我目前正在嘗試用regex讀取一個日志檔案。我的日志以一個時間戳開始,然后是一個隨機的多行資訊,其中可能包括多個新行、回車和所有型別的字符。
重詞應該捕獲從時間戳開始的所有內容,實際的日志資訊,直到我們到達一個新的時間戳。目前,我通過使用一個正數前瞻來實作這一點,直到下一個時間戳。
在 web 端 regex101 的代碼或多或少地作業。在我們的安全事件管理器中,同樣的重碼不起作用。我需要保存每個事件,時間戳是第一個捕獲組,日志資訊是第二個捕獲組。
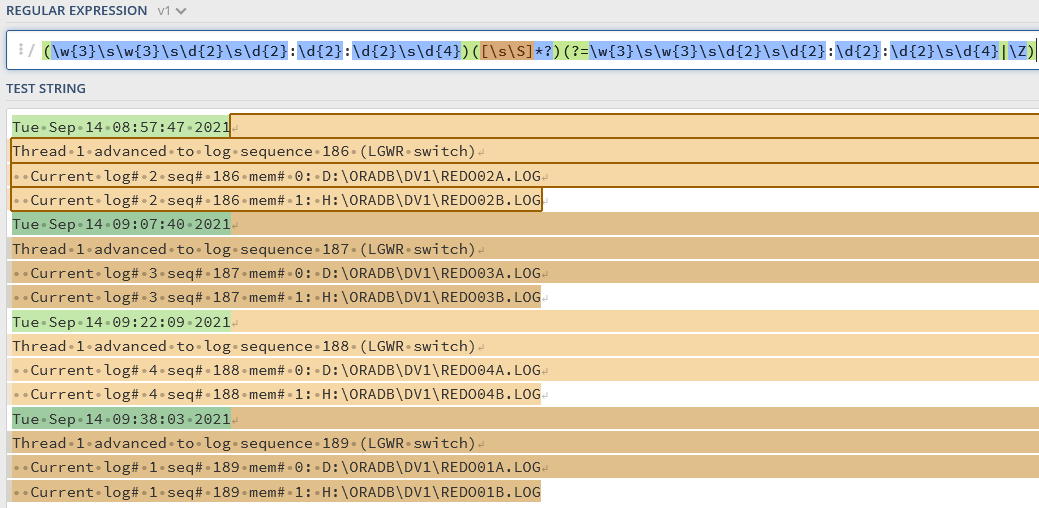
(w{3}s{1}w{3}s{1}d{2}s{1}d{2}: d{2}:d{2}s{1}d{4}}((
||.|
)*)(? =(w{3}s{1}w{3}s{1}d{2}s{1}d{2}: d{2}:d{2}s{1}d{4})
示例日志:
Tue Sep 14 08:57:47 2021 執行緒1前進到日志序列186(LGWR開關)。 當前日志# 2 seq# 186 mem# 0: D:ORADBDV1REDO02A.LOG 當前日志# 2 seq# 186 mem# 1: H:ORADBDV1REDO02B.LOG Tue Sep 14 09:07:40 2021 執行緒1推進到日志序列187(LGWR開關)。 當前日志# 3 seq# 187 mem# 0: D:ORADBDV1REDO03A.LOG 當前日志# 3 seq# 187 mem# 1: H:ORADBDV1REDO03B.LOG Tue Sep 14 09:22:09 2021 執行緒1推進到日志序列188(LGWR開關)。 當前日志# 4 seq# 188 mem# 0: D:ORADBDV1REDO04A.LOG 當前日志# 4 seq# 188 mem# 1: H:ORADBDV1REDO04B.LOG
地點:
(- 第1個抓捕組的起點()w{3}sw{3}sd{2}s- 比賽9月14日d{2}:d{2}:d{2}sd{4}- 匹配08:57:47 2021
)- 第1組捕獲的結束() - 第2個抓捕組的開始() - 第2個捕獲組的開始()[sS]*?- 匹配任何字符包括新行。匹配將以非希臘語的方式進行(因此是最不可能的匹配)。
) - 第二捕獲組的結束(?= - 前瞻性斷言的開始
w{3}sw{3}sd{2}sd{2}:d{2}:d{2}sd{4}- 下一部分必須是時間戳(這與這整個regex的第一部分的時間戳的匹配模式相同)。|- 或者- 或者下一個部分必須是字串的結尾。
) - 前瞻性斷言的結束。注意,由于這之前的模式是非貪婪的,這將永遠是最接近的時間戳,因此總是下一個時間戳。
轉載請註明出處,本文鏈接:https://www.uj5u.com/net/307572.html
標籤: