我有兩個資料框,一個長一個寬,我試圖將兩者合并在一起。我有寬格式的人口統計資訊,我需要將其帶入長格式進行分析。當我合并兩個資料幀時,寬格式的資訊僅填充一行,其余為空白。
以下是一些示例資料,用于顯示我正在使用的內容以及我希望得到的結果。唯一的問題是合并適用于示例資料,但不適用于我的實際資料。
df_long <- data.frame (id = c(123, 123, 123, 345, 345),
x = c("abc", "cgf", "add", "wer", "nko"),
y = c(234, 234, 5436, 73435, 2353))
df_wide <- data.frame(id = c(123, 345),
person = c("Mom", "Teen"))
當我使用此代碼合并示例資料時,它會導致我想要的資料
df_goal <- merge(df_long, df_wide)
當我使用這段代碼時,它有正確數量的變數,但有 0 個觀察值。
real_merged <- merge(real_long, real_wide)
為了解決這個問題,我添加了all = T引數,但我得到的觀察結果比我預期的要多。看起來合并只是將 df_wide 的觀察數添加到 df_long,但與 ID 不匹配。我已經在視覺上確認有匹配的 ID,所以這不應該發生。
我的真實資料有超過 10 萬行和 150 個變數。我不確定這是否與它有關,所以我只是把它扔在那里。
我已經嘗試在合并函式中使用不同的引數,例如all = T也沒有使用它,以及by = and by.x = but none 導致我正在尋找的結果。我也研究過使用melt(),但我無法讓它作業。
由于沒有錯誤并且它不會在示例資料中重現,因此幾乎不可能進行故障排除。我希望那里有人遇到過類似的問題并且知道解決方法。
uj5u.com熱心網友回復:
您只需指定要保留其中一個表的所有資料,而不是兩者的all=TRUE所有資料(保留兩個表的所有資料,這是默認設定)。
df_long <- data.frame (id = c(123, 123, 123, 345, 345),
x = c("abc", "cgf", "add", "wer", "nko"),
y = c(234, 234, 5436, 73435, 2353))
df_wide <- data.frame(id = c(123, 345),
person = c("Mom", "Teen"))
df_goal <- merge(df_long, df_wide, all.x=TRUE, by="id")
輸出如下所示:
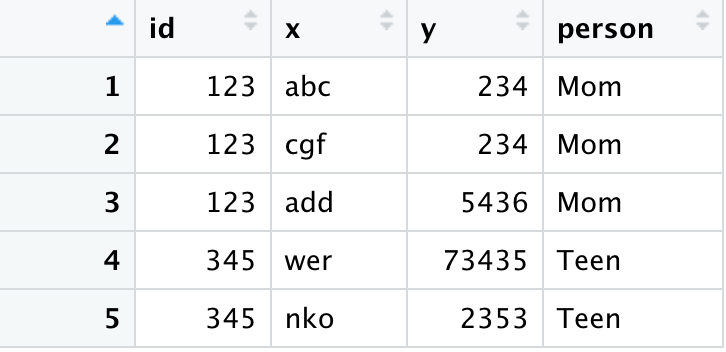
這all.x=TRUE意味著額外的行將添加到輸出中,x 中的每一行在 y 中沒有匹配的行。這些行將在那些通常用來自 y 的值填充的列中具有 NA。相反,如果它們確實匹配,則將使用 y 的值。
uj5u.com熱心網友回復:
好的,我能夠弄清楚。我正在將 SPSS 檔案匯入 R,其中一個資料框附有變數標簽,這似乎是 ID 值未鏈接的原因。我不確定為什么會發生這種情況,但我將 SPSS 檔案保存為 Excel 檔案,然后將其匯入到 R 中,合并作業完美。
轉載請註明出處,本文鏈接:https://www.uj5u.com/net/313019.html
上一篇:將行從年值到月值pandas