?我們先來看看這張圖,這是某公司使用的大資料平臺架構圖,大部分公司應該都差不多:
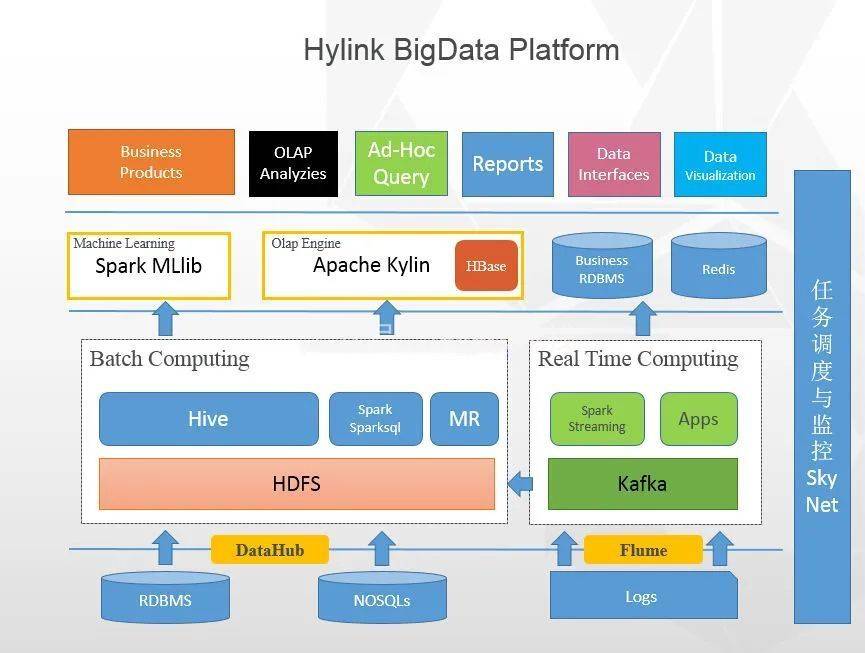
從這張大資料的整體架構圖上看來,大資料的核心層應該是:資料采集層、資料存盤與分析層、資料共享層、資料應用層,可能叫法有所不同,本質上的角色都大同小異,
所以我下面就按這張架構圖上的線索,慢慢來剖析一下,大資料的核心技術都包括什么,
一、資料采集
資料采集的任務就是把資料從各種資料源中采集和存盤到資料存盤上,期間有可能會做一些簡單的清洗,
資料源的種類比較多:
- 網站日志:
作為互聯網行業,網站日志占的份額最大,網站日志存盤在多臺網站日志服務器上,一般是在每臺網站日志服務器上部署flume agent,實時的收集網站日志并存盤到HDFS上;
- 業務資料庫:
業務資料庫的種類也是多種多樣,有Mysql、Oracle、SqlServer等,這時候,我們迫切的需要一種能從各種資料庫中將資料同步到HDFS上的工具,Sqoop是一種,但是Sqoop太過繁重,而且不管資料量大小,都需要啟動MapReduce來執行,而且需要Hadoop集群的每臺機器都能訪問業務資料庫;應對此場景,淘寶開源的DataX,是一個很好的解決方案,有資源的話,可以基于DataX之上做二次開發,就能非常好的解決,
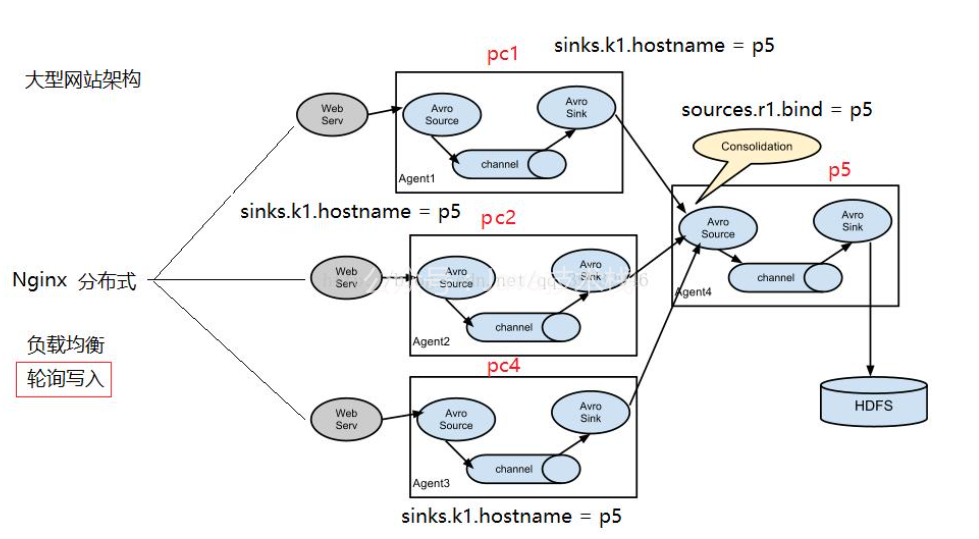
當然,Flume通過配置與開發,也可以實時的從資料庫中同步資料到HDFS,
- 來自于Ftp/Http的資料源:
有可能一些合作伙伴提供的資料,需要通過Ftp/Http等定時獲取,DataX也可以滿足該需求;
- 其他資料源:
比如一些手工錄入的資料,只需要提供一個介面或小程式,即可完成;
二、資料存盤與分析
毋庸置疑,HDFS是大資料環境下資料倉庫/資料平臺最完美的資料存盤解決方案,
離線資料分析與計算,也就是對實時性要求不高的部分,在筆者看來,Hive還是首當其沖的選擇,豐富的資料型別、內置函式;壓縮比非常高的ORC檔案存盤格式;非常方便的SQL支持,使得Hive在基于結構化資料上的統計分析遠遠比MapReduce要高效的多,一句SQL可以完成的需求,開發MR可能需要上百行代碼;
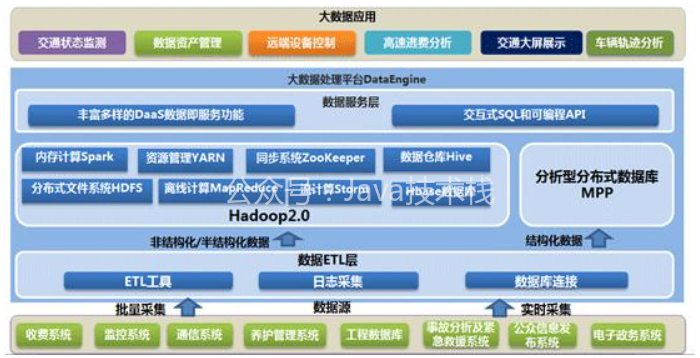
當然,使用Hadoop框架自然而然也提供了MapReduce介面,如果真的很樂意開發Java,或者對SQL不熟,那么也可以使用MapReduce來做分析與計算;
Spark是這兩年非常火的,經過實踐,它的性能的確比MapReduce要好很多,而且和Hive、Yarn結合的越來越好,因此,必須支持使用Spark和SparkSQL來做分析和計算,因為已經有Hadoop Yarn,使用Spark其實是非常容易的,不用單獨部署Spark集群,
三、資料共享
這里的資料共享,其實指的是前面資料分析與計算后的結果存放的地方,其實就是關系型資料庫和NOSQL資料庫;
前面使用Hive、MR、Spark、SparkSQL分析和計算的結果,還是在HDFS上,但大多業務和應用不可能直接從HDFS上獲取資料,那么就需要一個資料共享的地方,使得各業務和產品能方便的獲取資料;和資料采集層到HDFS剛好相反,這里需要一個從HDFS將資料同步至其他目標資料源的工具,同樣,DataX也可以滿足,
另外,一些實時計算的結果資料可能由實時計算模塊直接寫入資料共享,
四、資料應用
- 業務產品(CRM、ERP等)
業務產品所使用的資料,已經存在于資料共享層,直接從資料共享層訪問即可;
- 報表(FineReport、業務報表)
同業務產品,報表所使用的資料,一般也是已經統計匯總好的,存放于資料共享層;
- 即席查詢
即席查詢的用戶有很多,有可能是資料開發人員、網站和產品運營人員、資料分析人員、甚至是部門老大,他們都有即席查詢資料的需求;
這種即席查詢通常是現有的報表和資料共享層的資料并不能滿足他們的需求,需要從資料存盤層直接查詢,
即席查詢一般是通過SQL完成,最大的難度在于回應速度上,使用Hive有點慢,可以用SparkSQL,它的回應速度較Hive快很多,而且能很好的與Hive兼容,
當然,你也可以使用Impala,如果不在乎平臺中再多一個框架的話,
- OLAP
目前,很多的OLAP工具不能很好的支持從HDFS上直接獲取資料,都是通過將需要的資料同步到關系型資料庫中做OLAP,但如果資料量巨大的話,關系型資料庫顯然不行;
這時候,需要做相應的開發,從HDFS或者HBase中獲取資料,完成OLAP的功能;比如:根據用戶在界面上選擇的不定的維度和指標,通過開發介面,從HBase中獲取資料來展示,
- 其它資料介面
這種介面有通用的,有定制的,比如:一個從Redis中獲取用戶屬性的介面是通用的,所有的業務都可以呼叫這個介面來獲取用戶屬性,
五、實時計算
現在業務對資料倉庫實時性的需求越來越多,比如:實時的了解網站的整體流量;實時的獲取一個廣告的曝光和點擊;在海量資料下,依靠傳統資料庫和傳統實作方法基本完成不了,需要的是一種分布式的、高吞吐量的、延時低的、高可靠的實時計算框架;Storm在這塊是比較成熟了,但我選擇Spark Streaming,原因很簡單,不想多引入一個框架到平臺中,另外,Spark Streaming比Storm延時性高那么一點點,那對于我們的需要可以忽略,
我們目前使用Spark Streaming實作了實時的網站流量統計、實時的廣告效果統計兩塊功能,
做法也很簡單,由Flume在前端日志服務器上收集網站日志和廣告日志,實時的發送給Spark Streaming,由Spark Streaming完成統計,將資料存盤至Redis,業務通過訪問Redis實時獲取,
六、任務調度與監控
在資料倉庫/資料平臺中,有各種各樣非常多的程式和任務,比如:資料采集任務、資料同步任務、資料分析任務等;
這些任務除了定時調度,還存在非常復雜的任務依賴關系,比如:資料分析任務必須等相應的資料采集任務完成后才能開始;資料同步任務需要等資料分析任務完成后才能開始;
這就需要一個非常完善的任務調度與監控系統,它作為資料倉庫/資料平臺的中樞,負責調度和監控所有任務的分配與運行,
參考:http://lxw1234.com/archives/2015/08/471.htm
近期熱文推薦:
1.1,000+ 道 Java面試題及答案整理(2022最新版)
2.勁爆!Java 協程要來了,,,
3.Spring Boot 2.x 教程,太全了!
4.別再寫滿屏的爆爆爆炸類了,試試裝飾器模式,這才是優雅的方式!!
5.《Java開發手冊(嵩山版)》最新發布,速速下載!
覺得不錯,別忘了隨手點贊+轉發哦!
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/528708.html
標籤:Java