我正在用 Spark 作業運行加速實驗。不幸的是,我似乎無法將 Spark 限制為真正的一個核心。(我有 128 個)
我使用以下設定來嘗試實作這一目標:
os.environ['NUMBEXPR_MAX_THREADS'] = partitions
os.environ['NUMEXPR_NUM_THREADS'] = partitions
spark = SparkSession.builder \
.master("local") \
.config("spark.executor.instances", "1") \
.config("spark.executor.cores", "1") \
.config("spark.sql.shuffle.partitions", "1") \
.config("spark.driver.memory", "50g") \
.getOrCreate()
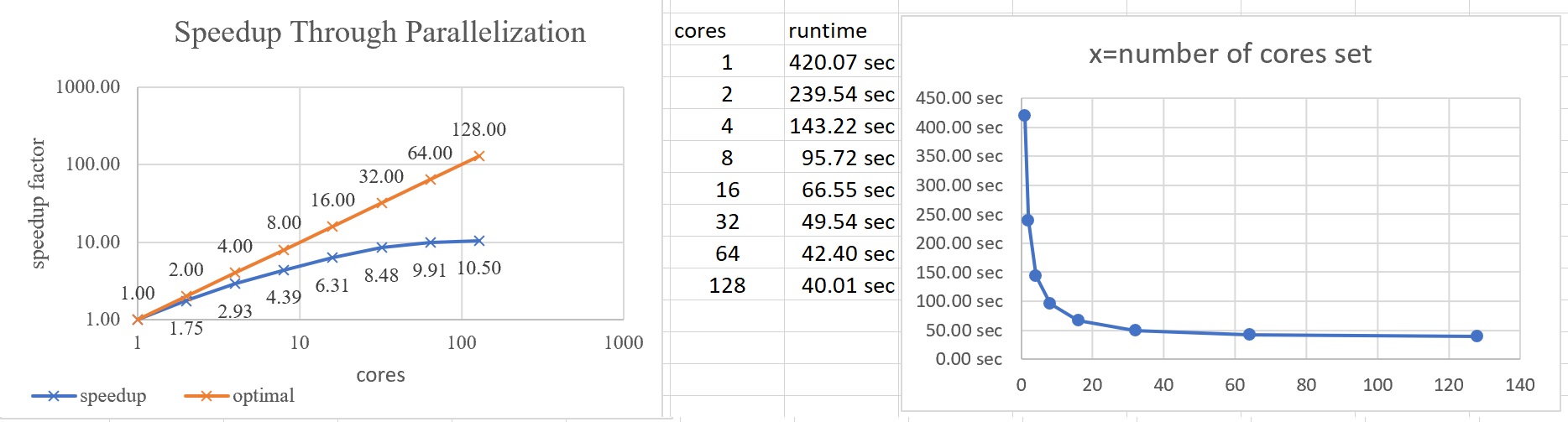
我確實得到了一個很好的加速曲線,但我也可以在 htop 上看到,這項作業仍在使用多個核心。
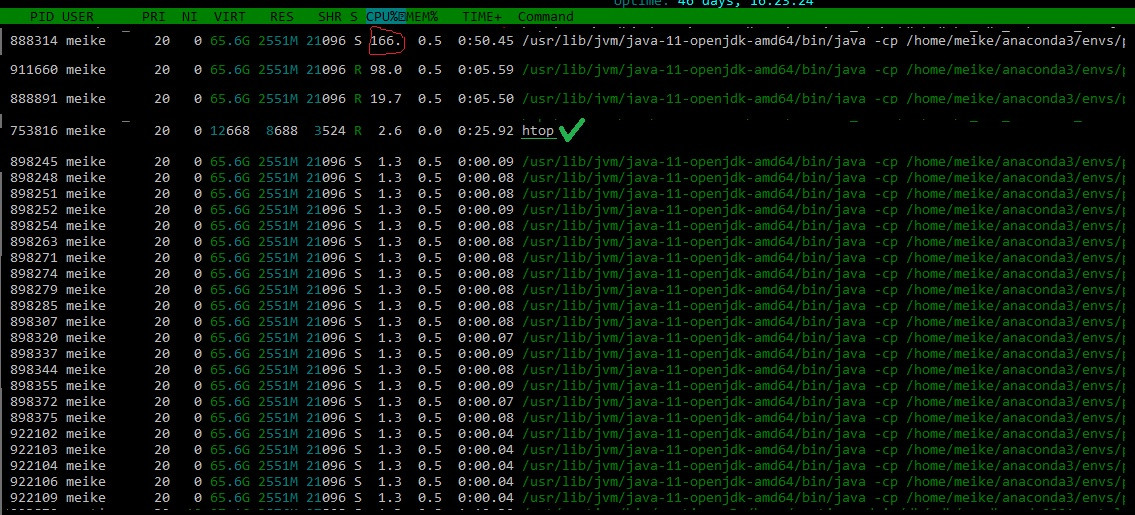
我在螢屏上運行 spark 作業,在第二個終端運行 htop。htop 使用 CPU 是可以的。但我不明白為什么最頂層的行程仍然使用超過 100% 的 CPU。(100% 相當于完全使用一個核心)。相反,在單核設定中,此程序有時會達到 400%。好像不對。此外,當我啟動 spark 作業時,還會彈出其他幾個行程,它們也使用了大量 CPU。
有沒有人建議我如何強制 Spark 真正使用一個內核?
并且最好不要扇出所有核心(不是每個核心的使用率約為 1%,而是一個 100%)
PS:到目前為止,限制 Spark 最重要的似乎是磁區。如果它們被設定為默認值 200,Spark 以完全并行化運行,即使它被告知使用一個核心和一個節點......
uj5u.com熱心網友回復:
您可以使用taskset命令將行程限制為單個或多個指定的核心。
taskset -c 0 mycommand
-c, --cpu-list
Interpret mask as numerical list of processors instead of a
bitmask. Numbers are separated by commas and may include
ranges. For example: 0,5,8-11.
uj5u.com熱心網友回復:
創建spark session的時候,可以在設定master的時候設定核心數,直接passlocal[1]而不是local,如下:
spark = SparkSession.builder.master("local[1]")
見大師的方法 scaladoc:
設定要連接到的 Spark 主 URL,例如“local”以在本地運行,“local[4]”以 4 個內核在本地運行,或“spark://master:7077”以在 Spark 獨立集群上運行。
轉載請註明出處,本文鏈接:https://www.uj5u.com/net/319109.html
上一篇:如何聚合多列并輸出為行?