException{
DeleteRequest deleteRequest = new DeleteRequest("kuang_index", "1");
deleteRequest.timeout("1s");
DeleteResponse deleteResponse = client.delete(deleteRequest, RequestOptions.DEFAULT);
System.out.println("檔案是否洗掉成功:" + deleteResponse.status());
}
7.4.9 批量處理請求
//特殊的,真的專案一般都會批量插入資料
@Test
void testBulkRequest() throws IOException{
BulkRequest bulkRequest = new BulkRequest();
bulkRequest.timeout("1s");
ArrayList<User> userList = new ArrayList<>();
userList.add(new User("kuangshen1",3));
userList.add(new User("kuangshen2",3));
userList.add(new User("kuangshen3",3));
userList.add(new User("kuangshen4",3));
userList.add(new User("kuangshen5",3));
userList.add(new User("kuangshen6",3));
//批處理請求
for (int i = 0; i < userList.size(); i++) {
//批量更新和批量洗掉,就在這里修改對應的請求就可以了
bulkRequest.add(
new IndexRequest("kuang_index")
.id(""+(i+1)) //不設定id就會默認生成隨機id
.source(JSON.toJSONString(userList.get(i)),XContentType.JSON)
);
}
BulkResponse bulkResponse = client.bulk(bulkRequest, RequestOptions.DEFAULT);
System.out.println("添加處理請求是否失敗:"+bulkResponse.hasFailures()); //false表示成功,true表示失敗
}
7.4.10 查詢
// 查詢
//SearchRequest 搜索請i去
//searchSourceBuilder 條件構造器
//HighlightBuilder 構建高亮
//TermQueryBuilder 精確查詢
//MatchAllQueryBuilder
// xxxQueryBuilder 對應我們之前的所有命令
@Test
void testSearch() throws IOException {
SearchRequest searchRequest = new SearchRequest("kuang_index");
//構建搜索條件
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
//查詢條件,我們可以使用QueryBuilders工具來實作
//QueryBuilders.termQuery 精確查詢
//QuertBuilders.matchAllQuery() 匹配所有
TermQueryBuilder termQueryBuilder = QueryBuilders.termQuery("name", "kuangshen1");
sourceBuilder.query(termQueryBuilder);
sourceBuilder.timeout(new TimeValue(60, TimeUnit.SECONDS));
searchRequest.source(sourceBuilder);
SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);
System.out.println("查詢結果:"+JSON.toJSONString(searchResponse.getHits()));
//查詢結果:{"fragment":true,"hits":[{"fields":{},"fragment":false,"highlightFields":{},"id":"1","matchedQueries":[],"primaryTerm":0,"rawSortValues":[],"score":1.540445,"seqNo":-2,"sortValues":[],"sourceAsMap":{"name":"kuangshen1","age":3},"sourceAsString":"{\"age\":3,\"name\":\"kuangshen1\"}","sourceRef":{"fragment":true},"type":"_doc","version":-1}],"maxScore":1.540445,"totalHits":{"relation":"EQUAL_TO","value":1}}
System.out.println("===================");
for (SearchHit documentFields : searchResponse.getHits().getHits()) {
System.out.println(documentFields.getSourceAsMap());
}
//{name=kuangshen1, age=3}
}
8、京東搜索
8.1 專案搭建
素材連接:https://pan.baidu.com/s/1M5uWdYsCZyzIAOcgcRkA_A#list/path=%2F
提取碼:qk8p
感謝這位老鐵->殺神TH
匯入素材啟動專案,訪問頁面
indexController.java
@Controller
public class IndexController {
@GetMapping({"/","/index"})
public String index(){
return "index";
}
}
8.2 爬取資料
資料問題?資料庫獲取,訊息佇列,訊息佇列中獲取,都可以成為資料源,爬蟲!
爬蟲資料:(獲取請求回傳的頁面資訊,篩選出我們想要的資料就可以了!)
pojo:
@Data
@AllArgsConstructor
@NoArgsConstructor
@Component
public class Content {
private String title;
private String img;
private String price;
}
工具類:
@Component
public class HtmlParseUtil {
public static void main(String[] args) throws Exception {
new HtmlParseUtil().parseJD("java").forEach(System.out::println);
}
public ArrayList<Content> parseJD(String keyword) throws Exception{
//獲取請求https://search.jd.com/Search?keyword=java
//前提,需要聯網,ajax 不能獲取到
String url = "https://search.jd.com/Search?keyword="+keyword;
//決議網頁(Jsoup回傳Document就是瀏覽器Document物件)
Document document = Jsoup.parse(new URL(url), 30000);
//所有在js中可以使用的方法,這里都能使用
Element element = document.getElementById("J_goodsList");
// System.out.println(element.html());
//獲取所有的li元素
Elements elements = element.getElementsByTag("li");
ArrayList<Content> goodsList = new ArrayList<>();
//獲取元素中的內容,這里el,就是每個li標簽
for(Element el : elements){
//關于這種圖片特別多的網站,多有的圖片都是延遲加載的!
//source-data-lazy-img
// String img = el.getElementsByTag("img").eq(0).attr("src");
String img = el.getElementsByTag("img").eq(0).attr("data-lazy-img");
String price = el.getElementsByClass("p-price").eq(0).text();
String title = el.getElementsByClass("p-name").eq(0).text();
// System.out.println("=====================================");
// System.out.println(img);
// System.out.println(price);
// System.out.println(title);
Content content = new Content();
content.setTitle(title);
content.setImg(img);
content.setPrice(price);
goodsList.add(content);
}
return goodsList;
}
}
8.3 業務撰寫
8.3.1 業務撰寫
ContentService
//業務撰寫
@Service
public class ContentService {
@Autowired
private RestHighLevelClient restHighLevelClient;
//1.決議資料放入es索引
public Boolean parseContent(String keywords) throws Exception {
ArrayList<Content> contents = new HtmlParseUtil().parseJD(keywords);
//把查詢到的資料放入es中
BulkRequest bulkRequest = new BulkRequest();
bulkRequest.timeout("2m");
for (int i = 0; i < contents.size(); i++) {
System.out.println(JSON.toJSONString(contents.get(i)));
bulkRequest.add(
new IndexRequest("jd_goods")
// .id(""+(i+1))
.source(JSON.toJSONString(contents.get(i)), XContentType.JSON));
}
BulkResponse bulkResponse = restHighLevelClient.bulk(bulkRequest, RequestOptions.DEFAULT);
return !bulkResponse.hasFailures();
}
//2.獲取這些資料實作搜索功能
public List<Map<String,Object>> highlightSearch(String keyword,int pageNo,int pageSize) throws IOException {
if(pageNo <= 1){
pageNo = 1;
}
//條件搜索
SearchRequest searchRequest = new SearchRequest("jd_goods");
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
//分頁
sourceBuilder.from(pageNo);
sourceBuilder.size(pageSize);
//精準匹配
TermQueryBuilder termQueryBuilder = QueryBuilders.termQuery("title", keyword);
sourceBuilder.query(termQueryBuilder);
sourceBuilder.timeout(new TimeValue(60, TimeUnit.SECONDS));
//高亮
HighlightBuilder highlightBuilder = new HighlightBuilder();
highlightBuilder.field("title"); //高亮的欄位
highlightBuilder.requireFieldMatch(false); //多個高亮顯示
highlightBuilder.preTags("<span style='color:red'>");
highlightBuilder.postTags("</span>");
sourceBuilder.highlighter(highlightBuilder);
//執行搜索
searchRequest.source(sourceBuilder);
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
//決議結果
ArrayList<Map<String,Object>> list = new ArrayList<>();
for (SearchHit hit : searchResponse.getHits().getHits()) {
Map<String, HighlightField> highlightFields = hit.getHighlightFields();
HighlightField title = highlightFields.get("title");
Map<String,Object> sourceAsMap = hit.getSourceAsMap(); //原來的結果
//決議高亮的欄位
if(title != null){
Text[] fragments = title.fragments();
String new_title = "";
for (Text text : fragments) {
new_title += text;
}
sourceAsMap.put("title",new_title);//高亮欄位替換原來的內容即可
}
list.add(sourceAsMap);
}
return list;
}
}
8.3.2 控制層
ContentController
//請求撰寫
@Controller
public class ContentController {
@Autowired
private ContentService contentService;
@ResponseBody
@GetMapping("/parse/{keyword}")
public Boolean parse(@PathVariable("keyword") String keyword) throws Exception {
return contentService.parseContent(keyword);
}
@ResponseBody
@GetMapping("/search/{keyword}/{pageNo}/{pageSize}")
public List<Map<String,Object>> search(@PathVariable("keyword") String keyword,
@PathVariable("pageNo") int pageNo,
@PathVariable("pageSize") int pageSize) throws Exception {
return contentService.highlightSearch(keyword,pageNo,pageSize);
}
}
8.4 Index.html
<!DOCTYPE html>
<html xmlns:th="http://www.thymeleaf.org">
<head>
<meta charset="utf-8"/>
<title>狂神說Java-ES仿京東實戰</title>
<link rel="stylesheet" th:href="https://www.cnblogs.com/xiaoqigui/p/@{/css/style.css}"/>
<script th:src="https://www.cnblogs.com/xiaoqigui/p/@{/js/jquery.min.js}"></script>
<!-- <script src="https://www.cnblogs.com/xiaoqigui/static/js/jquery.min.js"></script>-->
<script th:src="https://www.cnblogs.com/xiaoqigui/p/@{/js/jquery.min.js}"></script>
</head>
<body >
<div id="app">
<div id="mallPage" >
<!-- 頭部搜索 -->
<div id="header" >
<div >
<div >
<!-- Logo-->
<h1 id="mallLogo">
<img th:src="https://www.cnblogs.com/xiaoqigui/p/@{/images/jdlogo.png}" alt="">
</h1>
<div >
<!--搜索-->
<div id="mallSearch" >
<form name="searchTop" >
<fieldset>
<legend>天貓搜索</legend>
<div >
<div id="s-combobox-685">
<div >
<input v-model="keyword" type="text" autocomplete="off" value="https://www.cnblogs.com/xiaoqigui/p/dd" id="mq"
aria-haspopup="true">
</div>
</div>
<button type="submit" @click.prevent="searchKey" id="searchbtn">搜索</button>
</div>
</fieldset>
</form>
<ul >
<li><a>狂神說Java</a></li>
<li><a>狂神說前端</a></li>
<li><a>狂神說Linux</a></li>
<li><a>狂神說大資料</a></li>
<li><a>狂神聊理財</a></li>
</ul>
</div>
</div>
</div>
</div>
</div>
<!-- 商品詳情頁面 -->
<div id="content">
<div >
<!-- 品牌分類 -->
<form >
<div style="display:block">
<div >
<div >
<div >
品牌
</div>
<div >
<ul >
<li><a href="https://www.cnblogs.com/xiaoqigui/p/#"> 狂神說 </a></li>
<li><a href="https://www.cnblogs.com/xiaoqigui/p/#"> Java </a></li>
</ul>
</div>
</div>
</div>
</div>
</form>
<!-- 排序規則 -->
<div >
<a >綜合<i ></i></a>
<a >人氣<i ></i></a>
<a >新品<i ></i></a>
<a >銷量<i ></i></a>
<a >價格<i ></i><i ></i></a>
</div>
<!-- 商品詳情 -->
<div >
<div v-for="result in results">
<div >
<!--商品封面-->
<div >
<a >
<img :src="https://www.cnblogs.com/xiaoqigui/p/result.img">
</a>
</div>
<!--價格-->
<p >
<em>{{result.price}}</em>
</p>
<!--標題-->
<p >
<a v-html="result.title"> </a>
</p>
<!-- 店鋪名 -->
<div >
<span>店鋪: 狂神說Java </span>
</div>
<!-- 成交資訊 -->
<p >
<span>月成交<em>999筆</em></span>
<span>評價 <a>3</a></span>
</p>
</div>
</div>
</div>
</div>
</div>
</div>
</div>
<script th:src="https://www.cnblogs.com/xiaoqigui/p/@{/js/vue.min.js}"></script>
<script th:src="https://www.cnblogs.com/xiaoqigui/p/@{/js/axios.min.js}"></script>
<script>
new Vue({
el:"#app",
data:{
"keyword": '', // 搜索的關鍵字
"results":[] // 后端回傳的結果
},
methods:{
searchKey(){
var keyword = this.keyword;
console.log(keyword);
//對接
axios.get('search/'+keyword+"/1/5").then(response=>{
console.log(response);
this.results = response.data; //
})
}
}
});
</script>
</body>
</html>
8.5 測驗結果
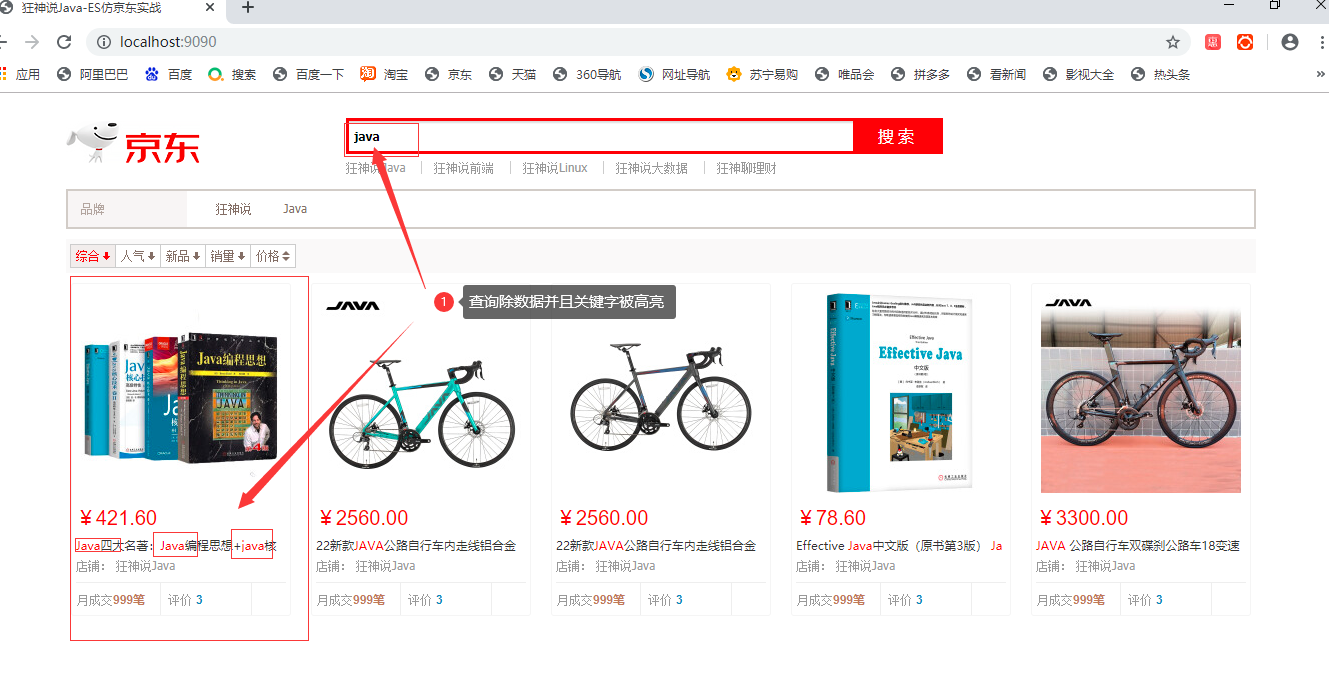
筆記視頻來源->B站狂神說Java的ElasticSearch課程
筆記部分參考-> ElasticSearch7.6入門學習筆記
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/500726.html
標籤:Java
上一篇:kafka~消費群組如何重新消費