C Primer Plus 摘錄
第 10 章 陣列和指標
10.1 陣列
-
陣列由資料型別相同的一系列元素組成,
-
通過宣告陣列告訴編譯器陣列中內含多少元素和這些元素的型別, 編譯器根據這些資訊正確地創建陣列,
float candy[365];
char code[12];
int states[50];
-
方括號
[]表明candy、 code和states都是陣列, 方括號中的數字表明陣列中的元素個數, -
要訪問陣列中的元素, 通過使用陣列下標數(也稱為索引) 表示陣列中
的各元素, 陣列元素的編號從0開始,
10.1.1 初始化陣列
- 用以逗號分隔的值串列(用花括號括起來) 來初始化陣列,各值之間用逗號分隔,
int powers[8] = {1,2,4,6,8,16,32,64};
-
推薦使用宏定義陣列長度,只需修改
#define這行代碼即可 -
要創建只讀陣列, 應該用
const宣告和初始化陣列
const int days[MONTHS] = {31,28,31,30,31,30,31,31,30,31,30,31};
-
存盤類別警告:陣列和其他變數類似, 可以把陣列創建成不同的存盤類別(storage class),第12章將介紹存盤類別的相關內容,本章描述的陣列屬于自動存盤類別
-
當初始化串列中的值少于陣列元素個數時, 編譯器會把剩余的元素都初始化為
0, -
如果初始化串列的項數多于陣列元素個數, 編譯器可沒那么仁慈, 它會毫不留情地將其視為錯誤,
-
如果初始化陣列時省略方括號中的數字, 編譯器會根據初始化串列中的項數來確定陣列的大小,
const int days[] = { 31, 28, 31, 30, 31, 30, 31, 31, 30, 31 };
sizeof days是整個陣列的大小(以位元組為單位),sizeof day[0]是陣列中一個元素的大小(以位元組為單位),整個陣列的大小除以單個元素的大小就是陣列元素的個數,
10.1.2 指定初始化器(C99)
-
C99 增加了一個新特性: 指定初始化器(designated initializer) , 利用該特性可以初始化指定的陣列元素,
-
對于傳統的C初始化語法,要初始化指定元素,則必須同時初始化其之前的所有元素,
int arr[6] = {0,0,0,0,0,212}; // 傳統的語法
int arr[6] = {[5] = 212}; // 把arr[5]初始化為212
- 第一, 如果指定初始化器后面有更多的值, 如該例中的初始化串列中的片段:
[4] = 31,30,31, 那么后面這些值將被用于初始化指定元素后面的元素, - 第二, 如果再次初始化指定的元素, 那么最后的初始化將會取代之前的初始化, 如開始時把
days[1]初始化為 28, 但是days[1]又被后面的指定初始化[1] = 29初始化為 29,
int days[MONTHS] = { 31, 28, [4] = 31, 30, 31, [1] = 29 };
10.1.3 給陣列元素賦值
- 宣告陣列后, 可以借助陣列下標(或索引) 給陣列元素賦值,
10.1.4 陣列邊界
-
在使用陣列時, 要防止陣列下標超出邊界, 也就是說, 必須確保下標是有效的值,
-
歸功于 C 信任程式員的原則, 不檢查邊界, C 程式可以運行更快, 編譯器不會檢查陣列下標是否使用得當, 在C標準中, 使用越界下標的結果是未定義的, 這意味著程式看上去可以運行, 但是運行結果很奇怪, 或例外中止,
10.1.5 指定陣列的大小
- 在C99標準之前, 宣告陣列時只能在方括號中使用「整型常量運算式」, 所謂整型常量運算式, 是由整型常量構成的運算式,
sizeof運算式被視為整型常量, 但是(與C++不同)const值不是, 另外, 運算式的值必須大于 0
int n = 5;
int m = 8;
float a1[5]; // 可以
float a2[5*2 + 1]; //可以
float a3[sizeof(int) + 1]; //可以
float a4[-4]; // 不可以, 陣列大小必須大于0
float a5[0]; // 不可以, 陣列大小必須大于0
float a6[2.5]; // 不可以, 陣列大小必須是整數
float a7[(int)2.5]; // 可以, 已被強制轉換為整型常量
float a8[n]; // C99之前不允許
float a9[m]; // C99之前不允許
- C99標準允許這樣宣告, 這創建了一種新型陣列, 稱為變長陣列(variable-length array) 或簡稱 VLA(C11 放棄了這一創新的舉措, 把VLA設定為可選, 而不是語言必備的特性),
- C99引入變長陣列主要是為了讓C成為更好的數值計算語言,
10.2 多維陣列
- 多維陣列是這樣一種陣列,它是一種陣列,它的每個元素也是包含指定元素數量的陣列,
float rain[5][12]; // 內含 5 個元素的陣列, 每個元素本身是一個內含12個 float 型別值的陣列
-
上述宣告中
rain[5]表明rain是一個內含 5 個元素的陣列;float [12]說明每個元素的型別是float[12] -
rain[i]是一個內含12個 float 型別值的陣列,因此該陣列的首元素就是rain[i][0],第 2 個元素是rain[0][1],以此類推,要訪問第 i 個陣列的第 j 個元素(編號從 0 開始)即為rain[i][j]
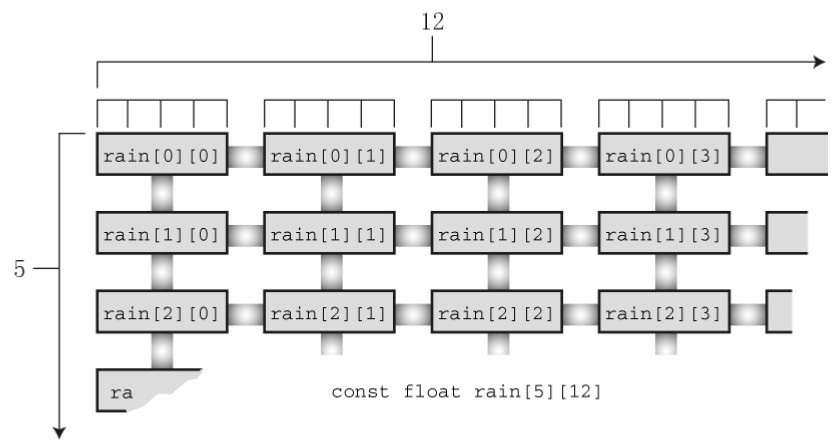
-
該二維視圖有助于幫助讀者理解二維陣列的兩個下標, 在計算機內部,這樣的陣列是按順序儲存的, 從第1個內含12個元素的陣列開始, 然后是第2個內含12個元素的陣列, 以此類推,
-
遍歷二維陣列常用兩個嵌套的
for回圈,一個回圈處理陣列的第1個下標, 另一個回圈處理陣列的第2個下標,
10.2.1 初始化二維陣列
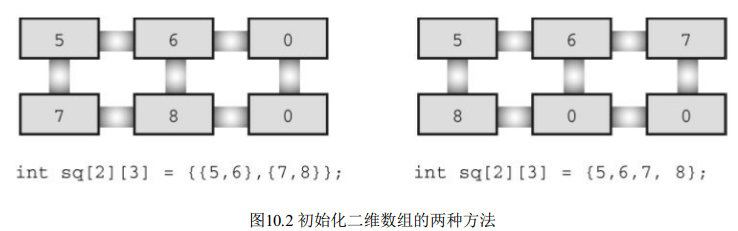
- 初始化二維陣列是建立在初始化一維陣列的基礎上, 首先, 初始化一維陣列如下:
sometype ar1[5] = {val1, val2, val3, val4, val5};
- 對于二維陣列
rain[5][12],rain是一個內含 5 個元素的陣列, 每個元素又是內含12個float型別元素的陣列, 所以, 對rain而言,val1應該包含 12 個值, 用于初始化內含 12 個float型別元素的一維陣列,
const float rain[5][12] =
{
{4.3,4.3,4.3,3.0,2.0,1.2,0.2,0.2,0.4,2.4,3.5,6.6},
{8.5,8.2,1.2,1.6,2.4,0.0,5.2,0.9,0.3,0.9,1.4,7.3},
{9.1,8.5,6.7,4.3,2.1,0.8,0.2,0.2,1.1,2.3,6.1,8.4},
{7.2,9.9,8.4,3.3,1.2,0.8,0.4,0.0,0.6,1.7,4.3,6.2},
{7.6,5.6,3.8,2.8,3.8,0.2,0.0,0.0,0.0,1.3,2.6,5.2}
};
// 使用了 5 個數值串列(花括號括起來),逗號分隔來初始化二維陣列
// 第一個串列初始化第一個元素,依次類推,
- 初始化時也可省略內部的花括號, 只保留最外面的一對花括號,
- 如果初始化的數值不夠, 則按照先后順序逐行初始化, 直到用完所有的值,
10.2.2 其他多維陣列
- 可以把一維陣列想象成一行資料, 把二維陣列想象成資料表, 把三維陣列想象成一疊資料表,
10.3 指標和陣列
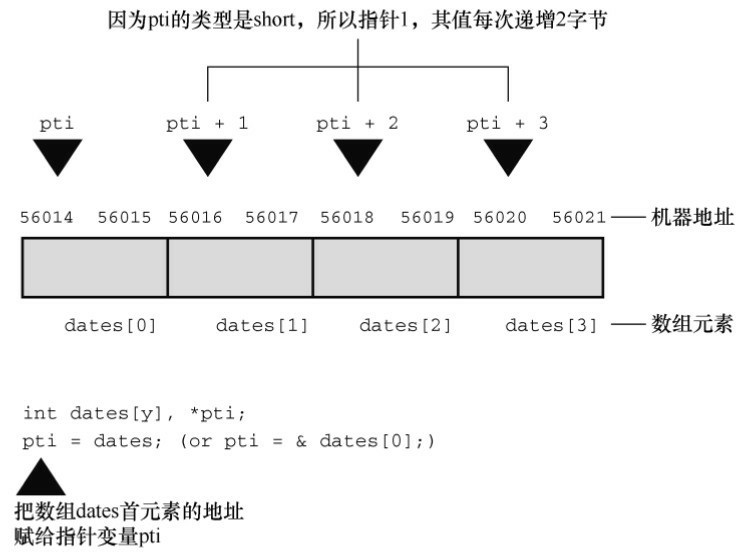
陣列名是陣列首元素的地址
- 在 C 中, 指標加 1 指的是增加一個存盤單元, 對陣列而言, 這意味著把加 1 后的地址是下一個元素的地址, 而不是下一個位元組的地址(見圖10.3) ,
- 這是為什么必須宣告指標所指向物件型別的原因之一,只知道地址不夠, 因為計算機要知道儲存物件需要多少位元組(即使指標指向的是標量變數, 也要知道變數的型別, 否則
*pt就無法正確地取回地址上的值) ,
-
指標的值是它所指向物件的地址, 地址的表示方式依賴于計算機內部的硬體, 許多計算機(包括PC和Macintosh) 都是按位元組編址, 意思是記憶體中的每個位元組都按順序編號, 這里, 一個較大物件的地址(如double型別的變數) 通常是該物件第一個位元組的地址,
-
在指標前面使用
*運算子可以得到該指標所指向物件的值, -
指標加 1, 指標的值遞增它所指向型別的大小(
sizeof type以位元組為單位)
dates + 2 == &date[2] // 相同的地址
*(dates + 2) == dates[2] // 相同的值
-
以上關系表明了陣列和指標的關系十分密切, 可以使用指標標識陣列的元素和獲得元素的值, 從本質上看, 同一個物件有兩種表示法, 定義
ar[n]的意思是*(ar + n), 可以認為*(ar + n)的意思是“到記憶體的ar位置, 然后移動 n 個單元, 檢索儲存在那里的值”, -
不要混淆
*(dates+2)和*dates+2, 間接運算子*的優先級高于+, 所以*dates+2相當于(*dates)+2
明白了陣列和指標的關系, 便可在撰寫程式時適時使用陣串列示法或指標表示法,
指標表示法和陣串列示法是兩種等效的方法,編譯器編譯這兩種寫法生成的代碼相同,
10.4 函式、 陣列和指標
- 陣列名是該陣列首元素的地址,所以陣列作為函式的引數時,第一個引數是陣列名,也就是第一個元素的地址,它是一個指標型別,第二個引數是陣列的大小,它是一個整型變數,
第1個形參告訴函式該陣列的地址和資料型別, 第2個形參告訴函式該陣列中元素的個數
int sum(int* ar, int n);
- 只有在函式原型或函式定義頭中,才可以用
int ar[]代替int *ar:int *ar形式和int ar[]形式都表示ar是一個指向int的指標, 但是,int ar[]只能用于宣告形式引數, 第 2 種形式int ar[]提醒讀者指標ar指向的不僅僅一個int型別值, 還是一個int型別陣列的元素
int sum (int ar[], int n);
- 下面 4 中原型是等價的:
int sum(int *ar, int n);
int sum(int *, int);
int sum(int ar[], int n);
int sum(int [], int);
- 我們的系統中用 8 位元組儲存地址, 所以指標變數的大小是 8位元組(其他系統中地址的大小可能不是8位元組) ,
10.4.1 使用指標形參
- 函式要處理陣列必須知道何時開始、 何時結束,
還有一種方法是傳遞兩個指標, 第1個指標指明陣列的開始處(與前面用法相同) , 第2個指標指明陣列的結束處,
int sump(int* start, int* end)
{
int total = 0;
while(start < end)
{
total += *start;// 把陣列元素的值加起來
start++;
}
return total;
}
- while回圈的測驗條件是一個不相等的關系, 所以回圈最后處理的一個元素是end所指向位置的前一個元素, 這意味著end指向的位置實際上在最后一個元素的后一個位置,
// 因為下標從0開始, 所以 marbles + SIZE 指向陣列末尾的下一個位置,
answer = sump(marbles, marbles + SIZE);
-
可以把回圈體壓縮成一行代碼:
total += *start++;一元運算子*和++的優先級相同, 但結合律是從右往左, 所以start++先求值, 然后才是*start,10.4.2 指標表示法和陣串列示法
-
處理陣列的函式實際上用指標作為引數, 但是在撰寫這樣的函式時, 可以選擇是使用陣串列示法還是指標表示法,
-
ar[i]和*(ar+1)這兩個運算式都是等價的, 無論ar是陣列名還是指標變數, 這兩個運算式都沒問題, 但是, 只有當ar是指標變數時, 才能使用ar++這樣的運算式, -
指標表示法(尤其與遞增運算子一起使用時) 更接近機器語言, 因此一些編譯器在編譯時能生成效率更高的代碼,然而, 許多程式員認為他們的主要任務是確保代碼正確、 邏輯清晰, 而代碼優化應該留給編譯器去做,
10.5 指標操作
指標變數的 9 種基本操作
-
賦值: 可以把地址賦給指標,
-
解參考:
*運算子給出指標指向地址上儲存的值, -
取址: 和所有變數一樣, 指標變數也有自己的地址和值,
-
指標與整數相加: 可以使用
+運算子把指標與整數相加, 或整數與指標相加,如果相加的結果超出了初始指標指向的陣列范圍, 計算結果則是未定義的,- 整數都會和指標所指向型別的大小(以位元組為單位)相乘, 然后把結果與初始地址相加,
-
遞增指標: 遞增指向陣列元素的指標可以讓該指標移動至陣列的下一個元素,
-
指標減去一個整數: 可以使用-運算子從一個指標中減去一個整數,指標必須是第1個運算物件, 整數是第 2 個運算物件,
- 該整數將乘以指標指向型別的大小(以位元組為單位) , 然后用初始地址減去乘積,
-
遞減指標: 當然, 除了遞增指標還可以遞減指標,
-
指標求差: 可以計算兩個指標的差值, 通常, 求差的兩個指標分別指向同一個陣列的不同元素, 通過計算求出兩元素之間的距離, **差值的單位與陣列型別的單位相同,如
ptr2 - ptr1得 2, 意思是這兩個指標所指向的兩個元素相隔兩個int, 而不是 2 位元組, -
比較: 使用關系運算子可以比較兩個指標的值, 前提是兩個指標都指向相同型別的物件,
-
在遞增或遞減指標時還要注意一些問題, 編譯器不會檢查指標是否仍指向陣列元素,
-
千萬不要解參考未初始化的指標,在使用指標之前, 必須先用已分配的地址初始化它, 例如, 可以用一個現有變數的地址初始化該指標(使用帶指標形參的函式時, 就屬于這種情況) ,或者還可以使用第 12 章將介紹的
malloc()函式先分配記憶體,
指標的第 1 個基本用法是在函式間傳遞資訊,前面學過, 如果希望在被調函式中改變主調函式的變數, 必須使用指標, 指標的第 2 個基本用法是用在處理陣列的函式中,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/523156.html
標籤:其他