前言
嗨嘍~大家好呀,這里是魔王吶 !
又是學習的一天,讓我們開始叭~

環境使用:
-
Python 3.8
-
Pycharm
模塊使用:
-
requests >>> pip install requests
-
re
-
csv
如果安裝python第三方模塊:
-
win + R 輸入 cmd 點擊確定, 輸入安裝命令 pip install 模塊名 (pip install requests) 回車
-
在pycharm中點擊Terminal(終端) 輸入安裝命令

基本流程思路: <通用>
一. 資料來源分析
-
抓包分析我們想要資料內容, 請求的那個網站 url地址得到
-
F12 或者 滑鼠右鍵點擊檢查選擇network, 點擊第二頁
-
選中xhr 第一個資料包就是我們想要的內容
用到開發者工具搜索功能
二. 代碼實作步驟程序: 固定四大步驟
-
發送請求, 對于剛剛分析得到url地址發送請求
-
獲取資料, 獲取服務器回傳回應資料 ---> 開發者工具里面response
-
決議資料, 提取我們想要資料內容 ---> 店鋪基本資訊
-
保存資料, 保存資料, 保存表格里面
-
多頁資料采集
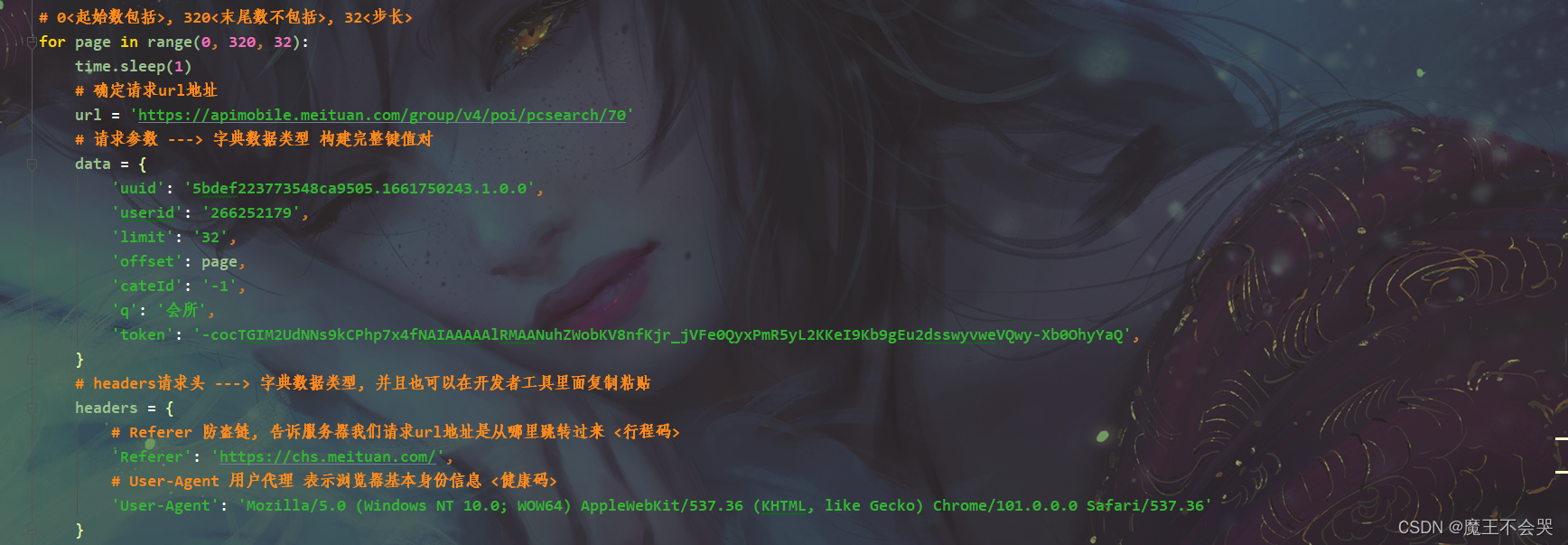
多頁資料采集 ---> 回圈 for <目的>
分析請求url地址引數變化

采集代碼
# 匯入資料請求模塊 ---> 第三方模塊 需要 pip install requests
import requests
# 匯入格式化輸出模塊 --> 內置模塊 不需要安裝
from pprint import pprint
# 匯入csv模塊 --> 內置模塊 不需要安裝
import csv
# 匯入時間模塊 --> 內置模塊 不需要安裝
import time
# 匯入正則模塊 --> 內置模塊 不需要安裝
import re

# 3. 發送請求
html_data = https://www.cnblogs.com/Qqun261823976/archive/2022/09/01/requests.get(url=link, headers=headers).text
# 4. 獲取資料print(html_data)
"""
5. 決議資料, re正則 會用 1 不會 2
re.findall() 找到所有我們想要資料
告訴程式: 從什么地方 去找什么資料
從 html_data 去找 "address":"(.*?)","phone":"(.*?)","openTime":"(.*?)", 這段內容
其中 (.*?) 就是我們要的資料
"""
shop_info = re.findall('"address":"(.*?)","phone":"(.*?)","openTime":"(.*?)",', html_data)[0]
print(shop_info)
# shop_info 元組 ---> [0] 根據索引位置取值 / 計數從0開始計數
address = shop_info[0]
# [1] 什么意思?
phone = shop_info[1]
# replace 是什么 字串替換方法 把 \\n 替換 空的 \<轉義字串> \n 還換行符
openTime = shop_info[2].replace('\\n', '')
print(address, phone, openTime)
# 創建檔案 相對路徑 你代碼在哪里 檔案就寫在哪里
f = open('男人的小秘密多頁.csv', mode='a', encoding='utf-8', newline='')
# 字典寫入 f ---> 檔案物件 fieldnames 欄位名 表頭表格第一行內容
csv_writer = csv.DictWriter(f, fieldnames=[
'店鋪',
'店鋪型別',
'商圈',
'人均消費',
'最低消費',
'評分',
'評論',
'緯度',
'經度',
'詳情頁',
])
# 寫入表頭
csv_writer.writeheader()
- 發送請求, 模擬瀏覽器發送請求
代碼都是可以復制粘貼
-
長鏈接可以分段寫入
-
批量替換 ---> 批量添加引號和逗號
1.選中替換內容
2.按 ctrl + R
3.勾選上.* 輸入正則命令
(.*?): (.*)
'$1': '$2',
- 如果當你請求網站, 被反爬的時候
一種最簡單反反爬手段, 用headers請求頭偽裝成瀏覽器去發送請求
# 發送請求
response = requests.get(url=url, params=data, headers=headers)
# <Response [403]>: 整體表示回應物件 403狀態碼 表示 沒有訪問權限
# <Response [200]> 200 狀態碼表示請求成功 print(response)
# 2. 獲取資料, 獲取服務器回傳回應資料 ---> 開發者工具里面response --> response.json() 獲取回應物件json字典資料 print(response.json())
# 3. 決議資料, 提取我們想要的資料內容 ---> 字典取值: 鍵值對取值 <根據冒號左邊的內容[鍵], 提取冒號右邊的內容[值]>
for index in response.json()['data']['searchResult']: # for回圈遍歷, 把串列里面元素一個一個提取出來

# 寫入資料
csv_writer.writerow(dit)
print(dit)
可視化代碼
import pandas as pd
import numpy as np
from pyecharts.charts import *
from pyecharts import options as opts
from pyecharts.globals import ThemeType #引入主題
df = pd.read_csv('武漢桌游多頁.csv',encoding='utf-8',engine="python")
df.sample(5)
df.info()
df = df.fillna('暫無資料')
cut = lambda x : '一般' if x <= 3.5 else ('不錯' if x <= 4.0 else('好' if x <= 4.5 else '很好'))
df['評分型別'] = df['評分'].map(cut)
df.describe()
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
plt.rcParams['font.sans-serif'] = ['SimHei'] # 設定加載的字體名
plt.rcParams['axes.unicode_minus'] = False # 解決保存影像是負號'-'顯示為方塊的問題
fig,axes=plt.subplots(2,1,figsize=(12,12))
sns.regplot(x='人均消費',y='評分',data=https://www.cnblogs.com/Qqun261823976/archive/2022/09/01/df,color='r',marker='+',ax=axes[0])
sns.regplot(x='評論',y='評分',data=https://www.cnblogs.com/Qqun261823976/archive/2022/09/01/df,color='g',marker='*',ax=axes[1])
df2 = df.groupby('商圈')['店名'].count()
df2 = df2.sort_values(ascending=True)[-10:]
df2 = df2.round(2)
c = (
Bar(init_opts=opts.InitOpts(theme=ThemeType.WONDERLAND))
.add_xaxis(df2.index.tolist())
.add_yaxis("",df2.tolist()).reversal_axis() #X軸與y軸調換順序
.set_global_opts(title_opts=opts.TitleOpts(title="武漢桌游商圈數量top10",subtitle="資料來源:美團",pos_left = 'center'),
xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(font_size=16)), #更改橫坐標字體大小
yaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(font_size=16)), #更改縱坐標字體大小
)
.set_series_opts(label_opts=opts.LabelOpts(font_size=16,position='right'))
)
c.render_notebook()
df4 = df.groupby('評分')['店名'].count()
df4 = df4.sort_values(ascending=False)
regions = df4.index.tolist()
values = df4.tolist()
c = (
Pie(init_opts=opts.InitOpts(theme=ThemeType.WONDERLAND))
.add("", [z for z in zip(regions,values)])
.set_global_opts(title_opts=opts.TitleOpts(title="不同評分型別店鋪數量",subtitle="資料來源:美團",pos_top="-1%",pos_left = 'center'))
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}:{d}%",font_size=18))
)
c.render_notebook()
df6 = df.groupby('店鋪型別')['店名'].count()
df6 = df6.sort_values(ascending=False)[:10]
df6 = df6.round(2)
regions = df6.index.tolist()
values = df6.tolist()
c = (
Pie(init_opts=opts.InitOpts(theme=ThemeType.WONDERLAND))
.add("", [i for i in zip(regions,values)],radius=["40%", "75%"])
.set_global_opts(title_opts=opts.TitleOpts(title="不同店鋪型別店鋪數量",pos_top="-1%",pos_left = 'center'))
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}",font_size=18))
)
c.render_notebook()
df6 = df.groupby('店鋪型別')['評分'].mean()
df6 = df6.sort_values(ascending=True)
df6 = df6.round(2)
df6 = df6.tail(10)
c = (
Bar(init_opts=opts.InitOpts(theme=ThemeType.WONDERLAND))
.add_xaxis(df6.index.tolist())
.add_yaxis("",df6.tolist()).reversal_axis() #X軸與y軸調換順序
.set_global_opts(title_opts=opts.TitleOpts(title="不同店鋪型別評分",subtitle="資料來源:美團",pos_left = 'center'),
xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(font_size=16)), #更改橫坐標字體大小
yaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(font_size=16)), #更改縱坐標字體大小
)
.set_series_opts(label_opts=opts.LabelOpts(font_size=16,position='right'))
)
c.render_notebook()
df7 = df.groupby('店鋪型別')['評論'].sum()
df7 = df7.sort_values(ascending=True)
df7 = df7.tail(10)
c = (
Bar(init_opts=opts.InitOpts(theme=ThemeType.WONDERLAND))
.add_xaxis(df7.index.tolist())
.add_yaxis("",df7.tolist()).reversal_axis() #X軸與y軸調換順序
.set_global_opts(title_opts=opts.TitleOpts(title="不同店鋪型別評論人數",subtitle="資料來源:美團",pos_left = 'center'),
xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(font_size=16)), #更改橫坐標字體大小
yaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(font_size=16)), #更改縱坐標字體大小
)
.set_series_opts(label_opts=opts.LabelOpts(font_size=16,position='right'))
)
c.render_notebook()
尾語
要成功,先發瘋,下定決心往前沖!
學習是需要長期堅持的,一步一個腳印地走向未來!
未來的你一定會感謝今天學習的你,
—— 心靈雞湯
本文章到這里就結束啦~感興趣的小伙伴可以復制代碼去試試哦 ??
對啦!!記得三連哦~ ?? 另外,歡迎大家閱讀我往期的文章呀~

轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/503352.html
標籤:其他
上一篇:java中的一維陣列
下一篇:day30-注解