前言
今天給大家介紹的是Python爬蟲批量下載相親網站圖片資料,在這里給需要的小伙伴們代碼,并且給出一點小心得,
首先是爬取之前應該盡可能偽裝成瀏覽器而不被識別出來是爬蟲,基本的是加請求頭,但是這樣的純文本資料爬取的人會很多,所以我們需要考慮更換代理IP和隨機更換請求頭的方式來對相親網站圖片資料進行爬取,
在每次進行爬蟲代碼的撰寫之前,我們的第一步也是最重要的一步就是分析我們的網頁,
通過分析我們發現在爬取程序中速度比較慢,所以我們還可以通過禁用谷歌瀏覽器圖片、JavaScript等方式提升爬蟲爬取速度,
開發工具
Python版本: 3.6
相關模塊:
requests模塊
parsel模塊
re模塊
環境搭建
安裝Python并添加到環境變數,pip安裝需要的相關模塊即可,
文中完整代碼及檔案,評論留言獲取
資料來源查詢分析
瀏覽器中打開我們要爬取的頁面
按F12進入開發者工具,查看我們想要的相親網站圖片資料在哪里
這里我們需要頁面資料就可以了

代碼實作
for page in range(1, 11):
# 請求鏈接
url = f'https://love.19lou.com/valueApp/api/love/searchLoveUser?page={page}&perPage=12&sex=0'
# 偽裝模擬
headers = {
# User-Agent 用戶代理, 表示瀏覽器基本資訊
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.0.0 Safari/537.36'
'Cookie':'你的Cookie'
}
# 發送請求
response = requests.get(url=url, headers=headers)
print(response)
#for回圈遍歷, 把串列里面元素一個一個提取出來
for index in response.json()['data']['items']:
# https://love.19lou.com/detail/51593564 format 字串格式化方法
link = f'https://love.19lou.com/detail/{index["uid"]}'
html_data = https://www.cnblogs.com/guzichuan/p/requests.get(url=link, headers=headers).text
# 把獲取下來 html字串資料, 轉成可決議物件
selector = parsel.Selector(html_data)
name = selector.css('.username::text').get()
info_list = selector.css('.info-tag::text').getall()
# . 表示呼叫方法屬性
gender = info_list[0].split(':')[-1]
age = info_list[1].split(':')[-1]
height = info_list[2].split(':')[-1]
date = info_list[-1].split(':')[-1]
# 判斷info_list元素個數 當元素個數4個 說明沒有體重一欄
if len(info_list) == 4:
weight = '0kg'
else:
weight = info_list[3].split(':')[-1]
info_list_1 = selector.css('.basic-item span::text').getall()[2:]
zodiac = info_list_1[0].split(':')[-1]
constellation = info_list_1[1].split(':')[-1]
nativePlace = info_list_1[2].split(':')[-1]
location = info_list_1[3].split(':')[-1]
edu = info_list_1[4].split(':')[-1]
maritalStatus = info_list_1[5].split(':')[-1]
job = info_list_1[6].split(':')[-1]
money = info_list_1[7].split(':')[-1]
house = info_list_1[8].split(':')[-1]
car = info_list_1[9].split(':')[-1]
img_url = selector.css('.page .left-detail .abstract .avatar img::attr(src)').get()
# 把獲取下來的資料 保存字典里面 字典資料容器
dit = {
'昵稱': name,
'性別': gender,
'年齡': age,
'身高': height,
'體重': weight,
'出生日期': date,
'生肖': zodiac,
'星座': constellation,
'籍貫': nativePlace,
'所在地': location,
'學歷': edu,
'婚姻狀況': maritalStatus,
'職業': job,
'年收入': money,
'住房': house,
'車輛': car,
'照片': img_url,
'詳情頁': link,
}
csv_writer.writerow(dit)
new_name = re.sub(r'[\/"*?<>|]', '', name)
獲取Cookie

效果展示
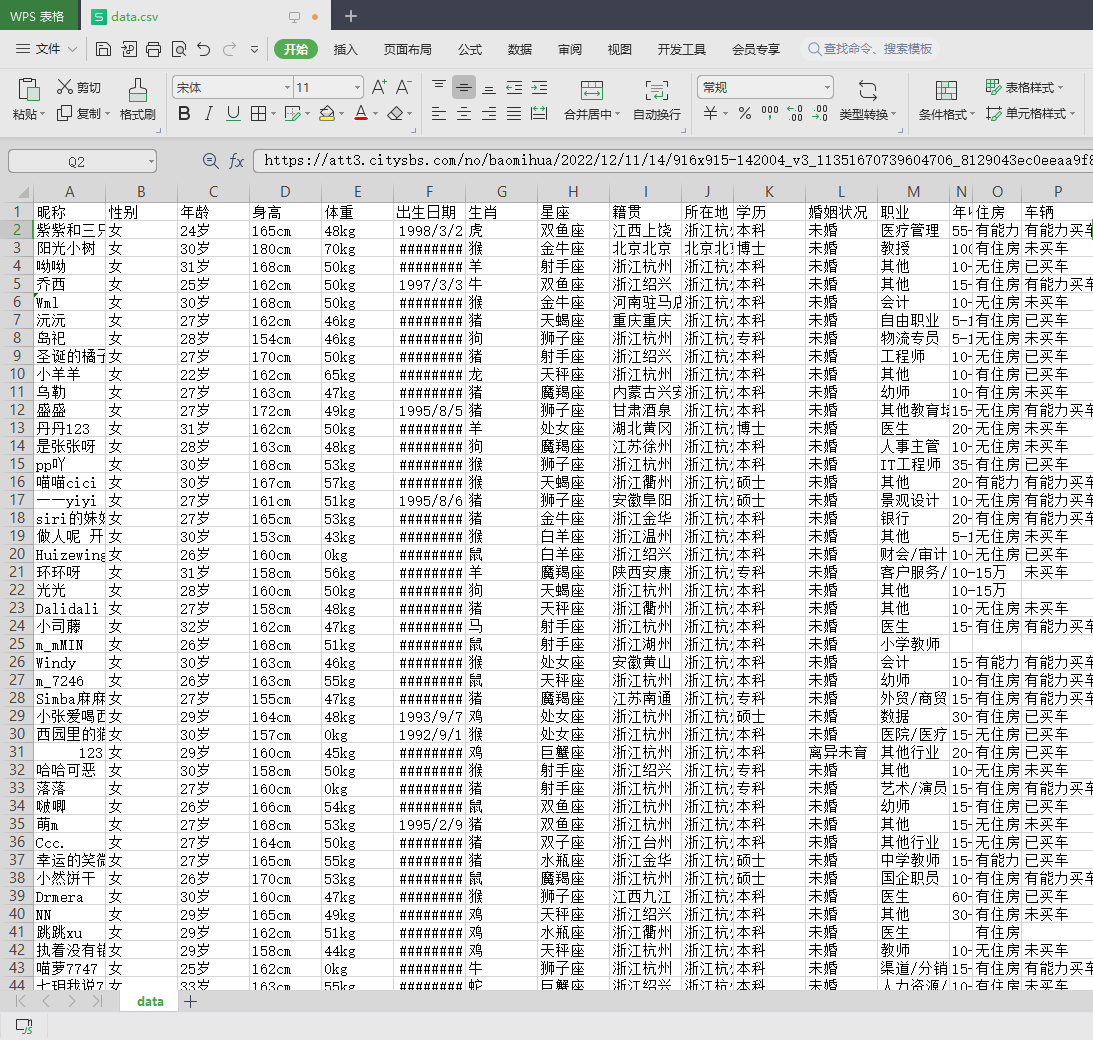
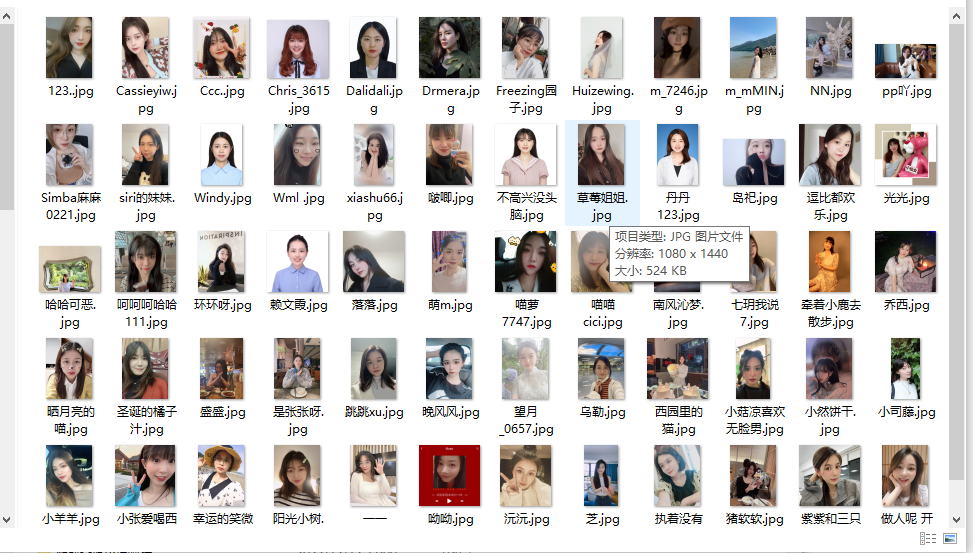
最后
今天的分享到這里就結束了 ,感興趣的朋友也可以去試試哈
對文章有問題的,或者有其他關于python的問題,可以在評論區留言或者私信我哦
覺得我分享的文章不錯的話,可以關注一下我,或者給文章點贊(/≧▽≦)/
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/541637.html
標籤:Python
上一篇:JDBC