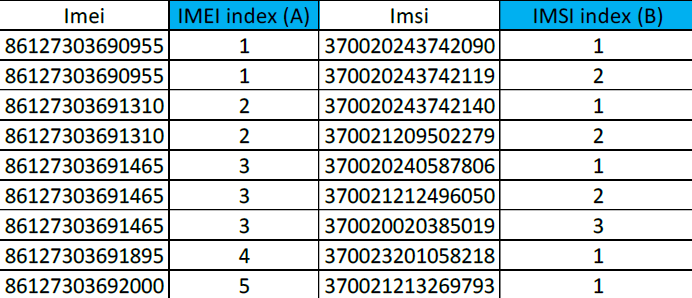
要為“IMEI & IMSI”對創建索引,如下所示:
- IMEI 索引(命名為 A):按順序為每個 IMEI 分配一個編號,從整數 1 開始。
- IMSI 索引(命名為 B):為每個 IMSI 分配一個編號,從某種意義上說:如果一個 IMEI 出現多次,則配對的 IMSI 將按順序分配,例如:1、2、3...] 2
這就是我正在嘗試的
import pandas as pd
import numpy as np
df1 = pd.readcsv('file.csv')
df1 = df1[['Imei','Imsi']]
df1 = df1.groupby(['Imei']).count()
df1 = df1.rename(columns = {'Imsi': 'Occurences'})
df1 = df1.sort_values(by=['Occurences'],ascending= False)
df1 = df1.reset_index()
我能夠計算出現次數,但如何從 1 開始按順序列印它們,如圖所示
uj5u.com熱心網友回復:
使用cumsum計算IMEI Index和groupby_cumcount計算IMSI Index。
# Setup
df = pd.DataFrame({'Imei': {0: 'A', 1: 'A', 2: 'B', 3: 'B', 4: 'C', 5: 'C', 6: 'C', 7: 'D', 8: 'E'}})
df['IMEI Index'] = df['Imei'].ne(df['Imei'].shift()).cumsum()
df['IMSI Index'] = df.groupby('Imei').cumcount().add(1)
輸出:
>>> df
Imei IMEI Index IMSI Index
0 A 1 1
1 A 1 2
2 B 2 1
3 B 2 2
4 C 3 1
5 C 3 2
6 C 3 3
7 D 4 1
8 E 5 1
轉載請註明出處,本文鏈接:https://www.uj5u.com/net/313622.html