prometheus-net.DotNetRuntime 介紹
Intro
前面集成 Prometheus 的文章中簡單提到過,prometheus-net.DotNetRuntime 可以獲取到一些 CLR 的資料,比如說 GC, ThreadPool, Contention, JIT 等指標,而這些指標可以很大程度上幫助我們解決很多問題,比如應用執行程序中是否經常發生 GC,GC 等待時間時間是否過長,是否有發生死鎖或競爭鎖時間過長,是否有發生執行緒池餓死等等一系列問題,有了這些指標我們就可以清晰的在運行時了解到這些資訊,
來看一下官方介紹
A plugin for the prometheus-net package, exposing .NET core runtime metrics including:
- Garbage collection collection frequencies and timings by generation/ type, pause timings and GC CPU consumption ratio
- Heap size by generation
- Bytes allocated by small/ large object heap
- JIT compilations and JIT CPU consumption ratio
- Thread pool size, scheduling delays and reasons for growing/ shrinking
- Lock contention
- Exceptions thrown, broken down by type
These metrics are essential for understanding the peformance of any non-trivial application. Even if your application is well instrumented, you're only getting half the story- what the runtime is doing completes the picture.
支持的指標
Contention Events
只要運行時使用的 System.Threading.Monitor 鎖或 Native鎖出現爭用情況,就會引發爭用事件,
一個執行緒等待的鎖被另一執行緒占有時將發生爭用,
| Name | Description | Type |
|---|---|---|
| dotnet_contention_seconds_total | 發生鎖爭用的耗時(秒)總計 | Counter |
| dotnet_contention_total | 鎖爭用獲得鎖的數量總計 | Counter |
Thread Pool Events
Worker thread 執行緒池和 IO thread 執行緒池資訊
| Name | Description | Type |
|---|---|---|
| dotnet_threadpool_num_threads | 執行緒池中活躍的執行緒數量 | Gauge |
| dotnet_threadpool_io_num_threads | IO 執行緒池中活躍執行緒數量(WindowsOnly) | Gauge |
| dotnet_threadpool_adjustments_total | 執行緒池中執行緒調整總計 | Counter |
Garbage Collection Events
Captures information pertaining to garbage collection, to help in diagnostics and debugging.
| Name | Description | Type |
|---|---|---|
| dotnet_gc_collection_seconds | 執行 GC 回收程序耗費的時間(秒) | Histogram |
| dotnet_gc_pause_seconds | GC 回收造成的 Pause 耗費的時間(秒) | Histogram |
| dotnet_gc_collection_reasons_total | 觸發 GC 垃圾回收的原因統計 | Counter |
| dotnet_gc_cpu_ratio | 運行垃圾收集所花費的行程CPU時間的百分比 | Gauge |
| dotnet_gc_pause_ratio | 行程暫停進行垃圾收集所花費的時間百分比 | Gauge |
| dotnet_gc_heap_size_bytes | 當前各個 GC 堆的大小 (發生垃圾回收之后才會更新) | Gauge |
| dotnet_gc_allocated_bytes_total | 大小物件堆上已分配的位元組總數(每100 KB分配更新) | Counter |
| dotnet_gc_pinned_objects | pinned 物件的數量 | Gauge |
| dotnet_gc_finalization_queue_length | 等待 finalize 的物件數 | Gauge |
JIT Events
| Name | Description | Type |
|---|---|---|
| dotnet_jit_method_total | JIT編譯器編譯的方法總數 | Counter |
| dotnet_jit_method_seconds_total | JIT編譯器中花費的總時間(秒) | Counter |
| dotnet_jit_cpu_ratio | JIT 花費的 CPU 時間 | Gauge |
集成方式
上面的列出來的指標是我覺得比較重要的指標,還有一些 ThreadPool Scheduling 的指標和 CLR Exception 的指標我覺得意義不是特別大,有需要的可以去原始碼里看一看
集成的方式有兩種,一種是作者提供了一個默認的 Collector 會去收集所有支持的 CLR 指標資訊,另外一種則是可以自己自定義的要收集的 CLR 指標型別,來看示例:
使用默認的 Collector 收集 CLR 指標
DotNetRuntimeStatsBuilder.Default().StartCollecting();
使用自定義的 Collector 收集 CLR 指標
DotNetRuntimeStatsBuilder.Customize()
.WithContentionStats() // Contention event
.WithGcStats() // GC 指標
.WithThreadPoolStats() // ThreadPool 指標
// .WithCustomCollector(null) // 你可以自己實作一個自定義的 Collector
.StartCollecting();
上面提到過默認的 Collector 會收集支持的所有的 CLR 指標,且看原始碼怎么做的
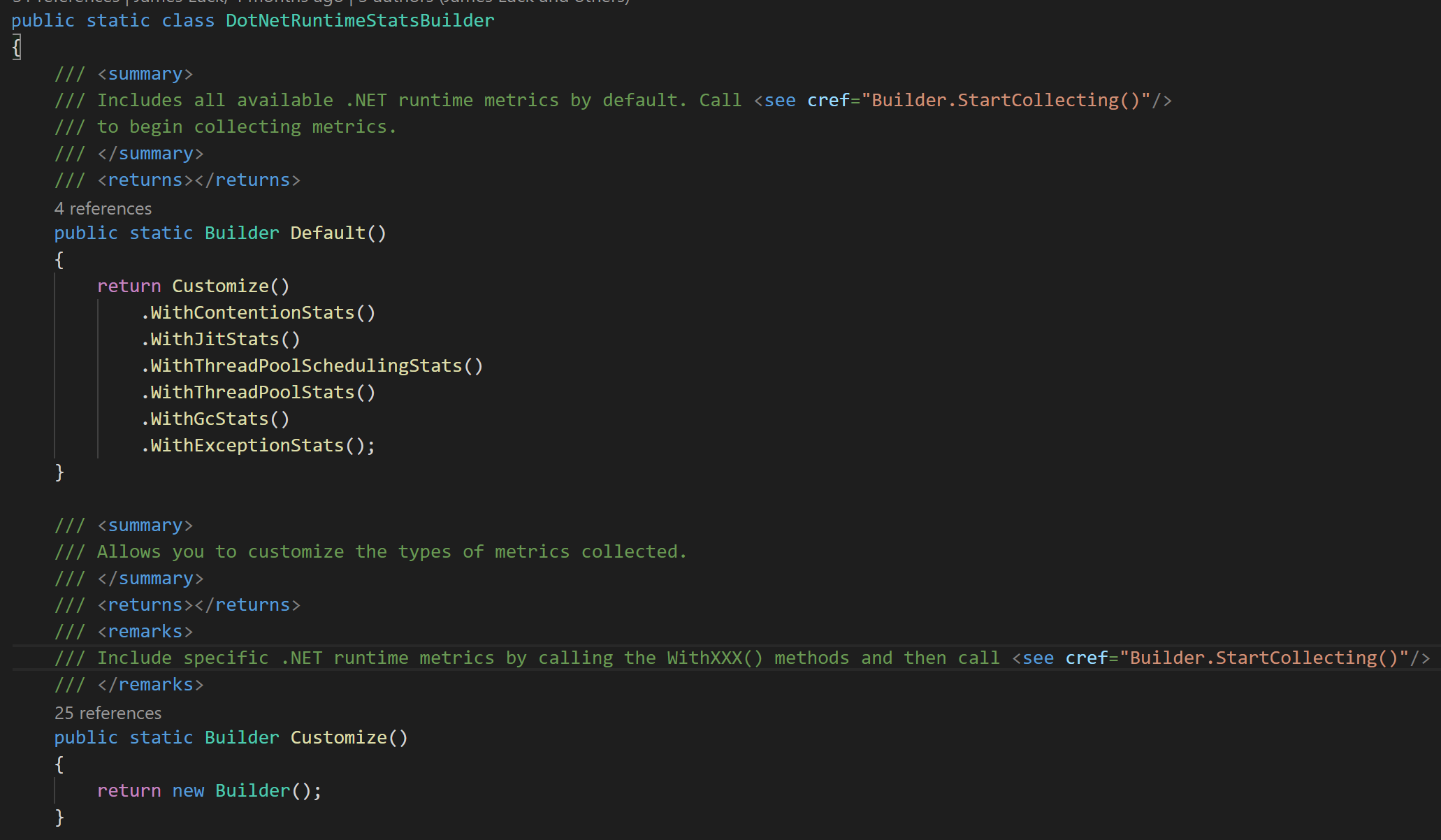
構建了一個 Builder 通過建造者模式來構建復雜配置的收集器,類似于 .net core 里的 HostBuilder/LoggingBuilder ...,像極了 Host.CreateDefaultBuilder,做了一些變形
原始碼地址:https://github.com/djluck/prometheus-net.DotNetRuntime/blob/master/src/prometheus-net.DotNetRuntime/DotNetRuntimeStatsBuilder.cs
實作原理
那它是如何作業的呢,如何實作捕獲 CLR 的指標的呢,下面我們就來解密一下,
在專案 README 里已經有了簡單的介紹,是基于 CLR 的 ETW Events 來實作的,具體的 CLR 支持的 ETW Events 可以參考檔案:https://docs.microsoft.com/en-us/dotnet/framework/performance/clr-etw-events
而 ETW Events 是通過 EventSource 的方式使得我們可以在行程外獲取到行程的一些運行資訊,這也是我們可以通過 PerfMonitor/PerfView 等方式行程外獲取行程 CLR 資訊的重要實作方式,同樣的微軟的新的診斷工具 dotnet diagnostic tools 的實作方式 EventPipe 也是基于 EventSOurce 的
而 EventSource 的事件不僅僅可以通過行程外的這些工具來消費,我們也可以在應用程式中實作 EventListener 來實作行程內的 EventSource 事件消費,而這就是 prometheus-net.DotNetRuntime 這個庫的實作本質方法
可以參考原始碼:https://github.com/djluck/prometheus-net.DotNetRuntime/blob/master/src/prometheus-net.DotNetRuntime/DotNetEventListener.cs
具體的事件處理是在對應的 Collector 中:
https://github.com/djluck/prometheus-net.DotNetRuntime/tree/master/src/prometheus-net.DotNetRuntime/StatsCollectors
Metrics Samples
為了比較直觀的看到這些指標可以帶來的效果,分享一下我的應用中用到的一些 dashboard 截圖
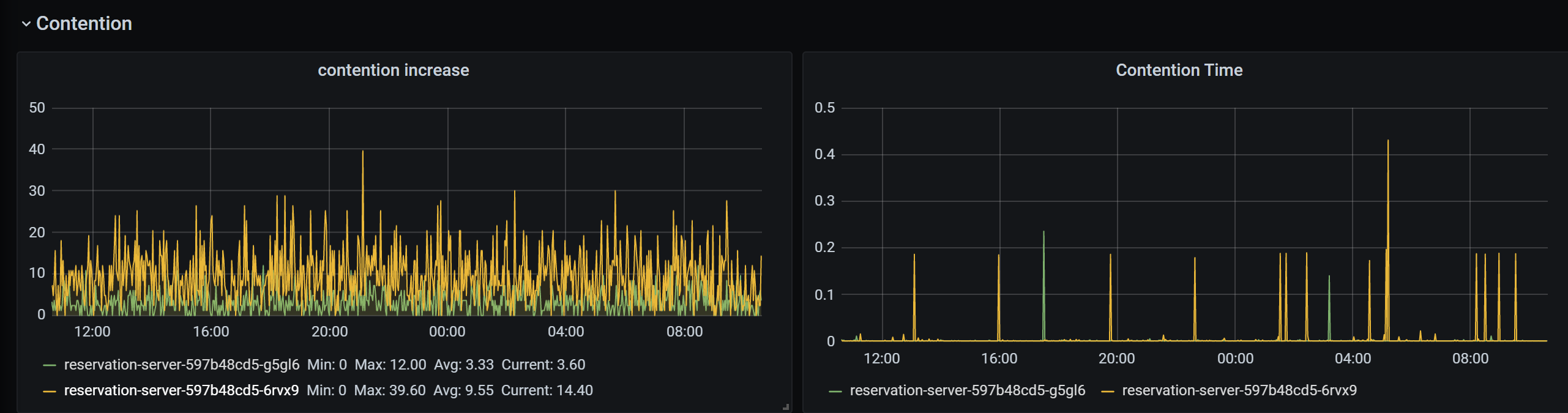
Lock Contention
GC
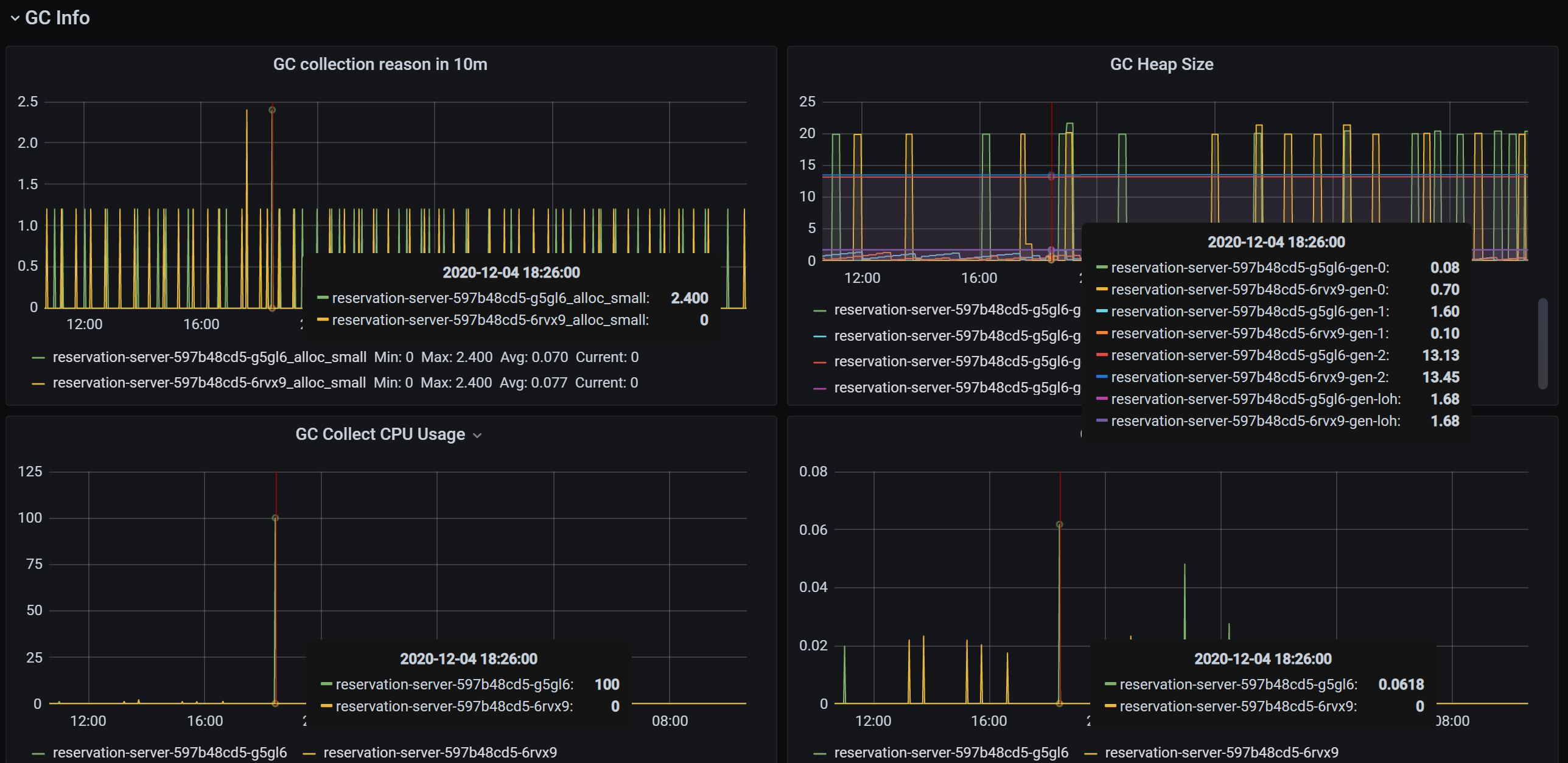
從上面的圖可以清晰的看到這個時間點發生了一次垃圾回收,此時 GC Heap 的大小和 GC 垃圾回收的CPU 占用率和耗時都可以大概看的出來,對于我們運行時診斷應用程式問題會很有幫助
Thread
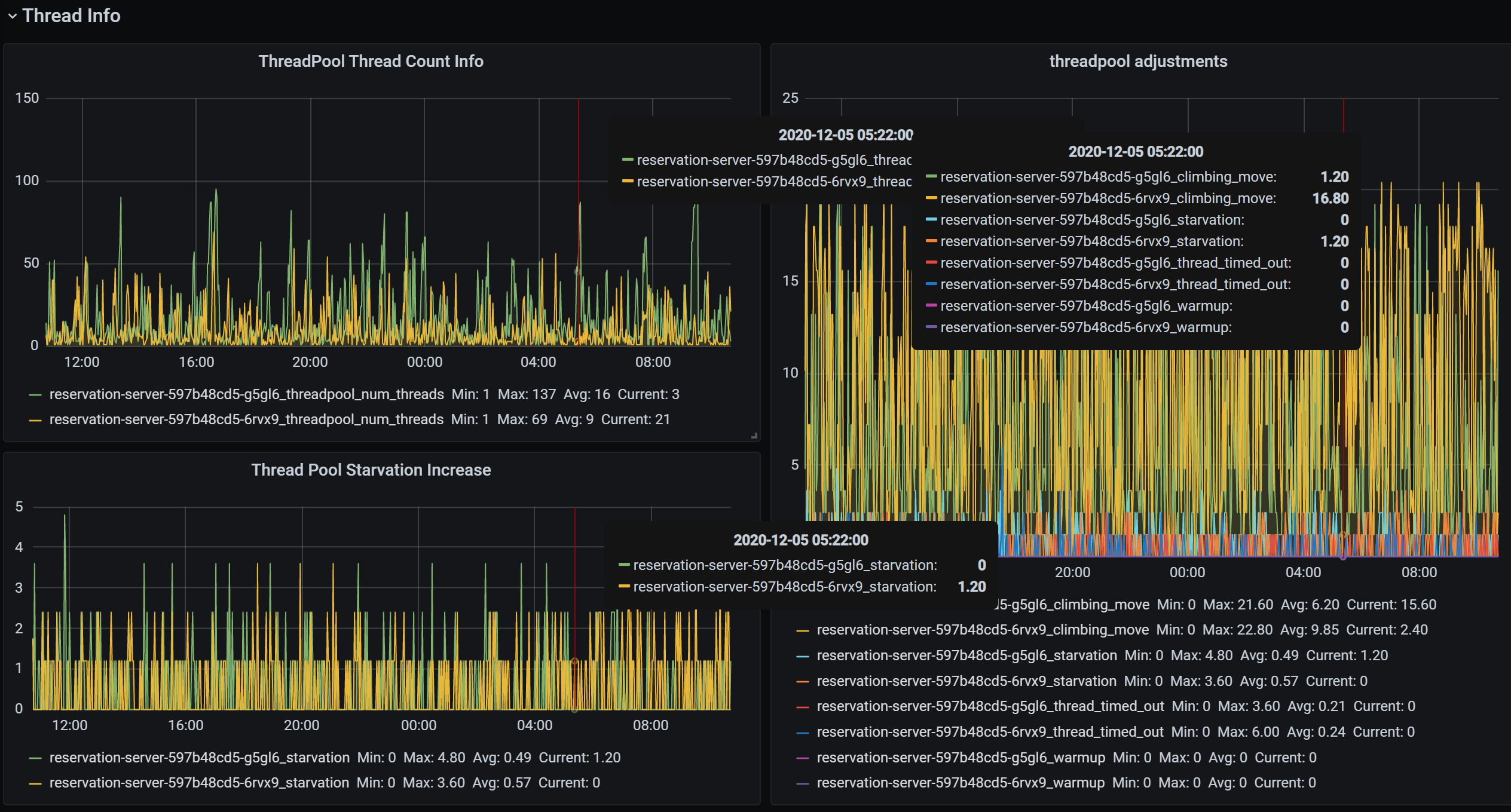
Thread 的資訊還可以拿到一些 threadpool 執行緒調度的數量以及延遲,這里沒有展示出來,
目前我主要關注的是執行緒池中執行緒的數量和執行緒池執行緒調整的原因,執行緒池執行緒調整的原因中有一個是 starvation,這個指標尤其需要關注一下,應避免出現 threadpool starvation 的情況,出現這個的原因通常是因為有一些不當的用法,如: Task.Wait、Task.Result、await Task.Run() 來把一個同步方法變成異步等不好的用法導致的
DiagnosticSource
除了 EventSource 之外,還有一個 DiagnosticSource 可以幫助我們診斷應用程式的性能問題,目前微軟也是推薦類別庫中使用 DiagnosticSource 的方式來讓應用診斷類別庫中的一些性能問題,這也是目前大多數 APM 實作的機制,Skywalking、ElasticAPM、OpenTelemetry 等都使用了 DiagnosticSource 的方式來實作應用程式的性能診斷
如果是行程外應用程式的性能診斷推薦首選 EventSource,如果是行程內推薦首選 DiagnosticSource
通常我們都應該使用 DiagnosticSource,即使想行程外捕獲,也是可以做到的
關于這二者的使用,可以看一下這個 Comment https://github.com/dotnet/aspnetcore/issues/2312#issuecomment-359514074
More
除了上面列出來的那些指標還有一些指標,比如 exception,threadpool scheduling,還有當前 dotnet 的環境(系統版本,GC 型別,Runtime 版本,程式 TargetFramework,CPU 數量等),有興趣的可以用一下試一下
exception 指標使用下來感覺幫助不大,有一些即使是已經處理的或者忽略的 Exception 也會被統計,這些 Exception 大多并不會影回應用程式的運行,如果參考這個的話可能會帶來很多的困擾,所以我覺得還是需要應用程式來統計 exception 指標更為合適一些
prometheus-net.DotNetRuntime 作為 prometheus-net 的一個插件,依賴于 prometheus-net 去寫 metrics 資訊,也就是說 metrics 的資訊可以通過 prometheus-net 來獲取
集成 asp.net core 的時候和之前集成 prometheus-net 是一樣的,metrics path 是同一個,可以參考我這個專案: https://github.com/OpenReservation/ReservationServer/tree/dev/OpenReservation
注意:作者推薦 .netcore3.0 以上使用,.netcore 2.x 會有一些 BUG,可以在 Issue 里看到
Reference
- https://github.com/djluck/prometheus-net.DotNetRuntime
- https://docs.microsoft.com/en-us/dotnet/framework/performance/clr-etw-events
- https://github.com/dotnet/aspnetcore/issues/2312#issuecomment-359514074
- https://github.com/OpenReservation/ReservationServer
轉載請註明出處,本文鏈接:https://www.uj5u.com/net/230567.html
標籤:.NET Core
上一篇:.Net編碼規范整理(一)