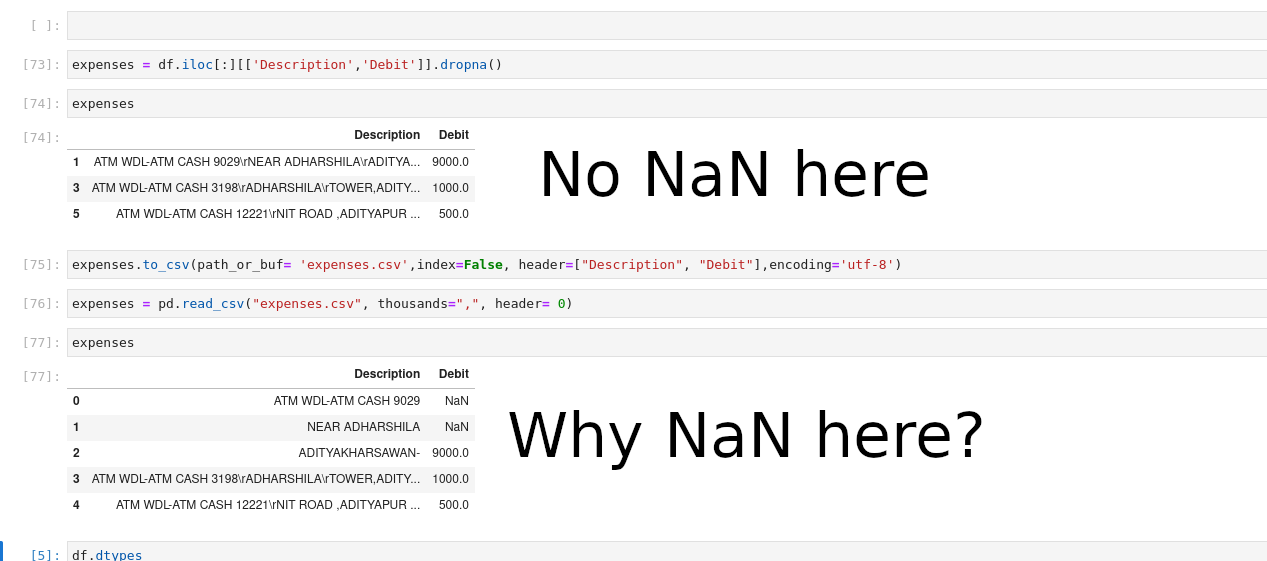
我正試圖將一個資料框架放入一個csv檔案,然后訪問它。但這樣做會出現NaN值,而且資料會錯位。
expenses = df.iloc[:][['Description','Debit']] .dropna()
在這里,我試圖獲得沒有NaN資料的Description和debit列。
expenses.to_csv(path_or_buf= 'expenses. csv',index=False, header=["Description", "Debit"],encoding='utf-8')
expenses = pd.read_csv("expenses.csv", thousands=", ", header=0)
然后將該資料框架保存為費用,并試圖訪問相同的csv檔案,但內容卻錯位了。當我打開 csv 檔案時,它是正確的。
這里,是一個螢屏截圖,以幫助你理解:
"#">"#">"#">"#">。
uj5u.com熱心網友回復: 這是因為,通過默認的 它應該作業。你的
標籤: 上一篇:設定一個字串的元組作為dict鍵
inplace=False,當你使用dropna ,做:df.dropna(subset=['Description','Debit'], inplace=True)
df,在這種情況下,應該已經洗掉了這兩列上的NaN值。