APNet下半場-NetML 技術干貨分享
2018年12月15日,APNet China Forum中國網路研究論壇在北京香山會議中心召開。此次研討會由APNet主辦,CCF互聯網專委會、CCF網路與資料通信專委會、ACM SIGCOMM China共同協辦。論壇邀請了位元組跳動、阿里巴巴、百度、華為、中國移動、Mellanox 等知名公司的行業大牛,以及香港科技大學、清華大學、國防科技大學等專家學者,圍繞著RDMA 和NetML兩個主題為大家帶來了一場視聽盛宴。星云Clustar作為RDMA技術與NetML技術的探索者,也參與了這一盛會。
這篇為下半場的NetML技術干貨分享,上半場的RDMA技術干貨在另外一篇單獨呈現,沒有看到的小伙伴可以直接登陸星云Clustar 官方公眾號:“Clustar2018”或知憾訓構號進行查閱。

下半場關于NetML技術的會議紀要:
來自清華大學的裴丹教授為大家分享了主題為《Autonomous IT Operations through Machine Learning》的精彩演講,演講內容主要圍繞著無人運維領域。裴丹教授指出,運維Ops是數字經濟的核心技術之一。隨著應用越來越復雜、網路系統越來越龐大和復雜、跨協議層的分布式系統越來越流行等諸多因素,使得運維事故屢次出現。這樣就需要大量的人力、物力來解決故障問題,同時查找故障也變得十分困難。導致這一結果的一個重要原因就是運維系統中存在著監控指標各異、例外各異、不同系統和設備上的千種不同日志等情況造成的。隨著AI技術的成熟,運維技術發展趨勢正從人肉運維過度到AI Ops。AI將逐步取代人力,它能夠自主快速解決故障,最終實作無人運維。但是,AI目前只擅長解決運維領域的部分問題,不同場景需要不同機器演算法。對此,裴丹教授通過三個AI Ops案例來說明。從資料中心交換機故障預測,自動配置TCP和擁塞控制以及智能檢測例外演算法,講述AI在運維領域的實際應用。在第一個案例中,通過特征工程以及隨機森林演算法實作的交換機故障檢測方案,取得非常好的效果;第二個案例中,裴丹教授提出一種通過訓練來動態調整TCP視窗的方式,很好的解決了傳統網路中服務器TCP視窗被事先固定的問題。雖然,現在的擁塞控制演算法一直在優化,但還無法做到普適性。裴丹教授提出通過用強化學習的方法,配置flow startup和congestion control的方式來適應具體的應用場景。該案例應用在百度搜索中,其優化后的演算法將TCP通信的性能提升了29%,這在傳統TCP通信領域是一個非常了不起的成就。最后一個案例中,裴丹教授提了出一套智能演算法,它無需要任何配置和標注。從樸素方法例外檢測到監督例外檢測、無監督例外檢測、輔助標注反饋,對百萬曲線進行例外檢測,最終實作自動適配曲線巨變。通過自動挑選演算法和引陣列合,多檢測器作為特征結合機器學習,避免通過人工調參,從而降低運維難度。對一個復雜的資料分布,通過VAE模型可以映射到一個更精確的分布,提高檢測的精度。星云Clustar認為,將AI技術應用在運維領域是未來一個非常重要的發展方向,可以極大的提升企業的運維維護效率和產能,降低運維費用。

阿里巴巴高級技術專家劉洪強博士為大家分享的是《Tiresias: A GPU Cluster Manager for Distributed Deep Learning》的主題演講。劉洪強博士提出深度學習訓練集群中的一個主要目標就是盡可能減少每個深度學習任務的排隊時間,而針對深度學習的調度方案則是實作這一目標的一個有效方法。現階段,深度學習任務往往同時依賴RDMA以及容器等基礎技術。如何使得這兩個技術可以平滑地結合在一起,從而使整個集群的任務具有客觀理性、調度性成為當前的一個難題。為了解決這一問題,劉洪強博士首先提出了FreeFlow。FreeFlow通過FreeFlowRouter(FFR)這一層,攔截容器中ibverbs的介面呼叫,并在FFR中做出相應的操作。本質上FreeFlow使得容器內對queue pair的操作被代理到FFR中的queue pair上,并且將容器內應用的記憶體映射至FFR,從而提升原生的RDMA性能。FreeFlow 保證了容器的可控性、隔離性以及可遷移性。星云Clustar認為,RDMA與容器技術相結合是未來的一個趨勢,我們在這一方面也有著自己的思考。之后,劉洪強博士講述了他的第二個作業:Tiresias。深度學習的任務執行時間往往是不可預測的,比如有些任務經常是機器學習科研作業者嘗試model性能的任務很快就會被主動kill掉。Tiresias不依賴于任務的執行時間,它通過時間和空間這兩個維度的優化演算法來優化任務的調度,從而減少任務的等待時間。
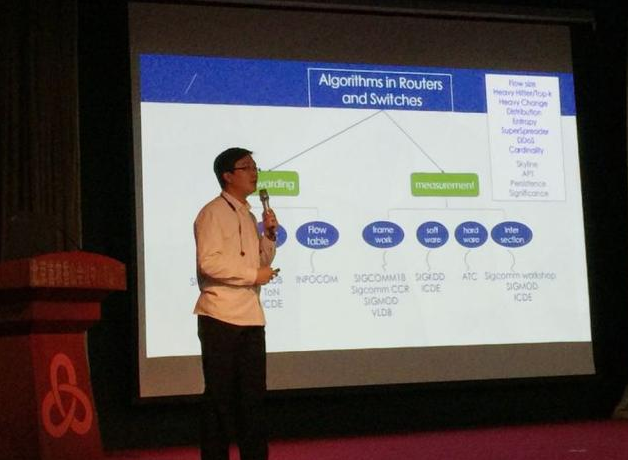
最后一位分享嘉賓是來自北京大學的楊仝教授。他分享的題目是《Empowering Sketches with Machine Learning for Network Measurements》。其內容為通過Sketch資料結構來進行網路測量。網路測量任務往往需要識別流的大小,區分大小流,同時也需要知道流的個數。現有的方案都基于資料包采樣,沒有辦法得到很好的測量精度。現在,大家普遍認為Sketch是一個比較好的方法。Sketch是一種類似Bloom Filter的資料結構,體積小效率高。已經有大量實際部署的應用使用Sketch來解決不同的網路測量任務,比如heavy changes sketch用于檢測流大小變化非常劇烈的流,從而定位可疑流量。楊仝教授接著介紹了一個通用框架(framework),將機器學習的方法來用于Sketch。首先通過采樣,然后根據采樣到的資料集來進行學習,并且構建Learning Sketch。不同的Sketch需要選擇不同的feature,然后進行訓練,產生最終的Sketch。楊仝教授強調當傳統生成的Sketch不準的時候,這種基于機器學習的方法可以發揮很大的功效,提升Sketch的精確度。楊仝教授也介紹了Sketch幾種常見的使用場景,比如估測Top-k的流量、數流的個數、以及cardinality統計。同時,也分享了在實際流量下的實驗室資料。星云Clustar認為,網路測量對于理解網路,從而更好的運維、優化網路具有非常重要的意義。Sketch作為一種大規模網路測量的有效手段,極大提高了網路測量的可行性。
uj5u.com熱心網友回復:

uj5u.com熱心網友回復:

轉載請註明出處,本文鏈接:https://www.uj5u.com/net/104721.html
標籤:非技術區
上一篇:多執行緒與EF的問題?
下一篇:字串加密問題