我有一個pandas資料框架。我想根據第一列的值條件計算另外兩列的總和和平均數,并得到每組的結果(sum, avg)和每組的例子數。
。
# quartile value1 value2
# 1 1 0.9
# 1 1 0.8
# 2 1 0.75
# 2 0 0.75
# 3 0 0.5
# 3 0 0.4 # 3 0 0.4
# 3 1 0.3
# 4 0 0.1
我想要的輸出應該是:
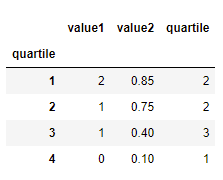
# quartile value1_sum value2_avg no_of_in_val1.
# 1 2 0.85 2
# 2 1 0.75 2
# 3 1 0.40 3
# 4 0 0.10 1
有人能幫忙嗎?
uj5u.com熱心網友回復:
假設你的資料:
data = pd. DataFrame({"quartile"/span> : [1, 1, 2, 2, 3, 3, 3, 4], "value1" 。[1, 1, 1, 0, 0, 0, 1, 0], "value2" 。[0. 9, 0.8, 0.75, 0.75, 0。 5, 0.4, 0.3, 0.1] })
你可以通過以下方式進行匯總:
data.groupby("quartile"/span>)。 agg({"value1" : sum, "value2" : mean, "quartile" : len})
然后你只需按照你的意愿重新命名這些列。
uj5u.com熱心網友回復:
為了更好地堅持你想要的輸出,我們可以使用命名的聚合,如下:
(df.groupby('quartile', as_index=False)
.agg(value1_sum=('value1', 'sum') 。
value2_avg=('value2', 'mean') 。
no_of_instances_in_val1=('value1', 'size') )
)
輸出
quartile value1_sum value2_avg no_of_instances_in_val1
0 1 2 0.85 2
1 2 1 0.75 2
2 3 1 0.40 3
3 4 0 0.10 1
轉載請註明出處,本文鏈接:https://www.uj5u.com/net/309442.html
標籤: