我有兩個資料幀作為打擊(df5 和 dfS),保存空氣污染資料。可以看出,它們的索引是 DateTime。在 DateTime 索引中,第二個讀數是不同的。所以我想在他們閱讀的日期、小時和分鐘相同時合并它們,而忽略第二個。df5:
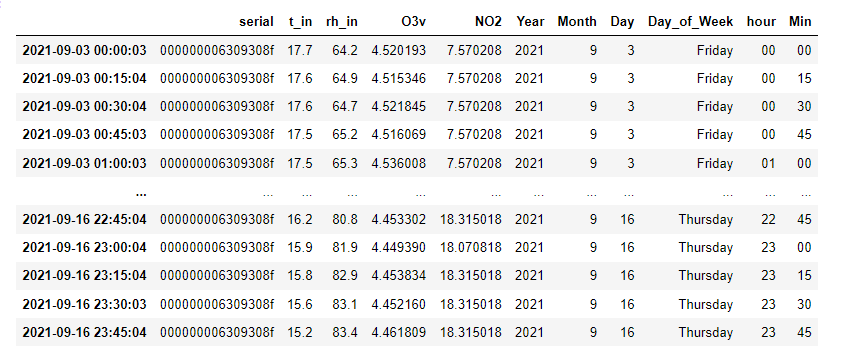
dfs:

下面是我的代碼:
dfG=df5.merge(dfS,left_on='Min', right_on='Min' )
dfG['DATETIME'] = dfG.Date "_" dfG.Time
dfG.to_csv('dfG.csv')
dfG.set_index("DATETIME", inplace=True)
#correct the underscores in old datetime format
dfG.index = [" ".join(str(val).split("_")) for val in dfG.index]
可以看出索引不正確,因為我認為“Min”是加入的關鍵。
DFG:
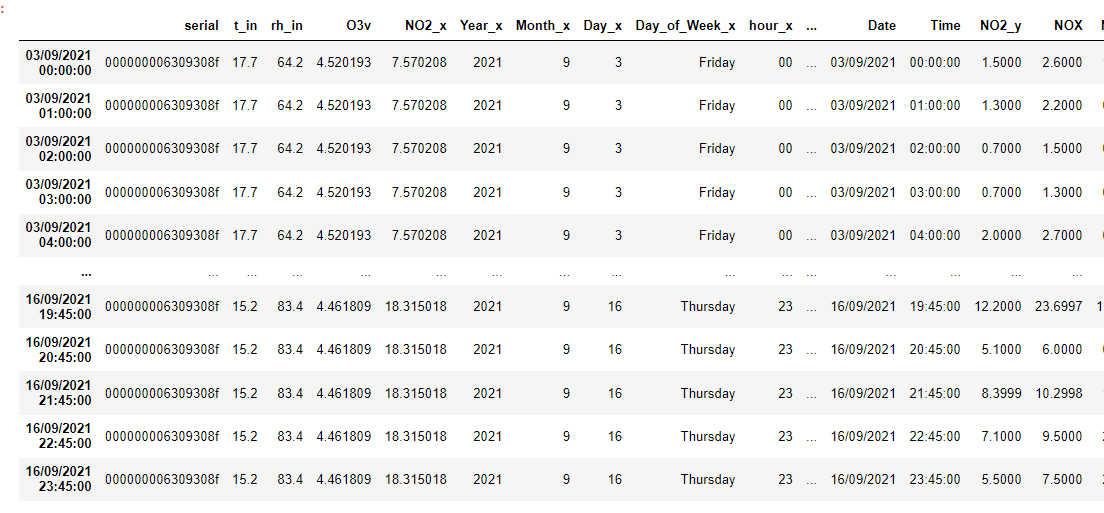
我的問題是:如何根據忽略第二個的 DateTime 索引合并這兩個資料幀。
uj5u.com熱心網友回復:
如果時間戳上的秒數不重要,也許這可以幫助:
df5.index = df5.index.map(lambda x: x.replace(second=0))
轉載請註明出處,本文鏈接:https://www.uj5u.com/net/313677.html
上一篇:使用matplotlib在同一軸上繪制兩個Pandas時間序列-意外行為
下一篇:API回應日期格式