0. 目錄
1)MySQL總體架構介紹
2)MySQL存盤引擎調優
3)常用慢查詢分析工具
4)如何定位不合理的SQL
5)SQL優化的一些建議
1 MySQL總體架構介紹
1.1 MySQL總體架構介紹
引言
MySQL是一個關系型資料庫
應用十分廣泛
在學習任何一門知識之前
對其架構有一個概括性的了解是非常重要的
比如索引、sql是在哪個地方執行的
流程是什么樣的
今天我們就先來學習一下MySQL的總體架構
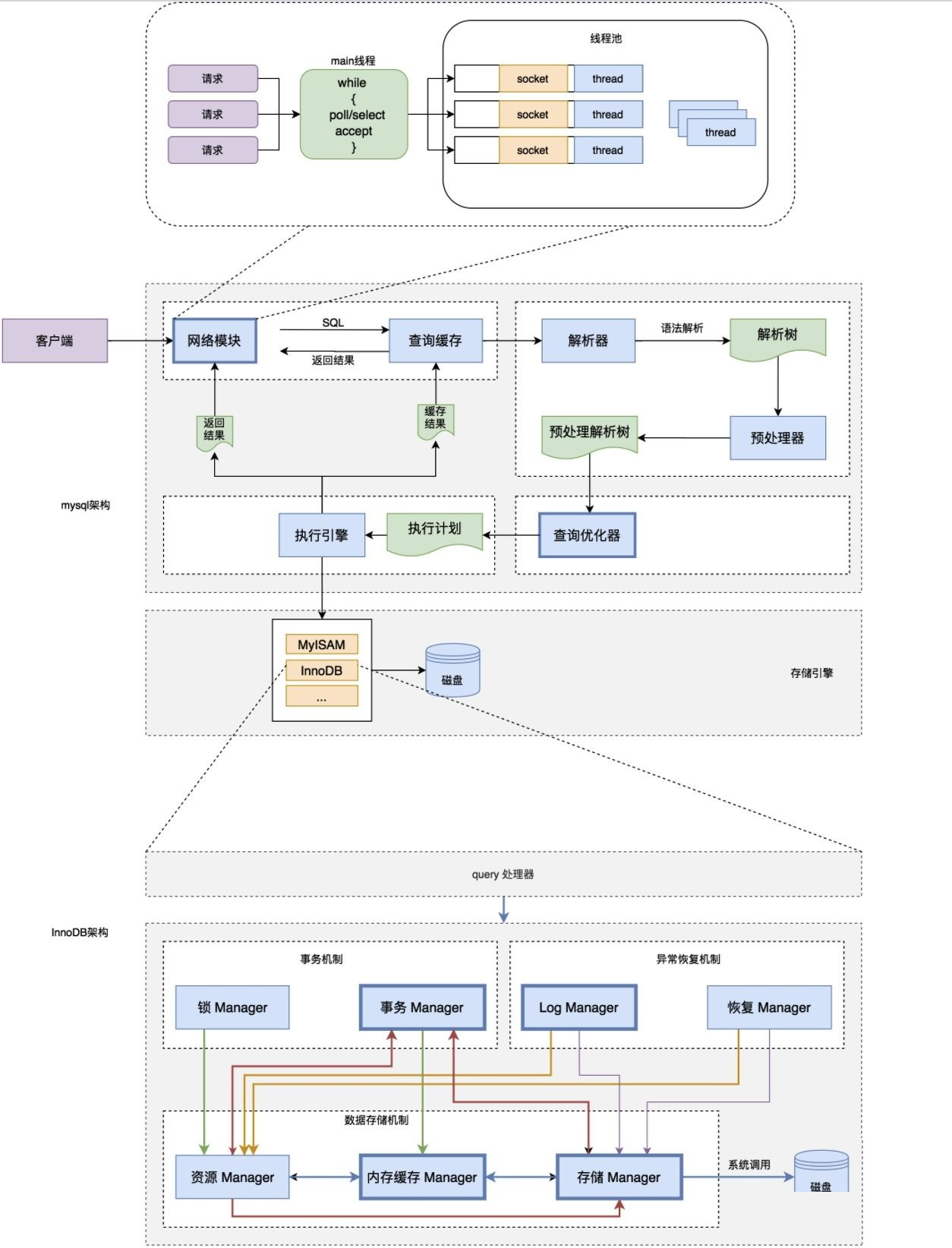
總的來說:MySQL架構是一個客戶端-服務器系統,
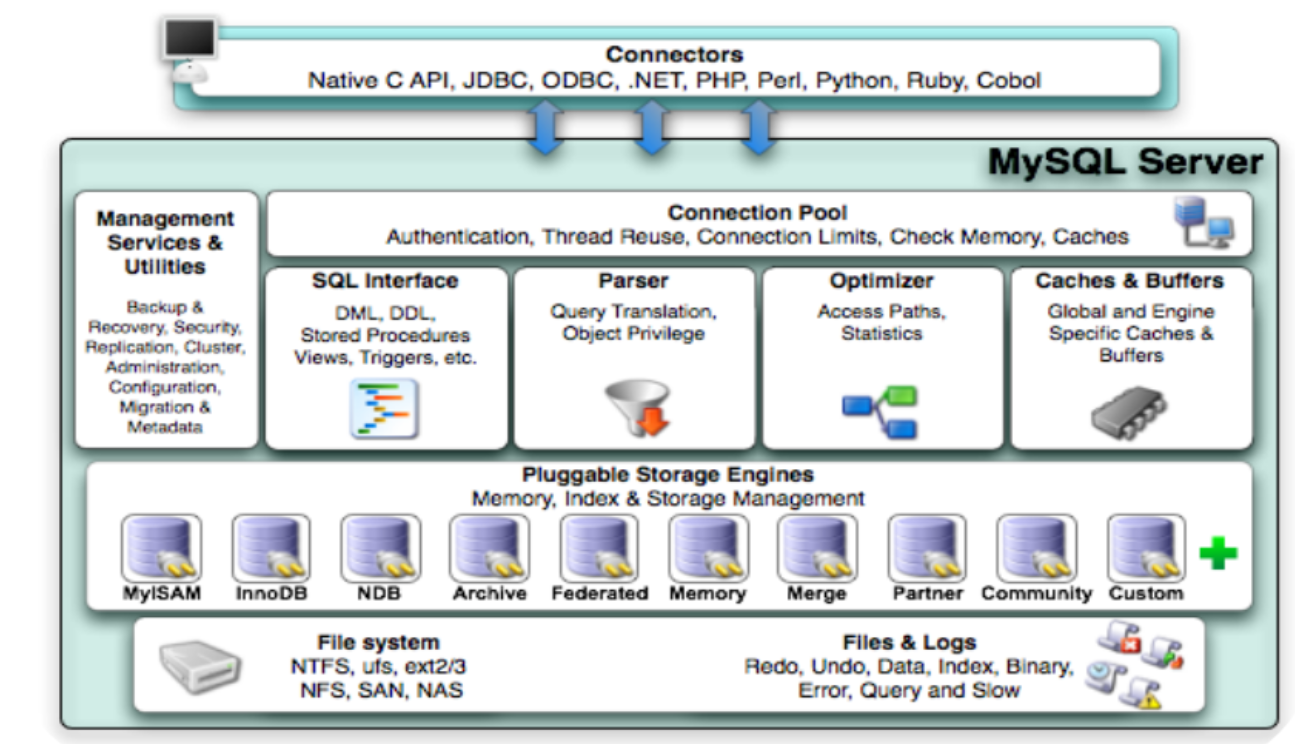
MySQL主要包括以下幾部分:
Server 層:主要包括連接器、查詢快取、分析器、優化器、執行器等,所有跨存盤引擎的功能都在這一層實作,比如存盤程序、觸發器、視圖,函式等,還有一個通用的日志模塊 binglog 日志模塊,
存盤引擎: 主要負責資料的存盤和讀取,采用可以替換的插件式架構,支持 InnoDB、MyISAM、Memory 等多個存盤引擎,其中 InnoDB 引擎有自己的日志模塊 redolog 模塊,現在最常用的存盤引擎是 InnoDB,它從 MySQL 5.5.5 版本開始就被當做默認存盤引擎了
連接器: 身份認證和權限相關(登錄 MySQL 的時候),
查詢快取: 執行查詢陳述句的時候,會先查詢快取(MySQL 8.0 版本后移除,因為這個功能不太實用)mysql的server層增加一層快取模塊,類似一個記憶體的kv層,k是sql,value是結果
分析器: 沒有命中快取的話,SQL 陳述句就會經過分析器,分析器說白了就是要先看你的 SQL 陳述句要干嘛,再檢查你的 SQL 陳述句語法是否正確,
優化器: 按照 MySQL 認為最優的方案去執行,
執行器: 執行陳述句,然后從存盤引擎回傳資料,
1.2 MySQL存盤引擎介紹
引言
和大多數的資料庫不同, MySQL中有一個存盤引擎的概念
針對不同的存盤需求可以選擇最優的存盤引擎,
存盤引擎就是存盤資料,建立索引,更新查詢資料等等技術的實作方式 ,
存盤引擎是基于表的,而不是基于庫的
所以存盤引擎也可被稱為表型別,
MySQL提供了插件式的存盤引擎架構,所以MySQL存在多種存盤引擎,可以根據需要使用相應引擎,或者撰寫存盤引擎,
MySQL5.0支持的存盤引擎包含 : InnoDB 、MyISAM 、BDB、MEMORY、MERGE、EXAMPLE、NDB Cluster、ARCHIVE、CSV、BLACKHOLE、FEDERATED等
可以通過指定 show engines , 來查詢當前資料庫支持的存盤引擎 :
SHOW ENGINES;
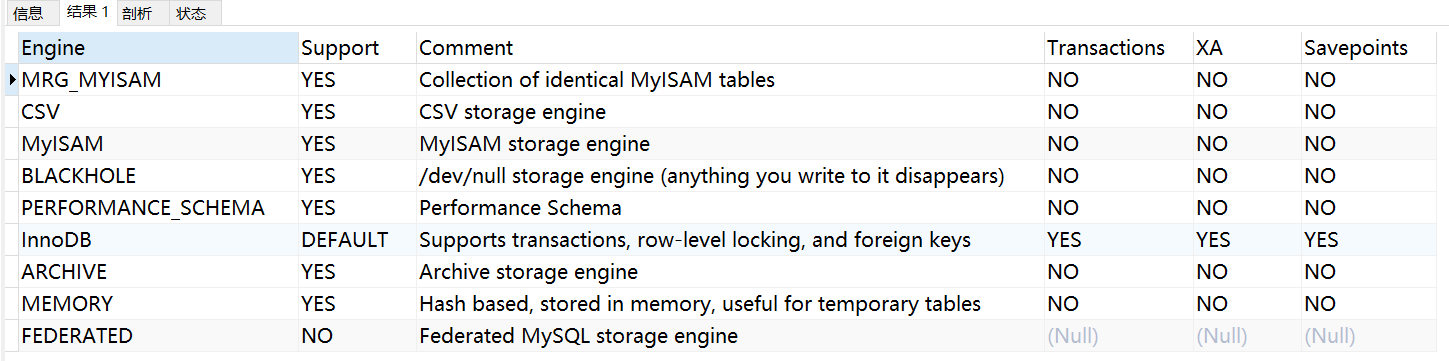
表含義:
- support : 指服務器是否支持該存盤引擎
- transactions : 指存盤引擎是否支持事務
- XA : 指存盤引擎是否支持分布式事務處理
- Savepoints : 指存盤引擎是否支持保存點(實作回滾到指定保存點)
-
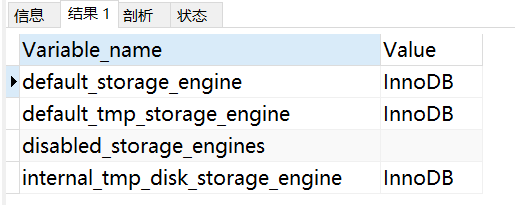
查看MySQL資料庫存盤引擎配置
SHOW VARIABLES LIKE '%storage_engine%';
1.2.1 如何更改資料庫表引擎
- 建表陳述句后面加入引擎賦值即可 ,命令舉例如下 ,
CREATE TABLE t1(
id INT ,
name VARCHAR(20)
) ENGINE = MyISAM;
- 修改已有的表引擎 , 命令舉例如下 ,
ALTER TABLE t1 ENGINE = InnoDB;
1.2.2 常用引擎及其特性對比
-
常見的存盤引擎 :
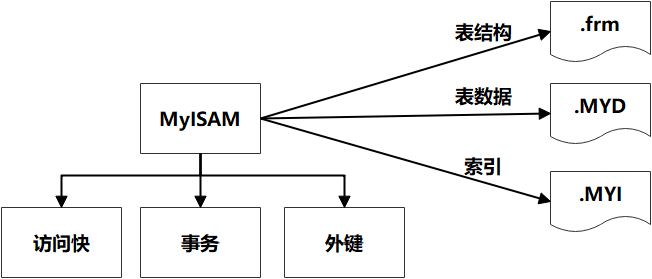
MyISAM存盤引擎 : 訪問快,不支持事務和外鍵,表結構保存在.frm檔案中,表資料保存在.MYD檔案中,索引保存在.MYI檔案中,
[root@linux-141 itcast]# ll -rw-r-----. 1 mysql mysql 8630 9月 10 16:01 t_account_myisam.frm -rw-r-----. 1 mysql mysql 52 9月 10 16:06 t_account_myisam.MYD -rw-r-----. 1 mysql mysql 2048 9月 10 17:56 t_account_myisam.MYI [root@linux-141 itcast]#
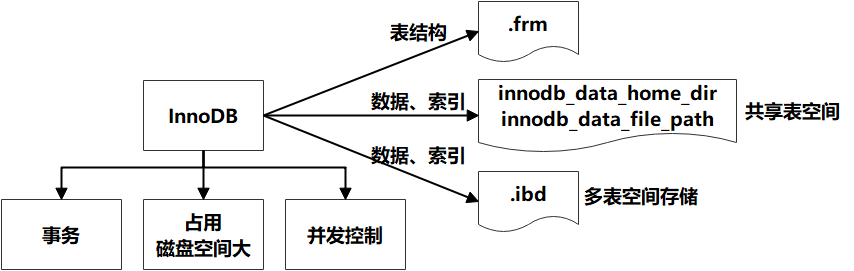
innoDB存盤引擎(5.5版本開始默認) : 支持事務 ,占用磁盤空間大 ,支持并發控制,表結構保存在.frm檔案中,如果是共享表空間,資料和索引保存在 innodb_data_home_dir 和 innodb_data_file_path定義的表空間中,可以是多個檔案,如果是多表空間存盤,每個表的資料和索引單獨保存在 .ibd 中,
[root@linux-141 itcast]# ll
-rw-r-----. 1 mysql mysql 8630 9月 10 16:02 t_account_innodb.frm
-rw-r-----. 1 mysql mysql 98304 9月 14 15:50 t_account_innodb.ibd
[root@linux-141 itcast]#
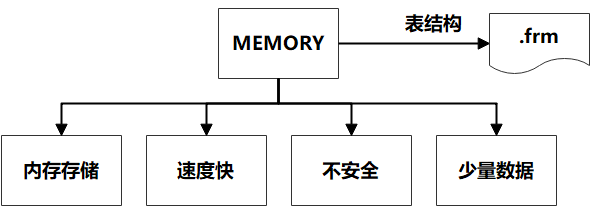
MEMORY存盤引擎 : 記憶體存盤 , 速度快 ,不安全 ,適合小量快速訪問的資料,表結構保存在.frm中,
特性對比 :
| 特點 | InnoDB | MyISAM | MEMORY | MERGE | NDB |
|---|---|---|---|---|---|
| 存盤限制 | 64TB | 有 | 有 | 沒有 | 有 |
| 事務安全 | 支持 | ||||
| 鎖機制 | 行鎖(適合高并發) | 表鎖 | 表鎖 | 表鎖 | 行鎖 |
| B樹索引 | 支持 | 支持 | 支持 | 支持 | 支持 |
| 哈希索引 | 支持 | ||||
| 全文索引 | 支持(5.6版本之后) | 支持 | |||
| 集群索引 | 支持 | ||||
| 資料索引 | 支持 | 支持 | 支持 | ||
| 索引快取 | 支持 | 支持 | 支持 | 支持 | 支持 |
| 資料可壓縮 | 支持 | ||||
| 空間使用 | 高 | 低 | N/A | 低 | 低 |
| 記憶體使用 | 高 | 低 | 中等 | 低 | 高 |
| 批量插入速度 | 低 | 高 | 高 | 高 | 高 |
| 支持外鍵 | 支持 |
1.2.3 如何選擇不同型別的引擎
在選擇存盤引擎時,應該根據應用系統的特點選擇合適的存盤引擎,對于復雜的應用系統,還可以根據實際情況選擇多種存盤引擎進行組合,
以下是幾種常用的存盤引擎的使用環境,
- InnoDB : 是Mysql的默認存盤引擎,用于事務處理應用程式,支持外鍵,如果應用對事務的完整性有比較高的要求,在并發條件下要求資料的一致性,資料操作除了插入和查詢以外,還包含更新、洗掉操作,那么InnoDB存盤引擎是比較合適的選擇,InnoDB存盤引擎除了有效的降低由于洗掉和更新導致的鎖定, 還可以確保事務的完整提交和回滾,對于類似于計費系統或者財務系統等對資料準確性要求比較高的系統,InnoDB是最合適的選擇,
- MyISAM : 如果應用是以讀操作和插入操作為主,只有很少的更新和洗掉操作,并且對事務的完整性、并發性要求不是很高,那么選擇這個存盤引擎是非常合適的,
- MEMORY:將所有資料保存在RAM中,在需要快速定位記錄和其他類似資料環境下,可以提供極快的訪問,MEMORY的缺陷就是對表的大小有限制,太大的表無法快取在記憶體中,其次是要確保表的資料可以恢復,資料庫例外終止后表中的資料是可以恢復的,MEMORY表通常用于更新不太頻繁的小表,用以快速得到訪問結果,
1.3 SQL的執行流程是什么樣的
- 客戶端發送一條查詢給服務器,
- 服務器先檢查查詢快取,如果命中了快取,則立刻回傳存盤在快取中的結果,否則進入下一階段,
- 服務器端進行SQL決議、預處理,再由優化器生成對應的執行計劃,
- MySQL根據優化器生成的執行計劃,再呼叫存盤引擎的API來執行查詢,
- 將結果回傳給客戶端,
2 MySQL存盤引擎調優
2.1 MySQL服務器硬體優化
tips
硬體(cpu、記憶體等)相關
了解即可
關于提升硬體設備性能:
例如選擇盡量高頻率的記憶體(頻率不能高于主板的支持)、提升網路帶寬、使用SSD高速磁盤、提升CPU性能等,
CPU的選擇:
- 對于資料庫并發比較高的場景,CPU的數量比頻率重要,
- 對于CPU密集型場景和頻繁執行復雜SQL的場景,CPU的頻率越高越好
磁盤的選擇
影響資料庫最大的性能問題就是磁盤I/O
為提高資料庫的IOPS性能,可使用SSD或PCIE-SSD高速磁盤設備
磁盤IO的優化
可以用RAID來進行優化
常用RAID(磁盤陣列)級別:
RAID0:也稱為條帶,就是把多個磁盤鏈接成一個硬碟使用,這個級別IO最好
RAID1:也稱為鏡像,要求至少有兩個磁盤,每組磁盤存盤的資料相同
RAID5:也是把多個(最少3個)硬碟合并成一個邏輯盤使用,資料讀寫時會建立奇偶校驗資訊,并且奇偶校驗資訊和相對應的資料分別存盤在不同的磁盤上,當RAID5的一個磁盤資料發生損壞后,利用剩下的資料和回應的奇偶校驗資訊去恢復被損壞的資料
RAID1+0(建議使用):就是RAID0和RAID1的組合,同時具備兩個級別的優缺點,一般建議資料庫使用這個級別,
2.2 MySQL資料庫配置優化
tips:
以下為生產環境中最常用的DB引數配置
-
表示緩沖池位元組大小,大的緩沖池可以減少磁盤IO次數,
innodb_buffer_pool_size = 推薦值為物理記憶體的50%~80%, -
用來控制redo log buffer重繪到磁盤的策略,
innodb_flush_log_at_trx_commit=1select @@innodb_flush_log_at_trx_commit;0 : 提交事務的時候,不立即把 redo log buffer 里的資料刷入磁盤檔案中,而是依靠 InnoDB 的主執行緒每秒執行一次重繪到磁盤,此時可能你提交事務了,結果 mysql 宕機了,然后此時記憶體里的資料全部丟失, 1 : 提交事務的時候,立即把 redo log buffer 里的資料刷入磁盤檔案中,只要事務提交成功,那么資料就必然在磁盤里了, 2 : 提交事務的時候,把 redo log buffer日志寫入磁盤檔案對應的系統快取,而不是直接進入磁盤檔案,這時可能1秒后才會把系統快取里的資料寫入到磁盤檔案, -
每提交1次事務就同步寫到磁盤中,可以設定為1,
sync_binlog=10:默認值,事務提交后,將二進制日志從緩沖寫入作業系統緩沖,但是不進行重繪操作(fsync()),此時只是寫入了作業系統緩沖而沒有重繪到磁盤,若作業系統宕機則會丟失部分二進制日志, 1:事務提交后,將二進制檔案寫入磁盤并立即執行重繪操作,相當于是同步寫入磁盤,不經過作業系統的快取, N:每寫N次作業系統緩沖就執行一次重繪操作, -
臟頁占innodb_buffer_pool_size的比例,觸發刷臟頁到磁盤, 推薦值為25%~50%,
innodb_max_dirty_pages_pct=30臟頁:記憶體資料頁和磁盤資料頁上的內容不一致 -
后臺行程最大IO性能指標,
默認200,如果SSD,調整為5000~20000PCIE-SSD可調整為5w左右
默認:innodb_io_capacity=200
-
指定innodb共享表空間檔案的大小,
innodb_data_file_path = ibdata:1G:autoextend:默認10M,一般設定為1GB
-
慢查詢日志的閾值設定,單位秒,
long_query_time=0.3合理設定區間0.1s~0.5s,
-
mysql復制的形式,row為MySQL8.0的默認形式,
binlog_format=row建議binlog的記錄格式為row模式
STATEMENT模式:每一潭訓修改資料的sql陳述句都會記錄到binlog中, ROW模式:不記錄每條sql陳述句的背景關系資訊,僅需記錄哪條資料被修改了,修改成什么樣了, MIXED模式:以上兩種模式的混合使用, -
降低interactive_timeout、wait_timeout的值,
互動等待時間和非互動等待時間,值一致,建議300~500s,默認8小時
在用mysql客戶端對資料庫進行操作時,打開終端視窗,如果一段時間(8小時)沒有操作,再次操作時,會報錯:當前的連接已經斷開,需要重新建立連接 -
資料庫最大連接數max_connections=200
-
過大,實體恢復時間長;過小,造成日志切換頻繁,
innodb_log_file_size=默認redo log空間大小
-
全量日志建議關閉,
默認關閉general_log=0開啟 general log 將所有到達MySQL Server的SQL陳述句記錄下來,general_Log檔案就會產生很大的檔案,建議關閉
2.3 Mysql中查詢快取優化
tips:
在MySQL 8.0之后廢棄這個功能
原理:復雜、實用性不高
作為了解即可
1) 查詢快取概述
開啟Mysql的查詢快取,當執行完全相同的SQL陳述句的時候,服務器就會直接從快取中讀取結果,當資料被修改,之前的快取會失效,修改比較頻繁的表不適合做查詢快取,
2) 操作流程
回顧
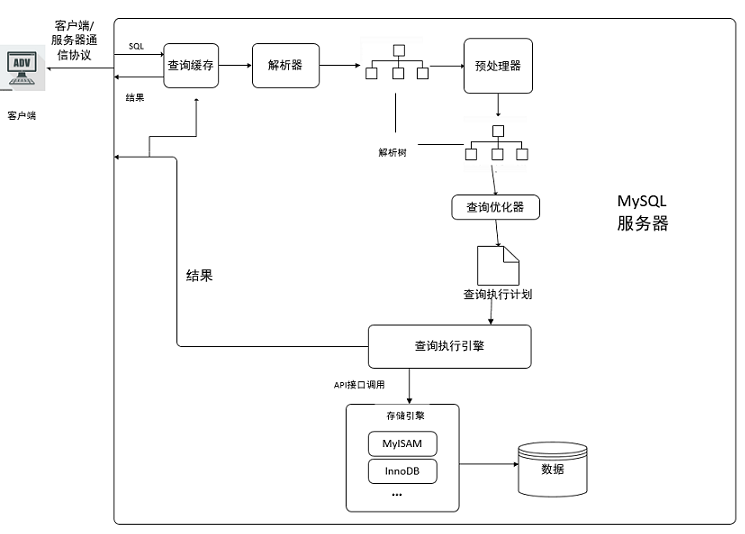
- 客戶端發送一條查詢給服務器;
- 服務器先會檢查查詢快取,如果命中了快取,則立即回傳存盤在快取中的結果,否則進入下一階段;
- 服務器端進行SQL決議、預處理,再由優化器生成對應的執行計劃;
- MySQL根據優化器生成的執行計劃,呼叫存盤引擎的API來執行查詢;
- 將結果回傳給客戶端,
3) 查詢快取配置
-
查看當前的MySQL資料庫是否支持查詢快取:
SHOW VARIABLES LIKE 'have_query_cache';

2. 查看當前MySQL是否開啟了查詢快取 :
SHOW VARIABLES LIKE 'query_cache_type';

3. 查看查詢快取的占用大小 :
SHOW VARIABLES LIKE 'query_cache_size';

4. 查看查詢快取的狀態變數:
SHOW STATUS LIKE 'Qcache%';
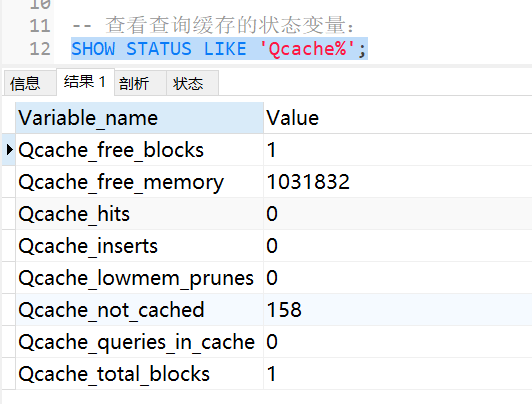
各個變數的含義如下:
| 引數 | 含義 |
|---|---|
| Qcache_free_blocks | 查詢快取中的可用記憶體塊數 |
| Qcache_free_memory | 查詢快取的可用記憶體量 |
| Qcache_hits | 查詢快取命中數 |
| Qcache_inserts | 添加到查詢快取的查詢數 |
| Qcache_lowmen_prunes | 由于記憶體不足而從查詢快取中洗掉的查詢數 |
| Qcache_not_cached | 非快取查詢的數量(由于 query_cache_type 設定而無法快取或未快取) |
| Qcache_queries_in_cache | 查詢快取中注冊的查詢數 |
| Qcache_total_blocks | 查詢快取中的塊總數 |
4) 開啟查詢快取
MySQL的查詢快取默認是關閉的,需要手動配置引數 query_cache_type , 來開啟查詢快取,query_cache_type 該引數的可取值有三個 :
| 值 | 含義 |
|---|---|
| OFF 或 0 | 查詢快取功能關閉 |
| ON 或 1 | 查詢快取功能打開,SELECT的結果符合快取條件即會快取,否則,不予快取,顯式指定 SQL_NO_CACHE,不予快取 |
| DEMAND 或 2 | 查詢快取功能按需進行,顯式指定 SQL_CACHE 的SELECT陳述句才會快取;其它均不予快取 |
在 my.cnf 配置中,增加以下配置 :
#開啟查詢快取
query_cache_type=1
配置完畢之后,重啟服務既可生效 ;
然后就可以在命令列執行SQL陳述句進行驗證 ,執行一條比較耗時的SQL陳述句,然后再多執行幾次,查看后面幾次的執行時間;獲取通過查看查詢快取的快取命中數,來判定是否走查詢快取,
-- 執行SQL陳述句進行驗證 查詢快取
SELECT * FROM product_list WHERE store_name = '聯想北達興科專賣店';
-- 將SELECT修改為小寫,發現快取失效
SELECT * FROM product_list WHERE store_name = '聯想北達興科專賣店';
5) 查詢快取SELECT選項
可以在SELECT陳述句中指定兩個與查詢快取相關的選項 :
SQL_CACHE : 如果查詢結果是可快取的,并且 query_cache_type 系統變數的值為ON或 DEMAND ,則快取查詢結果 ,
SQL_NO_CACHE : 服務器不使用查詢快取,它既不檢查查詢快取,也不檢查結果是否已快取,也不快取查詢結果,
例子:
SELECT SQL_CACHE id, name FROM xxx;
SELECT SQL_NO_CACHE id, name FROM xxx;
?
6) 查詢快取失效的情況
tips
需要注意的問題
1) SQL 陳述句不一致的情況, 要想命中查詢快取,查詢的SQL陳述句必須一致,
SQL1 : select count(*) from xxx;
SQL2 : Select count(*) from xxx;
2) 當查詢陳述句中有一些不確定的值,則不會快取,如 : now() , current_date() , curdate() , curtime() , rand() , uuid() , user() , database() ,
SQL1 : select * from xxx where updatetime < now() limit 1;
SQL2 : select user();
SQL3 : select database();
3) 不使用任何表查詢陳述句,
select 'A';
4) 查詢 mysql, information_schema或 performance_schema 資料庫中的表時,不會走查詢快取,
select * from information_schema.engines;
5) 在存盤的函式,觸發器或事件的主體內執行的查詢,
6) 如果表更改,則使用該表的所有高速快取查詢都將變為無效并從高速快取中洗掉,這包括使用MERGE映射到已更改表的表的查詢,一個表可以被許多型別的陳述句,如被改變 INSERT, UPDATE, DELETE, TRUNCATE TABLE, ALTER TABLE, DROP TABLE,或 DROP DATABASE ,
將查詢快取關閉,因為后面還需要進行索引的驗證,所以不希望走查詢快取
[root@linux-141 itcast]# vi /etc/my.cnf
[root@linux-141 itcast]# service mysql restart
Shutting down MySQL.... SUCCESS!
Starting MySQL. SUCCESS!
2.4. Mysql記憶體管理及優化
1)記憶體優化原則
1) 將盡量多的記憶體分配給MySQL做快取,但要給作業系統和其他程式預留足夠記憶體,
2) MyISAM 存盤引擎的資料檔案讀取依賴于作業系統自身的IO快取,因此,如果有MyISAM表,就要預留更多的記憶體給作業系統做IO快取,
3) 排序區、連接區等快取是分配給每個資料庫會話(session)專用的,其默認值的設定要根據最大連接數合理分配,如果設定太大,不但浪費資源,而且在并發連接較高時會導致物理記憶體耗盡,
2) MyISAM 記憶體優化
MyISAM 存盤引擎使用 key_buffer 快取索引塊,加速myisam索引的讀寫速度,對于myisam表的資料塊,mysql沒有特別的快取機制,完全依賴于作業系統的IO快取,
key_buffer_size
key_buffer_size決定MyISAM索引塊快取區的大小,直接影響到MyISAM表的存取效率,可以在MySQL引數檔案中設定key_buffer_size的值,對于一般MyISAM資料庫,建議至少將1/4可用記憶體分配給key_buffer_size,
在my.cnf 中做如下配置:
key_buffer_size=512M
read_buffer_size
如果需要經常順序掃描MyISAM 表,可以通過增大read_buffer_size的值來改善性能,但需要注意的是read_buffer_size是每個session獨占的,如果默認值設定太大,就會造成記憶體浪費,
read_rnd_buffer_size
對于需要做排序的MyISAM 表的查詢,如帶有order by子句的sql,適當增加 read_rnd_buffer_size 的值,可以改善此類的sql性能,
但需要注意的是 read_rnd_buffer_size 是每個session獨占的,如果默認值設定太大,就會造成記憶體浪費,
3) InnoDB 記憶體優化
innodb用一塊記憶體區做IO快取池,該快取池不僅用來快取innodb的索引塊,而且也用來快取innodb的資料塊,
innodb_buffer_pool_size
該變數決定了 innodb 存盤引擎表資料和索引資料的最大快取區大小,在保證作業系統及其他程式有足夠記憶體可用的情況下,innodb_buffer_pool_size 的值越大,快取命中率越高,訪問InnoDB表需要的磁盤I/O 就越少,性能也就越高,
innodb_buffer_pool_size=512M
innodb_log_buffer_size
決定了innodb重做日志快取的大小,對于可能產生大量更新記錄的大事務,增加innodb_log_buffer_size的大小,可以避免innodb在事務提交前就執行不必要的日志寫入磁盤操作,
innodb_log_buffer_size=10M
2.5. Mysql并發引數調整
從實作上來說,MySQL Server 是多執行緒結構,包括后臺執行緒和客戶服務執行緒,多執行緒可以有效利用服務器資源,提高資料庫的并發性能,在Mysql中,控制并發連接和執行緒的主要引數包括 max_connections、back_log、thread_cache_size、table_open_cahce,
1) max_connections
最大可支持的連接數
采用max_connections 控制允許連接到MySQL資料庫的最大數量,默認值是 151,如果狀態變數 connection_errors_max_connections 不為零,并且一直增長,則說明不斷有連接請求因資料庫連接數已達到允許最大值而失敗,這時可以考慮增大max_connections 的值,
Mysql 最大可支持的連接數,取決于很多因素,包括給定作業系統平臺的執行緒庫的質量、記憶體大小、每個連接的負荷、CPU的處理速度,期望的回應時間等,在Linux 平臺下,性能好的服務器,支持 500-1000 個連接不是難事,需要根據服務器性能進行評估設定,
2) back_log
積壓請求堆疊大小
back_log 引數控制MySQL監聽TCP埠時設定的積壓請求堆疊大小,如果MySql的連接數達到max_connections時,新來的請求將會被存在堆疊中,以等待某一連接釋放資源,該堆疊的數量即back_log,如果等待連接的數量超過back_log,將不被授予連接資源,將會報錯,5.6.6 版本之前默認值為 50 , 之后的版本默認為 50 + (max_connections / 5), 但最大不超過900,
如果需要資料庫在較短的時間內處理大量連接請求, 可以考慮適當增大back_log 的值,
3) table_open_cache
執行執行緒可打開表快取個數
該引數用來控制所有SQL陳述句執行執行緒可打開表快取的數量, 而在執行SQL陳述句時,每一個SQL執行執行緒至少要打開 1 個表快取,該引數的值應該根據設定的最大連接數 max_connections 以及每個連接執行關聯查詢中涉及的表的最大數量來設定 :
max_connections x N ;
4) thread_cache_size
快取客戶服務執行緒的數量
為了加快連接資料庫的速度,MySQL 會快取一定數量的客戶服務執行緒以備重用,通過引數 thread_cache_size 可控制 MySQL 快取客戶服務執行緒的數量,
5)lock_wait_timeout
innodb_lock_wait_timeout
事務等待行鎖的時間
該引數是用來設定InnoDB 事務等待行鎖的時間,默認值是50ms , 可以根據需要進行動態設定,對于需要快速反饋的業務系統來說,可以將行鎖的等待時間調小,以避免事務長時間掛起; 對于后臺運行的批量處理程式來說, 可以將行鎖的等待時間調大, 以避免發生大的回滾操作,
3 常用慢查詢分析工具
引言
在日常的業務開發中
MySQL 出現慢查詢是很常見的
大部分情況下會分為兩種情況
1、業務增長太快
2、要么就是SQL 寫的太xx了
所以
對慢查詢 SQL 進行分析和優化很重要
其中 mysqldumpslow 是 MySQL 服務自帶的一款很好的分析調優工具
3.1 調優工具mysqldumpslow
3.1.1 調優工具常用設定
1、什么是MySQL 慢查詢日志
MySQL提供的一種慢查詢日志記錄,用來記錄在MySQL查詢中回應時間超過閥值的記錄
具體指運行時間超過long_query_time值的SQL,則會被記錄到慢查詢日志中
2、如何查看慢查詢設定情況
慢查詢的時間閾值設定
show variables like '%slow_query_log%';

解釋
- slow_query_log //是否開啟,默認關閉,建議調優時才開啟
- slow_query_log_file //慢查詢日志存放路徑
3、如何開啟慢查詢日志記錄
1) 命令開啟
set global slow_query_log =1; //只對當前會話生效,重啟失效
執行成功
再次執行
show variables like '%slow_query_log%';
先關閉客戶端連接,再進行重新連接,即可看到設定生效
發現開啟了mysqldumpslow調優工具
mysql> show variables like '%slow_query_log%';
+---------------------+-------------------------------------------+
| Variable_name | Value |
+---------------------+-------------------------------------------+
| slow_query_log | ON |
| slow_query_log_file | /opt/mysql-5.7.28/data/linux-141-slow.log |
+---------------------+-------------------------------------------+
2 rows in set (0.02 sec)
mysql>
2)組態檔開啟
vim my.cnf
在[mysqld]下添加:
slow_query_log = 1
slow_query_log_file = /opt/mysql-5.7.28/data/linux-141-slow.log
重啟MySQL服務
修改并且重啟后
發現開啟了mysqldumpslow調優工具
mysql> show variables like '%slow_query_log%';
+---------------------+-------------------------------------------+
| Variable_name | Value |
+---------------------+-------------------------------------------+
| slow_query_log | ON |
| slow_query_log_file | /opt/mysql-5.7.28/data/linux-141-slow.log |
+---------------------+-------------------------------------------+
2 rows in set (0.02 sec)
mysql>
3)哪些 SQL 會記錄到慢查詢日志
-- 查看閥值(大于),默認10s
show variables like 'long_query_time%';

默認值是10秒
4)如何設定查詢閥值
- 命令設定
-- 設定慢查詢閥值
set global long_query_time = 1;
備注:另外開一個session或重新連接 ,才會看到變化
執行成功發發現慢sql的時間變成了1秒
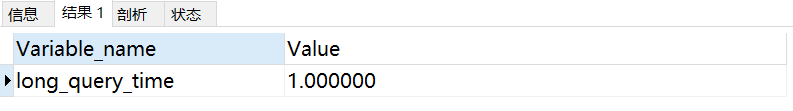
組態檔設定
vim my.cnf
[mysqld]
long_query_time = 1
log_output = FILE
重啟MySQL服務
執行成功發發現慢sql的時間變成了1秒
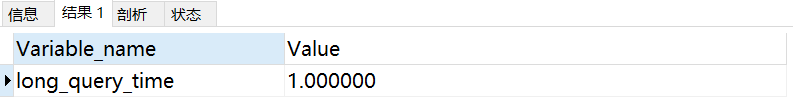
5)如何把未使用索引的 SQL 記錄寫入慢查詢日志
-- 查看設定,默認關閉
show variables like 'log_queries_not_using_indexes';
我們發現,未使用索引的sql默認是不記錄到慢查詢日志的

開啟配置
set global log_queries_not_using_indexes = on;
執行如下

6)模擬資料
-- 睡眠2s再執行
select sleep(2);
-- 查看慢查詢條數
show global status like '%Slow_queries%';
我們發現,每執行一次select sleep(2),之后,再通過show global status ...命令,他的值就會+1

3.1.2 調優工具常用命令
語法格式
mysqldumpslow [ OPTS... ] [ LOGS... ] //命令列格式
常用到的格式組合
-s 表示按照何種方式排序
c 訪問次數
l 鎖定時間
r 回傳記錄
t 查詢時間
al 平均鎖定時間
ar 平均回傳記錄數
at 平均查詢時間
-t 回傳前面多少條資料
-g 后邊搭配一個正則匹配模式,大小寫不敏感
1、拿到慢日志路徑
show variables like '%slow_query_log%';
日志路徑為:/opt/mysql-5.7.28/data/linux-141-slow.log
查看日志
[root@linux-141 mysql-5.7.28]# cat /opt/mysql-5.7.28/data/linux-141-slow.log
/opt/mysql-5.7.28/bin/mysqld, Version: 5.7.28-log (MySQL Community Server (GPL)). started with:
Tcp port: 3306 Unix socket: /tmp/mysql.sock
Time Id Command Argument
# Time: 2021-09-15T01:40:31.342430Z
# User@Host: root[root] @ [192.168.36.1] Id: 2
# Query_time: 2.000863 Lock_time: 0.000000 Rows_sent: 1 Rows_examined: 0
use itcast;
SET timestamp=1631670031;
-- 睡眠2s再執行
select sleep(2);
[root@linux-141 mysql-5.7.28]#
2、得到訪問次數最多的10條SQL
[root@linux-141 mysql-5.7.28]# ./bin/mysqldumpslow -s r -t 10 /opt/mysql-5.7.28/data/linux-141-slow.log
-bash: ./bin/mysqldumpslow: /usr/bin/perl: 壞的解釋器: 沒有那個檔案或目錄
[root@linux-141 mysql-5.7.28]# yum -y install perl perl-devel
[root@linux-141 mysql-5.7.28]# ./bin/mysqldumpslow -s r -t 10 /opt/mysql-5.7.28/data/linux-141-slow.log
3、按照時間排序的前10條里面含有左連接的SQL
[root@linux-141 mysql-5.7.28]# ./bin/mysqldumpslow -s t -t 10 -g "left join" /opt/mysql-5.7.28/data/linux-141-slow.log
Reading mysql slow query log from /opt/mysql-5.7.28/data/linux-141-slow.log
Died at ./bin/mysqldumpslow line 167, <> chunk 28.
[root@linux-141 mysql-5.7.28]#
3.1.3 慢日志檔案分析
1、查看慢查詢日志
[root@linux-141 mysql-5.7.28]# cat /opt/mysql-5.7.28/data/linux-141-slow.log
/opt/mysql-5.7.28/bin/mysqld, Version: 5.7.28-log (MySQL Community Server (GPL)). started with:
Tcp port: 3306 Unix socket: /tmp/mysql.sock
Time Id Command Argument
# Time: 2021-09-15T01:40:31.342430Z
# User@Host: root[root] @ [192.168.36.1] Id: 2
# Query_time: 2.000863 Lock_time: 0.000000 Rows_sent: 1 Rows_examined: 0
use itcast;
SET timestamp=1631670031;
-- 睡眠2s再執行
select sleep(2);
# Time: 2021-09-15T01:50:32.130305Z
# User@Host: root[root] @ [192.168.36.1] Id: 2
# Query_time: 3.001904 Lock_time: 0.000000 Rows_sent: 1 Rows_examined: 0
SET timestamp=1631670632;
select sleep(3);
# Time: 2021-09-15T01:50:55.064372Z
# User@Host: root[root] @ [192.168.36.1] Id: 2
# Query_time: 4.008082 Lock_time: 0.000000 Rows_sent: 1 Rows_examined: 0
SET timestamp=1631670655;
select sleep(4);
# Time: 2021-09-15T01:51:01.343463Z
# User@Host: root[root] @ [192.168.36.1] Id: 2
# Query_time: 5.007035 Lock_time: 0.000000 Rows_sent: 1 Rows_examined: 0
SET timestamp=1631670661;
select sleep(5);
# Time: 2021-09-15T01:51:07.737834Z ###### 執行SQL時間
# User@Host: root[root] @ [192.168.36.1] Id: 2 ###### 執行SQL的主機資訊
# Query_time: 6.009129 Lock_time: 0.000000 Rows_sent: 1 Rows_examined: 0 ###### SQL的執行資訊
SET timestamp=1631670667; ###### SQL執行時間
select sleep(6); ###### SQL內容
[root@linux-141 mysql-5.7.28]#
屬性解釋
# Time: 2021-09-15T01:51:07.737834Z ###### 執行SQL時間
# User@Host: root[root] @ [192.168.36.1] Id: 2 ###### 執行SQL的主機資訊
# Query_time: 6.009129 Lock_time: 0.000000 Rows_sent: 1 Rows_examined: 0 ###### SQL的執行資訊
SET timestamp=1631670667; ###### SQL執行時間
select sleep(6); ###### SQL內容
3.2 調優工具show profile
tips:
show profile,它也是調優工具
也是MySQL服務自帶的分析調優工具
不過這款更高級
比較接近底層硬體引數的調優,
簡介:
show profile是MySQL服務自帶更高級的分析調優工具
比較接近底層硬體引數的調優
1、查看show profile設定
-- 默認關閉,保存近15次的運行結果
show variables like 'profiling%';

通過上面我們發現,show profile工具默認是關閉狀態,15表示保存了近15次的運行結果,
2、開啟調優工具
執行下面的命令開啟
SET profiling = ON;
再次查看狀態
show variables like 'profiling%';

3、查看最近15次的運行結果
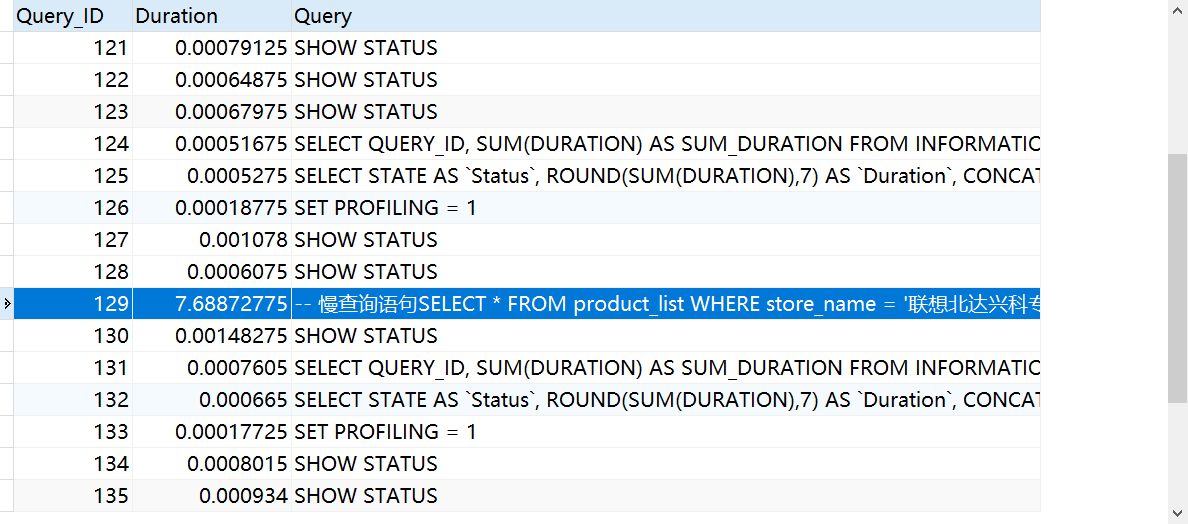
-- 查看最近15次的運行結果
show profiles;
-- 可以顯示警告和報錯的資訊
show warnings;
-- 慢查詢陳述句
SELECT * FROM product_list WHERE store_name = '聯想北達興科專賣店';
顯示最近15次的運行結果
4、診斷運行的SQL
接下來,我們一起診斷一下query id為23的慢查詢
-- 語法
SHOW PROFILE cpu,block io FOR QUERY query id;
-- 示例
SHOW PROFILE cpu,block io FOR QUERY 129;
開始執行
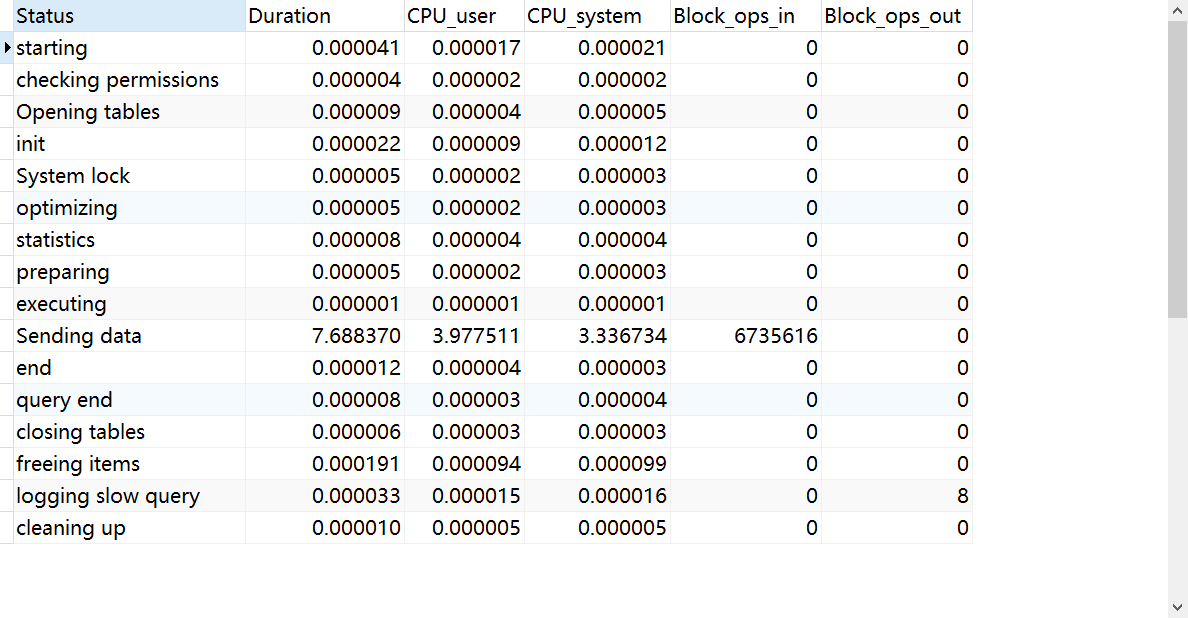
解釋:
通過Status一列,可以看到整條SQL的運行程序
1. starting //開始
2. checking permissions //檢查權限
3. Opening tables //打開資料表
4. init //初始化
5. System lock //鎖機制
6. optimizing //優化器
7. statistics //分析語法樹
8. prepareing //預準備
9. executing //引擎執行開始
10. end //引擎執行結束
11. query end //查詢結束
12. closing tables //釋放資料表
13. freeing items //釋放記憶體
14. cleaning up //徹底清理
查看型別選項
SHOW PROFILE...后面的列,即:SHOW PROFILE ALL, BLOCK IO, ... FOR QUERY 209;
ALL //顯示索引的開銷資訊
BLOCK IO //顯示塊IO相關開銷
CONTEXT SWITCHES //背景關系切換相關開銷
CPU //顯示CPU相關開銷資訊
IPC //顯示發送和接收相關開銷資訊
MEMORY //顯示記憶體相關開銷資訊
PAGE FAULTS //顯示頁面錯誤相關開銷資訊
SOURCE //顯示和source_function,source_file,source_line相關的開銷資訊
SWAPS //顯示交換次數相關開銷的資訊
重要提示
如出現以下一種或者幾種情況,說明SQL執行性能極其低下,亟需優化 * converting HEAP to MyISAM //查詢結果太大,記憶體都不夠用了往磁盤上搬了 * Creating tmp table //創建臨時表:拷貝資料到臨時表,用完再刪 * Copying to tmp table on disk //把記憶體中臨時表復制到磁盤,危險 * locked //出現死鎖
4 如何定位不合理的SQL
引言
在應用的開發程序中,由于初期資料量小,開發人員寫 SQL 陳述句時更重視功能上的實作,但是當應用系統正式上線后,隨著生產資料量的急劇增長,很多SQL陳述句開始逐漸顯露出性能問題,對生產的影響也越來越大,此時這些有問題的SQL陳述句就成為整個系統性能的瓶頸,因此我們必須要對它們進行優化,本章將詳細介紹在MySQL中優化SQL陳述句的方法,
當面對一個有SQL性能問題的資料庫時,我們應該從何處入手來進行系統的分析,使得能夠盡快定位問題SQL并盡快解決問題,
4.1 如何查看SQL執行頻率
MySQL 客戶端連接成功后,通過
-- 服務器狀態資訊
show [session|global] status;
命令可以提供服務器狀態資訊,show [session|global] status 可以根據需要加上引數“session”或者“global”來顯示 session 級(當前連接)的統計結果和 global 級(自資料庫上次啟動至今)的統計結果,
如果不寫,默認使用引數是“session”,
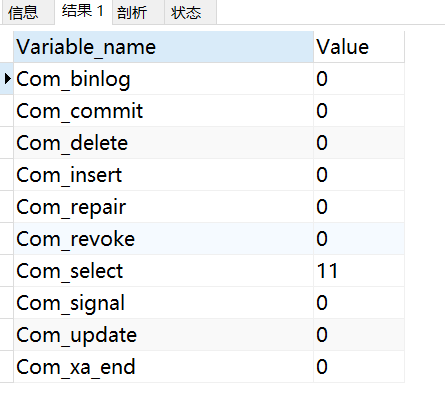
下面的命令顯示了當前 session 中所有統計引數的值:
show status like 'Com_______';
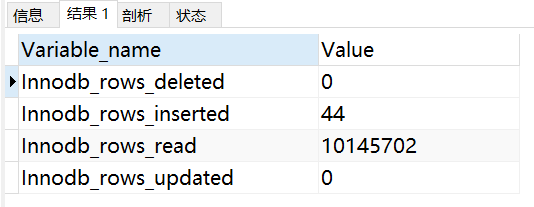
show status like 'Innodb_rows_%';
Com_xxx 表示每個 xxx 陳述句執行的次數,我們通常比較關心的是以下幾個統計引數,
| 引數 | 含義 |
|---|---|
| Com_select | 執行 select 操作的次數,一次查詢只累加 1, |
| Com_insert | 執行 INSERT 操作的次數,對于批量插入的 INSERT 操作,只累加一次, |
| Com_update | 執行 UPDATE 操作的次數, |
| Com_delete | 執行 DELETE 操作的次數, |
| Innodb_rows_read | select 查詢回傳的行數, |
| Innodb_rows_inserted | 執行 INSERT 操作插入的行數, |
| Innodb_rows_updated | 執行 UPDATE 操作更新的行數, |
| Innodb_rows_deleted | 執行 DELETE 操作洗掉的行數, |
| Connections | 試圖連接 MySQL 服務器的次數, |
| Uptime | 服務器作業時間, |
| Slow_queries | 慢查詢的次數, |
Com_*** : 這些引數對于所有存盤引擎的表操作都會進行累計,
Innodb_*** : 這幾個引數只是針對InnoDB 存盤引擎的,累加的演算法也略有不同,
4.2 如何定位低效率SQL
以下兩種方式:
-
慢查詢日志(重要) : 通過慢查詢日志定位那些執行效率較低的 SQL 陳述句,用--log-slow-queries[=file_name]選項啟動時,mysqld 寫一個包含所有執行時間超過 long_query_time 秒的 SQL 陳述句的日志檔案,
tips:
關于慢查詢SQL如何獲取
參看上個章節
-
show processlist (重要) :
慢查詢日志在查詢結束以后才記錄,所以在應用反映執行效率出現問題的時候查詢慢查詢日志并不能定位問題,
可以使用show processlist命令查看當前MySQL在進行的執行緒,包括執行緒的狀態、是否鎖表等,可以實時地查看 SQL 的執行情況,同時對一些鎖表操作進行優化,

屬性欄位解釋
1) id列,用戶登錄mysql時,系統分配的"connection_id",可以使用函式connection_id()查看
2) user列,顯示當前用戶,如果不是root,這個命令就只顯示用戶權限范圍的sql陳述句
3) host列,顯示這個陳述句是從哪個ip的哪個埠上發的,可以用來跟蹤出現問題陳述句的用戶
4) db列,顯示這個行程目前連接的是哪個資料庫
5) command列,顯示當前連接的執行的命令,一般取值為休眠(sleep),查詢(query),連接(connect)等
6) time列,顯示這個狀態持續的時間,單位是秒
7) state列,顯示使用當前連接的sql陳述句的狀態,很重要的列,
state描述的是陳述句執行中的某一個狀態,一個sql陳述句,以查詢為例,可能需要經過copying to tmp table、sorting result、sending data等狀態才可以完成
8) info列,顯示這個sql陳述句,是判斷問題陳述句的一個重要依據
4.3 使用explain分析執行計劃
-- explain 分析執行計劃
explain SELECT * FROM product_list WHERE store_name = '聯想北達興科專賣店';

| 欄位 | 含義 |
|---|---|
| id | select查詢的序列號,是一組數字,表示的是查詢中執行select子句或者是操作表的順序, |
| select_type | 表示 SELECT 的型別,常見的取值有 SIMPLE(簡單表,即不使用表連接或者子查詢)、PRIMARY(主查詢,即外層的查詢)、UNION(UNION 中的第二個或者后面的查詢陳述句)、SUBQUERY(子查詢中的第一個 SELECT)等 |
| table | 輸出結果集的表 |
| partitions | 匹配的磁區 |
| type | 表示表的連接型別,性能由好到差的連接型別為( system ---> const -----> eq_ref ------> ref -------> ref_or_null----> index_merge ---> index_subquery -----> range -----> index ------> all ) |
| possible_keys | 表示查詢時,可能使用的索引 |
| key | 表示實際使用的索引 |
| key_len | 索引欄位的長度 |
| rows | 掃描行的數量 |
| filtered | 按表條件過濾的行百分比 |
| extra | 執行情況的說明和描述 |
4.3.1 環境準備
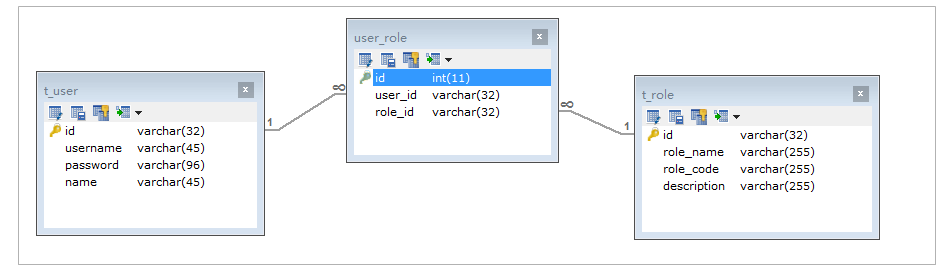
CREATE TABLE `t_role` (
`id` varchar(32) NOT NULL,
`role_name` varchar(255) DEFAULT NULL,
`role_code` varchar(255) DEFAULT NULL,
`description` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `unique_role_name` (`role_name`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
CREATE TABLE `t_user` (
`id` varchar(32) NOT NULL,
`username` varchar(45) NOT NULL,
`password` varchar(96) NOT NULL,
`name` varchar(45) NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
CREATE TABLE `user_role` (
`id` int(11) NOT NULL auto_increment ,
`user_id` varchar(32) DEFAULT NULL,
`role_id` varchar(32) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `idx_role_user` (`role_id`,`user_id`),
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
insert into `t_user` (`id`, `username`, `password`, `name`) values('1','super','$2a$10$TJ4TmCdK.X4wv/tCqHW14.w70U3CC33CeVncD3SLmyMXMknstqKRe','超級管理員');
insert into `t_user` (`id`, `username`, `password`, `name`) values('2','admin','$2a$10$TJ4TmCdK.X4wv/tCqHW14.w70U3CC33CeVncD3SLmyMXMknstqKRe','系統管理員');
insert into `t_user` (`id`, `username`, `password`, `name`) values('3','itcast','$2a$10$8qmaHgUFUAmPR5pOuWhYWOr291WJYjHelUlYn07k5ELF8ZCrW0Cui','test02');
insert into `t_user` (`id`, `username`, `password`, `name`) values('4','stu1','$2a$10$pLtt2KDAFpwTWLjNsmTEi.oU1yOZyIn9XkziK/y/spH5rftCpUMZa','學生1');
insert into `t_user` (`id`, `username`, `password`, `name`) values('5','stu2','$2a$10$nxPKkYSez7uz2YQYUnwhR.z57km3yqKn3Hr/p1FR6ZKgc18u.Tvqm','學生2');
insert into `t_user` (`id`, `username`, `password`, `name`) values('6','t1','$2a$10$TJ4TmCdK.X4wv/tCqHW14.w70U3CC33CeVncD3SLmyMXMknstqKRe','老師1');
INSERT INTO `t_role` (`id`, `role_name`, `role_code`, `description`) VALUES('5','學生','student','學生');
INSERT INTO `t_role` (`id`, `role_name`, `role_code`, `description`) VALUES('7','老師','teacher','老師');
INSERT INTO `t_role` (`id`, `role_name`, `role_code`, `description`) VALUES('8','教學管理員','teachmanager','教學管理員');
INSERT INTO `t_role` (`id`, `role_name`, `role_code`, `description`) VALUES('9','管理員','admin','管理員');
INSERT INTO `t_role` (`id`, `role_name`, `role_code`, `description`) VALUES('10','超級管理員','super','超級管理員');
INSERT INTO user_role(id,user_id,role_id) VALUES(NULL, '1', '5'),(NULL, '1', '7'),(NULL, '2', '8'),(NULL, '3', '9'),(NULL, '4', '8'),(NULL, '5', '10') ;
4.3.2 explain 之 id
id 欄位是 select查詢的序列號,是一組數字,表示的是查詢中執行select子句或者是操作表的順序,
id 情況有三種 :
1) id 相同表示加載表的順序是從上到下,
explain select * from t_role r, t_user u, user_role ur where r.id = ur.role_id and u.id = ur.user_id ;

2) id 不同id值越大,優先級越高,越先被執行,
EXPLAIN SELECT * FROM t_role WHERE id = (SELECT role_id FROM user_role WHERE user_id = (SELECT id FROM t_user WHERE username = 'stu1'))

3) id 有相同,也有不同,同時存在,id相同的可以認為是一組,從上往下順序執行;在所有的組中,id的值越大,優先級越高,越先執行,
EXPLAIN SELECT * FROM t_role r , (SELECT * FROM user_role ur WHERE ur.`user_id` = '2') a WHERE r.id = (select role.id from t_user, user_role role where role.id = 10) ;

4.3.3 explain 之 select_type
表示 SELECT 的型別,常見的取值,如下表所示:
EXPLAIN SELECT * FROM t_role WHERE id = (SELECT role_id FROM user_role WHERE user_id = (SELECT id FROM t_user WHERE username = 'stu1'));

| select_type | 含義 |
|---|---|
| SIMPLE | 簡單的select查詢,查詢中不包含子查詢或者UNION |
| PRIMARY | 查詢中若包含任何復雜的子查詢,最外層查詢標記為該標識 |
| SUBQUERY | 在SELECT 或 WHERE 串列中包含了子查詢 |
| DERIVED | 在FROM 串列中包含的子查詢,被標記為 DERIVED(衍生) MYSQL會遞回執行這些子查詢,把結果放在臨時表中 |
| UNION | 若第二個SELECT出現在UNION之后,則標記為UNION ; 若UNION包含在FROM子句的子查詢中,外層SELECT將被標記為 : DERIVED |
| UNION RESULT | 從UNION表獲取結果的SELECT |
4.3.4 explain 之 table
展示這一行的資料是關于哪一張表的
EXPLAIN SELECT * FROM t_role WHERE id = (SELECT role_id FROM user_role WHERE user_id = (SELECT id FROM t_user WHERE username = 'stu1'));

4.3.5 explain 之 type
EXPLAIN SELECT * FROM t_role WHERE id = (SELECT role_id FROM user_role WHERE user_id = (SELECT id FROM t_user WHERE username = 'stu1'));

type 顯示的是訪問型別,是較為重要的一個指標,可取值為:
| type | 含義 |
|---|---|
| NULL | MySQL不訪問任何表,索引,直接回傳結果 |
| system | 表只有一行記錄(等于系統表),這是const型別的特例,一般不會出現 |
| const | 表示通過索引一次就找到了,const 用于比較primary key 或者 unique 索引,因為只匹配一行資料,所以很快,如將主鍵置于where串列中,MySQL 就能將該查詢轉換為一個常量,const會將 "主鍵" 或 "唯一" 索引的所有部分與常量值進行比較 |
| eq_ref | 類似ref,區別在于使用的是唯一索引,使用主鍵的關聯查詢,關聯查詢出的記錄只有一條,常見于主鍵或唯一索引掃描 |
| ref | 非唯一性索引掃描,回傳匹配某個單獨值的所有行,本質上也是一種索引訪問,回傳所有匹配某個單獨值的所有行(多個) |
| range | 只檢索給定回傳的行,使用一個索引來選擇行, where 之后出現 between , < , > , in 等操作, |
| index | index 與 ALL的區別為 index 型別只是遍歷了索引樹, 通常比ALL 快, ALL 是遍歷資料檔案, |
| all | 將遍歷全表以找到匹配的行 |
結果值從最好到最壞依次是:
NULL > system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL
system > const > eq_ref > ref > range > index > ALL
一般來說, 我們需要保證查詢至少達到 range 級別, 最好達到ref ,
4.3.6 explain 之 key
possible_keys : 顯示可能應用在這張表的索引, 一個或多個,
key : 實際使用的索引, 如果為NULL, 則沒有使用索引,
key_len : 表示索引中使用的位元組數,len=3*n+2(n為索引欄位的長度)
EXPLAIN select * from t_role where role_name = '超級管理員';
select 255 * 3 + 2; -- role_name VARCHAR(255)

4.3.7 explain 之 rows
掃描行的數量,
4.3.8 explain 之 extra
其他的額外的執行計劃資訊,在該列展示 ,
EXPLAIN select u.username from t_user u order by u.username desc;

| extra | 含義 |
|---|---|
| using filesort | 說明mysql會對資料使用一個外部的索引排序,而不是按照表內的索引順序進行讀取, 稱為 “檔案排序”, 效率低, |
| using temporary | 使用了臨時表保存中間結果,MySQL在對查詢結果排序時使用臨時表,常見于 order by 和 group by; 效率低 |
| using index | 表示相應的select操作使用了覆寫索引, 避免訪問表的資料行, 效率不錯, |
5 如何合理使用索引加速
tips:
500萬條建表sql參照網盤sql腳本
[root@linux-141 bin]# ./mysql -u root -p itcast < product_list-5072825.sql
索引是資料庫優化最常用也是最重要的手段之一, 通過索引通常可以幫助用戶解決大多數的MySQL的性能優化問題,
5.1 驗證索引提升查詢效率
在我們準備的表結構product_list 中, 一共存盤了 500多萬記錄;
mysql> select count(1) from product_list;
+----------+
| count(1) |
+----------+
| 5072825 |
+----------+
1 row in set (1.71 sec)
mysql>
1) 根據ID查詢
SELECT * FROM product_list WHERE id = 121926;

查詢速度很快, 接近0s , 主要的原因是因為id為主鍵, 有索引;
2). 根據store_name進行精確查詢
執行用時4分鐘
SELECT * FROM product_list WHERE store_name = '聯想北達興科專賣店';
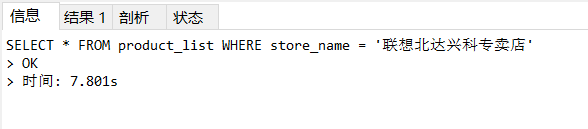
查看SQL陳述句的執行計劃 :
explain SELECT * FROM product_list WHERE store_name = '聯想北達興科專賣店';

處理方案 , 針對store_name欄位, 創建索引 :
create index product_list_stname on product_list(store_name);
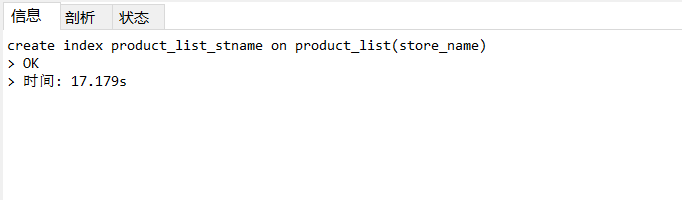
索引創建完成之后,再次進行查詢 :
SELECT * FROM product_list WHERE store_name = '聯想北達興科專賣店';
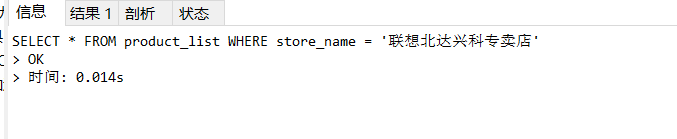
通過explain , 查看執行計劃,執行SQL時使用了剛才創建的索引
-- 查看SQL陳述句的執行計劃
explain SELECT * FROM product_list WHERE store_name = '聯想北達興科專賣店';

5.2 索引的使用
5.2.1 準備環境
create table `tb_seller` (
`sellerid` varchar (100),
`name` varchar (100) not null,
`nickname` varchar (50),
`password` varchar (60),
`status` varchar (1) not null,
`address` varchar (100) not null,
`createtime` datetime,
primary key(`sellerid`)
)engine=innodb default charset=utf8;
insert into `tb_seller` (`sellerid`, `name`, `nickname`, `password`, `status`, `address`, `createtime`) values('alibaba','阿里巴巴','阿里小店','e10adc3949ba59abbe56e057f20f883e','1','北京市','2088-01-01 12:00:00');
insert into `tb_seller` (`sellerid`, `name`, `nickname`, `password`, `status`, `address`, `createtime`) values('baidu','百度科技有限公司','百度小店','e10adc3949ba59abbe56e057f20f883e','1','北京市','2088-01-01 12:00:00');
insert into `tb_seller` (`sellerid`, `name`, `nickname`, `password`, `status`, `address`, `createtime`) values('huawei','華為科技有限公司','華為小店','e10adc3949ba59abbe56e057f20f883e','0','北京市','2088-01-01 12:00:00');
insert into `tb_seller` (`sellerid`, `name`, `nickname`, `password`, `status`, `address`, `createtime`) values('itcast','傳智播客教育科技有限公司','傳智播客','e10adc3949ba59abbe56e057f20f883e','1','北京市','2088-01-01 12:00:00');
insert into `tb_seller` (`sellerid`, `name`, `nickname`, `password`, `status`, `address`, `createtime`) values('itheima','黑馬程式員','黑馬程式員','e10adc3949ba59abbe56e057f20f883e','0','北京市','2088-01-01 12:00:00');
insert into `tb_seller` (`sellerid`, `name`, `nickname`, `password`, `status`, `address`, `createtime`) values('luoji','羅技科技有限公司','羅技小店','e10adc3949ba59abbe56e057f20f883e','1','北京市','2088-01-01 12:00:00');
insert into `tb_seller` (`sellerid`, `name`, `nickname`, `password`, `status`, `address`, `createtime`) values('oppo','OPPO科技有限公司','OPPO官方旗艦店','e10adc3949ba59abbe56e057f20f883e','0','北京市','2088-01-01 12:00:00');
insert into `tb_seller` (`sellerid`, `name`, `nickname`, `password`, `status`, `address`, `createtime`) values('ourpalm','掌趣科技股份有限公司','掌趣小店','e10adc3949ba59abbe56e057f20f883e','1','北京市','2088-01-01 12:00:00');
insert into `tb_seller` (`sellerid`, `name`, `nickname`, `password`, `status`, `address`, `createtime`) values('qiandu','千度科技','千度小店','e10adc3949ba59abbe56e057f20f883e','2','北京市','2088-01-01 12:00:00');
insert into `tb_seller` (`sellerid`, `name`, `nickname`, `password`, `status`, `address`, `createtime`) values('sina','新浪科技有限公司','新浪官方旗艦店','e10adc3949ba59abbe56e057f20f883e','1','北京市','2088-01-01 12:00:00');
insert into `tb_seller` (`sellerid`, `name`, `nickname`, `password`, `status`, `address`, `createtime`) values('xiaomi','小米科技','小米官方旗艦店','e10adc3949ba59abbe56e057f20f883e','1','西安市','2088-01-01 12:00:00');
insert into `tb_seller` (`sellerid`, `name`, `nickname`, `password`, `status`, `address`, `createtime`) values('yijia','宜家家居','宜家家居旗艦店','e10adc3949ba59abbe56e057f20f883e','1','北京市','2088-01-01 12:00:00');
create index idx_seller_name_sta_addr on tb_seller(name,status,address);
5.2.2 避免索引失效
組合索引(name,status,address)
1) 全值匹配
對索引中所有列都指定具體值,
-- 全值匹配
explain select * from tb_seller where name='小米科技' and status='1' and address='北京市';
ken_len = 3 * N + 2;
-- name varchar(100) ==302
-- status varchar(1) ==5
-- address varchar(100) ==302

2) 最左前綴法則
如果索引了多列,要遵守最左前綴法則,指的是查詢從索引的最左前列開始,并且不跳過索引中的列,
匹配最左前綴法則,走索引:
explain select * from tb_seller where name='小米科技';

違反最左前綴法則 , 索引失效:
explain select * from tb_seller where status='1';
explain select * from tb_seller where status='1' and address='北京市';

如果符合最左法則,但是出現跳躍某一列,只有最左列索引生效:
explain select * from tb_seller where name='小米科技' and address='北京市';

3) 范圍查詢右邊的列
-- 使用范圍查詢的情況,右邊的列失效
explain select * from tb_seller where name='小米科技' and status='1' and address='北京市';
explain select * from tb_seller where name='小米科技' and status>'1' and address='北京市';

根據前面的兩個欄位name , status 查詢是走索引的, 但是最后一個條件address 沒有用到索引,
4) 禁止列運算
-- 不要在索引列上進行運算操作, 索引將失效,
explain select * from tb_seller where substring(name,3,2) ='科技';

5) 字串不加單引號
造成索引失效,
-- 字串不加單引號,造成索引失效,
explain select * from tb_seller where name='科技' and status='0';
explain select * from tb_seller where name='科技' and status=0;

由于,在查詢時,沒有對字串加單引號,MySQL的查詢優化器,會自動的進行型別轉換,造成索引失效,
本文由
傳智教育博學谷教研團隊發布,如果本文對您有幫助,歡迎
關注和點贊;如果您有任何建議也可留言評論或私信,您的支持是我堅持創作的動力,轉載請注明出處!
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/534097.html
標籤:Java
下一篇:方法和傳遞