文章概要
非常感謝☆Ronny丶博主在其博文《影像分析:二值影像連通域標記》中對二值影像連通域的介紹和演算法闡述,讓我這個毫無資料結構演算法底子的小白能夠理解和復現代碼,本文的目的是基于我自己的理解,對該博文中Two-Pass演算法的一些優化和補充,同時也希望幫助更多像我一樣的人較快地掌握連通域標記,
連通域標記是影像分割計數的一個重要環節,在工業上應用非常地多,例如像硬幣的計件,在二值化處理后,為了能夠感知數量,就得對硬幣區域進行標記(當然標記前可能還要經過一系列的形態學處理),另外,還有一個我想到的,更有趣、也更具有挑戰性的例子——二維碼連通域標記,這用來檢驗演算法的性能是再合適不過了,言歸正題——本文介紹了兩大流行演算法,一個是利用DFS的Seed-Filling演算法,另一個是Two-Pass演算法,后者因為處理等價對的方法不同,又細分為DFS Two-Pass(使用DFS處理等價對)和Union-Find Two-Pass(使用并查集處理等價對),如果硬要給這三種演算法排序的話,大概是Union-Find Two-Pass > Seed-Filling > DFS Two-Pass,反正我寫的程式是這樣的速度排序,

Seed-Filling演算法
這個演算法其實實質就是DFS,筆者曾經有幸做過一個“水洼連通”的演算法題,當時就是用DFS或者BFS來做的,顯然,“水洼連通”也是屬于連通域標記問題的,DFS在這個問題上的思路是:優先地尋找一個完整連通域,在找的同時把他們都標記一下,找完一個完整連通域, 再去找下一個連通域,按照這個想法,程式無非就是維護一個堆疊或者佇列罷了,寫起來相對簡潔易懂,要說缺點的話,就是頻繁的堆疊操作可能會拉低程式的性能,
簡要地說明一下這部分代碼含義,故事就定義成小明踩水坑吧,雖然小明對我表示自己很文靜,只喜歡做數學題,首先,定義了一個二維矩陣labels,大小跟二值圖一樣,一開始labels都是標簽0,這是一個無效標簽,可以理解為是充滿迷霧的未知區域或者是已確定的非水坑區域,小明每到達一個新的單位域(也就是一個新像素),首先要先看看這個域是不是未曾踩過的水坑(未曾踩過的水坑其標簽為0且灰度值為255),如果是的話,那么小明就原地開心地踩水坑了,踩過以后還不忘給它畫上一個大于0的標記(以標簽1為例),接下來,小明回顧四周,又發現了接壤的另一個水坑, 于是又在該水坑上留下了標記1······這樣看似單調的回圈,在小明眼里卻是一次次奇妙的冒險,愉快的時光很短暫,小明不一會兒就發現身邊已經沒有“新鮮”的水坑了,傷心的同時回到最初的那個水坑,繼續朝遠方走去,漸漸地,眼前依稀出現了陌生又熟悉的水坑,重現微笑的小明決定要開啟新的旅途,因此標記1.0進化至2.0,
故事的結束,要額外補充一點,程式里要不停地將新的單位域加入佇列, 因此佇列遍歷其上限是動態的,
void seedFilling(Mat &src) { // 標簽容器,初始化為標記0 vector<vector<int>> labels(src.rows, vector<int>(src.cols, 0)); // 當前的種子標簽 int curLabel = 1; // 四連通位置偏移 pair<int, int> offset[4] = {make_pair(0, 1), make_pair(1, 0), make_pair(-1, 0), make_pair(0, -1)}; // 當前連通域中的單位域佇列 vector<pair<int, int>> tempList; for (int i = 0; i < src.rows; i++) { for (int j = 0; j < src.cols; j++) { // 當前單位域已被標記或者屬于背景區域, 則跳過 if (labels[i][j] != 0 || src.at<uchar>(i, j) == 0) { continue; } // 當前單位域未標記并且屬于前景區域, 用種子為其標記 labels[i][j] = curLabel; // 加入單位域佇列 tempList.push_back(make_pair(i, j)); // 遍歷單位域佇列 for (int k = 0; k < tempList.size(); k++) { // 四連通范圍內檢查未標記的前景單位域 for (int m = 0; m < 4; m++) { int row = offset[m].first + tempList[k].first; int col = offset[m].second + tempList[k].second; // 防止坐標溢位影像邊界 row = (row < 0) ? 0: ((row >= src.rows) ? (src.rows - 1): row); col = (col < 0) ? 0: ((col >= src.cols) ? (src.cols - 1): col); // 鄰近單位域未標記并且屬于前景區域, 標記并加入佇列 if (labels[row][col] == 0 && src.at<uchar>(row, col) == 255) { labels[row][col] = curLabel; tempList.push_back(make_pair(row, col)); } } } // 一個完整連通域查找完畢,標簽更新 curLabel++; // 清空佇列 tempList.clear(); } } return; }
Two-Pass演算法
等價對生成
關于Two-Pass的演算法原理可以參考上面提到的博文,原文還是很詳細的,唯一的遺憾就是后面程式的注釋有點少,看起來會吃力些,說白了就是自己菜,要找一張二維影像中的連通域,很容易想到可以一行一行先把子區域找出來,然后再拼合成一個完整的連通域,因為從每一行找連通域是一件很簡單的事,這個程序中需要記錄每一個子區域,為了滿足定位要求,并且節省記憶體,我們需要記錄子區域所在的行號、區域開始的位置、結束的位置,當然還有一個表征子區域總數的變數,需要注意的就是子區域開始位置和結束位置在行首和行末的情況要單獨拿出來考慮,
// 查找每一行的子區域 // numberOfArea:子區域總數 stArea:子區域開始位置 enArea:子區域結束位置 rowArea:子區域所在行號 void searchArea(const Mat src, int &numberOfArea, vector<int> &stArea, vector<int> &enArea, vector<int> &rowArea) { for (int row = 0; row < src.rows; row++) { // 行指標 const uchar *rowData = https://www.cnblogs.com/kensporger/p/src.ptr(row); // 判斷行首是否是子區域的開始點 if (rowData[0] == 255){ numberOfArea++; stArea.push_back(0); } for (int col = 1; col < src.cols; col++) { // 子區域開始位置的判斷:前像素為背景,當前像素是前景 if (rowData[col - 1] == 0 && rowData[col] == 255) { numberOfArea++; stArea.push_back(col); // 子區域結束位置的判斷:前像素是前景,當前像素是背景 }else if (rowData[col - 1] == 255 && rowData[col] == 0) { // 更新結束位置vector、行號vector enArea.push_back(col - 1); rowArea.push_back(row); } } // 結束位置在行末 if (rowData[src.cols - 1] == 255) { enArea.push_back(src.cols - 1); rowArea.push_back(row); } } }
另外一個比較棘手的問題,如何給這些子區域標號,使得同一個連通域有相同的標簽值,我們給單獨每一行的子區域標號區分是很容易的事, 關鍵是處理相鄰行間的子區域關系(怎么判別兩個子區域是連通的),
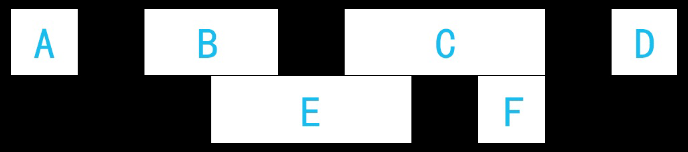
主要思路:以四連通為例,在上圖我們可以看出BE是屬于同一個連通域,判斷的依據是E的開始位置小于B的結束位置,并且E的結束地址大于B的開始地址;同理可以判斷出EC屬于同一個連通域,CF屬于同一個連通域,因此可以推知BECF都屬于同一個連通域,
迭代策略:尋找E的相連區域時,對前一行的ABCD進行迭代,找到相連的有B和C,而D的開始地址已經大于了E的結束地址,此時就可以提前break掉,避免不必要的迭代操作;接下來迭代F的時候,由于有E留下來的基礎,因此對上一行的迭代可以直接從C開始,另外,當前行之前的一行如果不存在子區域的話,那么當前行的所有子區域都可以直接賦新的標簽,而不需要迭代上一行,
標簽策略:以上圖為例,遍歷第一行,A、B、C、D會分別得到標簽1、2、3、4,到了第二行,檢測到E與B相連,之前E的標簽還是初始值0,因此給E賦上B的標簽2;之后再次檢測到C和E相連,由于E已經有了標簽2,而C的標簽為3,則保持E和C標簽不變,將(2,3)作為等價對進行保存,同理,檢測到F和C相連,且F標簽還是初始值0,則為F標上3,如此對所有的子區域進行標號,最終可以得到一個等價對的串列,
下面的代碼實作了上述的程序,子區域用一維vector保存,沒辦法直接定位到某一行號的子區域,因此需要用curRow來記錄當前的行,用firstAreaPrev記錄前一行的第一個子區域在vector中的位置,用lastAreaPrev記錄前一行的最后一個子區域在vector中的位置,在換行的時候,就去更新剛剛說的3個變數,其中firstAreaPrev的更新依賴于當前行的第一個子區域位置,所以還得用firstAreaCur記錄當前行的第一個子區域,
// 初步標簽,獲取等價對 // labelOfArea:子區域標簽值, equalLabels:等價標簽對 offset:0為四連通,1為8連通 void markArea(int numberOfArea, vector<int> stArea, vector<int> enArea, vector<int> rowArea, vector<int> &labelOfArea, vector<pair<int, int>> &equalLabels, int offset) { int label = 1; // 當前所在行 int curRow = 0; // 當前行的第一個子區域位置索引 int firstAreaCur = 0; // 前一行的第一個子區域位置索引 int firstAreaPrev = 0; // 前一行的最后一個子區域位置索引 int lastAreaPrev = 0; // 初始化標簽都為0 labelOfArea.assign(numberOfArea, 0); // 遍歷所有子區域并標記 for (int i = 0; i < numberOfArea; i++) { // 行切換時更新狀態變數 if (curRow != rowArea[i]) { curRow = rowArea[i]; firstAreaPrev = firstAreaCur; lastAreaPrev = i - 1; firstAreaCur = i; } // 相鄰行不存在子區域 if (curRow != rowArea[firstAreaPrev] + 1) { labelOfArea[i] = label++; continue; } // 對前一行進行迭代 for (int j = firstAreaPrev; j <= lastAreaPrev; j++) { // 判斷是否相連 if (stArea[i] <= enArea[j] + offset && enArea[i] >= stArea[j] - offset) { // 之前沒有標記過 if (labelOfArea[i] == 0) labelOfArea[i] = labelOfArea[j]; // 之前已經被標記,保存等價對 else if (labelOfArea[i] != labelOfArea[j]) equalLabels.push_back(make_pair(labelOfArea[i], labelOfArea[j])); }else if (enArea[i] < stArea[j] - offset) { // 為當前行下一個子區域縮小上一行的迭代范圍 firstAreaPrev = max(firstAreaPrev, j - 1); break; } } // 與上一行不存在相連 if (labelOfArea[i] == 0) { labelOfArea[i] = label++; } } }
DFS Two-Pass演算法
通過上面的努力,標記任務并沒有做完,最核心的部分正是如何處理等價對,這里簡單貼上原博主說的DSF方法,又是深搜啊,相比于直接DFS標記連通域,先找等價對再深搜減少了大量的堆疊操作,因為前者深度取決于連通域的大小,而后者是連通域數量,顯然這兩個數量級的差距挺大的,
原博主的想法是建立一個Bool型等價對矩陣,用作深搜環境,具體做法是先獲取最大的標簽值maxLabel,然后生成一個$maxLabel*maxLabel$大小的二維矩陣,初始值為false;對于例如(1,3)這樣的等價對,在矩陣的(0,2)和(2,0)處賦值true——要注意索引和標簽值是相差1的,就這樣把所有等價對都反映到矩陣上,
深搜的目的在于建立一個標簽的重映射,例如4、5、8是等價的標簽,都重映射到標簽2,最后重映射的效果就是標簽最小為1,且依次遞增,沒有缺失和等價,深搜在這里就是優先地尋找一列等價的標簽,例如一口氣把4、5、8都找出來,然后給他們映射到標簽2,程式也維護了一個佇列,當標簽在矩陣上值為true,而且沒有被映射過,就加入到佇列,
當然不一定要建立一個二維等價矩陣,一般情況,等價對數量要比maxLabel來的小,所以也可以直接對等價對串列進行深搜,但無論采用怎樣的深搜,其等價對處理的性能都不可能提高很多,
// 等價對處理,標簽重映射 void replaceEqualMark(vector<int> &labelOfArea, vector<pair<int, int>> equalLabels) { int maxLabel = *max_element(labelOfArea.begin(), labelOfArea.end()); // 等價標簽矩陣,值為true表示這兩個標簽等價 vector<vector<bool>> eqTab(maxLabel, vector<bool>(maxLabel, false)); // 將等價對資訊轉移到矩陣上 vector<pair<int, int>>::iterator labPair; for (labPair = equalLabels.begin(); labPair != equalLabels.end(); labPair++) { eqTab[labPair->first -1][labPair->second -1] = true; eqTab[labPair->second -1][labPair->first -1] = true; } // 標簽映射 vector<int> labelMap(maxLabel + 1, 0); // 等價標簽佇列 vector<int> tempList; // 當前使用的標簽 int curLabel = 1; for (int i = 1; i <= maxLabel; i++) { // 如果該標簽已被映射,直接跳過 if (labelMap[i] != 0) { continue; } labelMap[i] = curLabel; tempList.push_back(i); for (int j = 0; j < tempList.size(); j++) { // 在所有標簽中尋找與當前標簽等價的標簽 for (int k = 1; k <= maxLabel; k++) { // 等價且未訪問 if (eqTab[tempList[j] - 1][k - 1] && labelMap[k] == 0) { labelMap[k] = curLabel; tempList.push_back(k); } } } curLabel++; tempList.clear(); } // 根據映射修改標簽 vector<int>::iterator label; for (label = labelOfArea.begin(); label != labelOfArea.end(); label++) { *label = labelMap[*label]; } return; }
Union-Find Two-Pass演算法
如果讀者看到了這里,真的要感謝一下您的耐心,Two-Pass演算法的代碼要比直接深搜來得多,用不好甚至性能還遠不如深搜,原博主在文中提及了可以用稀疏矩陣來處理等價對,奈何我較為愚鈍,讀者可以自研之,
講到等價對,實質是一種關系分類,因而聯想到并查集,并查集方法在這個問題上顯得非常合適,首先將等價對進行綜合就是合并操作,標簽重映射就是查詢操作(并查集可以看做一種多對一映射),并查集具體演算法我就不嘮叨了,畢竟不怎么打程式設計競賽,不過,采用并查集的話,函式定義估計就滿天飛了,這里我包裝了一下,做成了類——實在是有點強迫癥,其中等價對生成的函式方法跟上面的是一樣的,
網上有一些代碼也實作了這個演算法,但是有的犧牲了秩優化,合并時讓樹指向較小的根,個人認為這樣做太不值了,所以為了解決這個,我在并查集映射后,又用labelReMap來進行第二次的映射,主要的步驟跟前面的差不多,
然后,自己跑了一下這代碼,不算畫圖示記的時間,效率要比上面的快四五倍左右,實時性上肯定是綽綽有余了,
#include<opencv2/opencv.hpp> #include<iostream> using namespace std; using namespace cv; class AreaMark { public: AreaMark(const Mat src,int offset); int getMarkedArea(vector<vector<int>> &area); void getMarkedImage(Mat &dst); private: Mat src; int offset; int numberOfArea=0; vector<int> labelMap; vector<int> labelRank; vector<int> stArea; vector<int> enArea; vector<int> rowArea; vector<int> labelOfArea; vector<pair<int, int>> equalLabels; void markArea(); void searchArea(); void setInit(int n); int findRoot(int label); void unite(int labelA, int labelB); void replaceEqualMark(); }; // 建構式 // imageInput:輸入待標記二值影像 offsetInput:0為四連通,1為八連通 AreaMark::AreaMark(Mat imageInput,int offsetInput) { src = imageInput; offset = offsetInput; } // 使用可區分的顏色標記連通域 void AreaMark::getMarkedImage(Mat &dst) { Mat img(src.rows, src.cols, CV_8UC3, CV_RGB(0, 0, 0)); cvtColor(img, dst, CV_RGB2HSV); int maxLabel = *max_element(labelOfArea.begin(), labelOfArea.end()); vector<uchar> hue; for (int i = 1; i<= maxLabel; i++) { // HSV color-mode hue.push_back(uchar(180.0 * (i - 1) / (maxLabel + 1))); } for (int i = 0; i < numberOfArea; i++) { for (int j = stArea[i]; j <= enArea[i]; j++) { dst.at<Vec3b>(rowArea[i], j)[0] = hue[labelOfArea[i]]; dst.at<Vec3b>(rowArea[i], j)[1] = 255; dst.at<Vec3b>(rowArea[i], j)[2] = 255; } } cvtColor(dst, dst, CV_HSV2BGR); } // 獲取標記過的各行子區域 int AreaMark::getMarkedArea(vector<vector<int>> &area) { searchArea(); markArea(); replaceEqualMark(); area.push_back(rowArea); area.push_back(stArea); area.push_back(enArea); area.push_back(labelOfArea); return numberOfArea; } // 查找每一行的子區域 // numberOfArea:子區域總數 stArea:子區域開始位置 enArea:子區域結束位置 rowArea:子區域所在行號 void AreaMark::searchArea() { for (int row = 0; row < src.rows; row++) { // 行指標 const uchar *rowData = https://www.cnblogs.com/kensporger/p/src.ptr(row); // 判斷行首是否是子區域的開始點 if (rowData[0] == 255){ numberOfArea++; stArea.push_back(0); } for (int col = 1; col < src.cols; col++) { // 子區域開始位置的判斷:前像素為背景,當前像素是前景 if (rowData[col - 1] == 0 && rowData[col] == 255) { numberOfArea++; stArea.push_back(col); // 子區域結束位置的判斷:前像素是前景,當前像素是背景 }else if (rowData[col - 1] == 255 && rowData[col] == 0) { // 更新結束位置vector、行號vector enArea.push_back(col - 1); rowArea.push_back(row); } } // 結束位置在行末 if (rowData[src.cols - 1] == 255) { enArea.push_back(src.cols - 1); rowArea.push_back(row); } } } void AreaMark::markArea() { int label = 1; // 當前所在行 int curRow = 0; // 當前行的第一個子區域位置索引 int firstAreaCur = 0; // 前一行的第一個子區域位置索引 int firstAreaPrev = 0; // 前一行的最后一個子區域位置索引 int lastAreaPrev = 0; // 初始化標簽都為0 labelOfArea.assign(numberOfArea, 0); // 遍歷所有子區域并標記 for (int i = 0; i < numberOfArea; i++) { // 行切換時更新狀態變數 if (curRow != rowArea[i]) { curRow = rowArea[i]; firstAreaPrev = firstAreaCur; lastAreaPrev = i - 1; firstAreaCur = i; } // 相鄰行不存在子區域 if (curRow != rowArea[firstAreaPrev] + 1) { labelOfArea[i] = label++; continue; } // 對前一行進行迭代 for (int j = firstAreaPrev; j <= lastAreaPrev; j++) { // 判斷是否相連 if (stArea[i] <= enArea[j] + offset && enArea[i] >= stArea[j] - offset) { // 之前沒有標記過 if (labelOfArea[i] == 0) labelOfArea[i] = labelOfArea[j]; // 之前已經被標記,保存等價對 else if (labelOfArea[i] != labelOfArea[j]) equalLabels.push_back(make_pair(labelOfArea[i], labelOfArea[j])); }else if (enArea[i] < stArea[j] - offset) { // 為當前行下一個子區域縮小上一行的迭代范圍 firstAreaPrev = max(firstAreaPrev, j - 1); break; } } // 與上一行不存在相連 if (labelOfArea[i] == 0) { labelOfArea[i] = label++; } } } //集合初始化 void AreaMark::setInit(int n) { for (int i = 0; i <= n; i++) { labelMap.push_back(i); labelRank.push_back(0); } } //查找樹根 int AreaMark::findRoot(int label) { if (labelMap[label] == label) { return label; } else { // path compression return labelMap[label] = findRoot(labelMap[label]); } } // 合并集合 void AreaMark::unite(int labelA, int labelB) { labelA = findRoot(labelA); labelB = findRoot(labelB); if (labelA == labelB) { return; } // rank optimization:tree with high rank merge tree with low rank if (labelRank[labelA] < labelRank[labelB]) { labelMap[labelA] = labelB; } else { labelMap[labelB] = labelA; if (labelRank[labelA] == labelRank[labelB]) { labelRank[labelA]++; } } } // 等價對處理,標簽重映射 void AreaMark::replaceEqualMark() { int maxLabel = *max_element(labelOfArea.begin(), labelOfArea.end()); setInit(maxLabel); // 合并等價對,標簽初映射 vector<pair<int, int>>::iterator labPair; for (labPair = equalLabels.begin(); labPair != equalLabels.end(); labPair++) { unite(labPair->first, labPair->second); } // 標簽重映射,填補缺失標簽 int newLabel=0; vector<int> labelReMap(maxLabel + 1, 0); vector<int>::iterator old; for (old = labelMap.begin(); old != labelMap.end(); old++) { if (labelReMap[findRoot(*old)] == 0) { labelReMap[findRoot(*old)] = newLabel++; } } // 根據重映射結果修改標簽 vector<int>::iterator label; for (label = labelOfArea.begin(); label != labelOfArea.end(); label++) { *label = labelReMap[findRoot(*label)]; } } int main() { Mat img = imread("img/qrcode.jpg", IMREAD_GRAYSCALE); threshold(img, img, 0, 255, THRESH_OTSU); AreaMark marker(img, 0); vector<vector<int>> area; int amount; // 1s for 1000 times amount = marker.getMarkedArea(area); Mat dst; marker.getMarkedImage(dst); imshow("img", img); imshow("dst", dst); waitKey(0); }
最后的最后,這些代碼都沒有經歷過“歲月的歷練”,如果存在不合理之處,請讀者指正!
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/56833.html
標籤:C++
上一篇:結題報告
下一篇:C++之策略模式