python爬蟲基本概述
一、爬蟲是什么
網路爬蟲(Crawler)又稱網路蜘蛛,或者網路機器人(Robots). 它是一種按照一定的規則, 自動地抓取萬維網資訊的程式或者腳本,換句話來說,它可以根據網頁的鏈接地址自動獲取網頁 內容,如果把互聯網比做一個大蜘蛛網,它里面有許許多多的網頁,網路蜘蛛可以獲取所有網頁 的內容,
爬蟲是一個模擬人類請求網站行為, 并批量下載網站資源的一種程式或自動化腳本,
二、爬蟲可以做什么
1. 搜索引擎
2. 采集金融資料
3. 采集商品資料
4. 采集競爭對手的客戶資料
5. 采集行業相關資料,進行資料分析
6. 刷流量
三、爬蟲的分類
1、通用網路爬蟲 又稱為全網爬蟲,其爬取物件由一批 URL 擴充至整個 Web,主要由搜索引擎或大型 Web 服 務商使用,
2、聚焦網路爬蟲 又稱為主題網路爬蟲,其特點是只選擇性的地爬取與預設的主題相關的頁面,相比通用網 絡爬蟲,聚焦網路爬蟲僅需要爬取與主題相關的頁面,極大地節省硬體及網路資源,能更 快的更新保存頁面,更好的滿足特定人群對特定領域的需求,
3、增量網路爬蟲 只對已下載的網頁采取增量式更新,或只爬取新產生的及已經發生變化的網頁,這種機制 能夠在某種程度上保證所爬取的網頁盡可能的新,
4、深度網路爬蟲 Web 頁面按照存在的方式可以分為表層頁面和深層頁面兩類,表層頁面是只傳統搜索引擎 可以索引到的頁面,以超鏈接可以達到的靜態頁面為主,深層頁面是指大部分內容無法通 過靜態鏈接獲取,隱藏在搜索表單之后的,需要用戶提交關鍵詞后才能獲得的 Web 頁面, 如一些登陸后可見的網頁,
四、爬蟲的基本流程
1、瀏覽網頁的流程
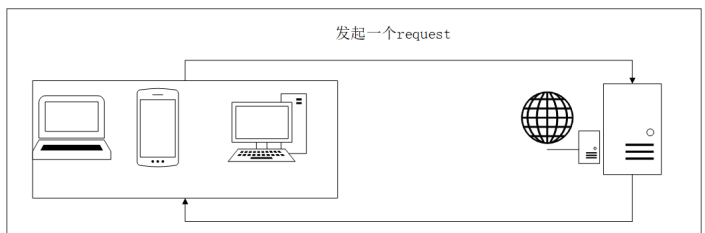
2 、爬蟲的基本流程
1. 請求網頁 通過 HTTP 庫向目標站點發起請求,即發送一個 Request,請求可以包含額外的 headers 等 資訊,等待服務器回應!
2. 獲得相應內容 如果服務器能正常回應,會得到一個 Response,Response 的內容便是所要獲取的頁面內容, 型別可能有 HTML,Json 字串,二進制資料(如圖片視頻)等型別,
3. 決議內容 得到的內容可能是 HTML,可以用正則運算式、網頁決議庫進行決議,可能是Json,可以 直接轉為 Json 物件決議,可能是二進制資料,可以做保存或者進一步的處理,
4. 存盤決議的資料 保存形式多樣,可以存為文本,也可以保存至資料庫,或者保存特定格式的檔案
3 、爬蟲的測驗案例
爬取搜狗首頁的頁面資料
# 導包 import requests # step_1 : 指定url url ='https://www.sogou.com/' # step_2 : 發起請求: # 使用get 方法發起get 請求, 該方法會回傳一個回應物件,引數url 表示請求對應的url response = requests.get ( url = url ) # step_3 : 獲取回應資料: # 通過呼叫回應物件的text 屬性, 回傳回應物件中存盤的字串形式的回應資料( 頁面原始碼資料) page_text = response . text # step_4 : 持久化存盤 with open ('sogou.html','w',encoding ='utf -8') as fp: fp.write (page_text) print ('爬取資料完畢! ! !')

得到sogou.html
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/523883.html
標籤:其他