在使用 spark.read.json 時,我對 Spark 上的延遲加載感到困惑。
我有以下代碼:
df_location_user_profile = [
f"hdfs://hdfs_cluster:8020/data/*/*"
]
df_json = spark.read.json(json_data_files)
雖然 HDFS 上的 JSON 資料按年和月(年 = yyyy,月 = 毫米)進行磁區,但我想檢索該資料集的所有資料。對于這個代碼塊,我只從定義的位置讀取資料,并且沒有執行任何操作。但是我在 Spark UI 上發現了具有大量輸入資料的以下階段。
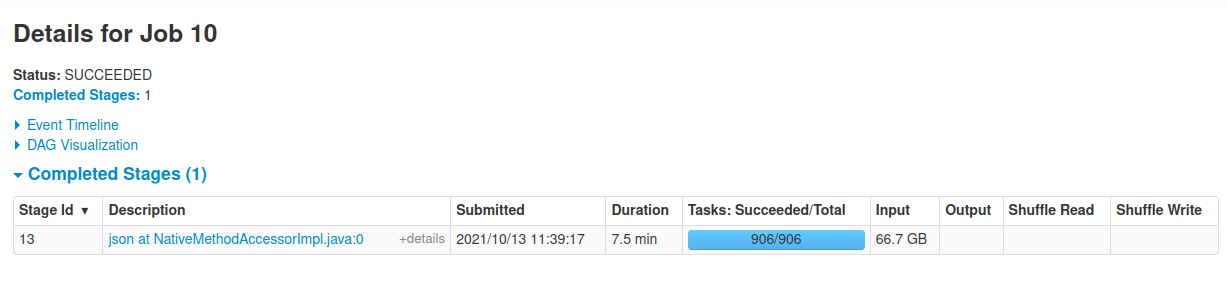
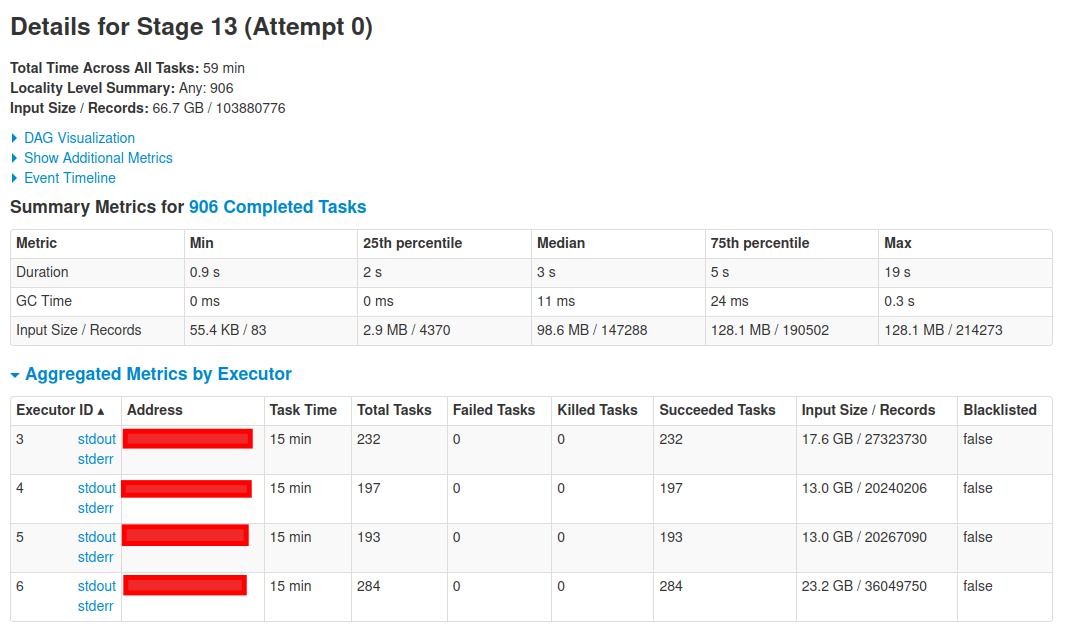
據我了解,Spark 的延遲加載方式在呼叫操作之前不會讀取資料。那么這讓我很困惑。
之后,我呼叫該count()操作,然后創建新階段,Spark 再次讀取資料。
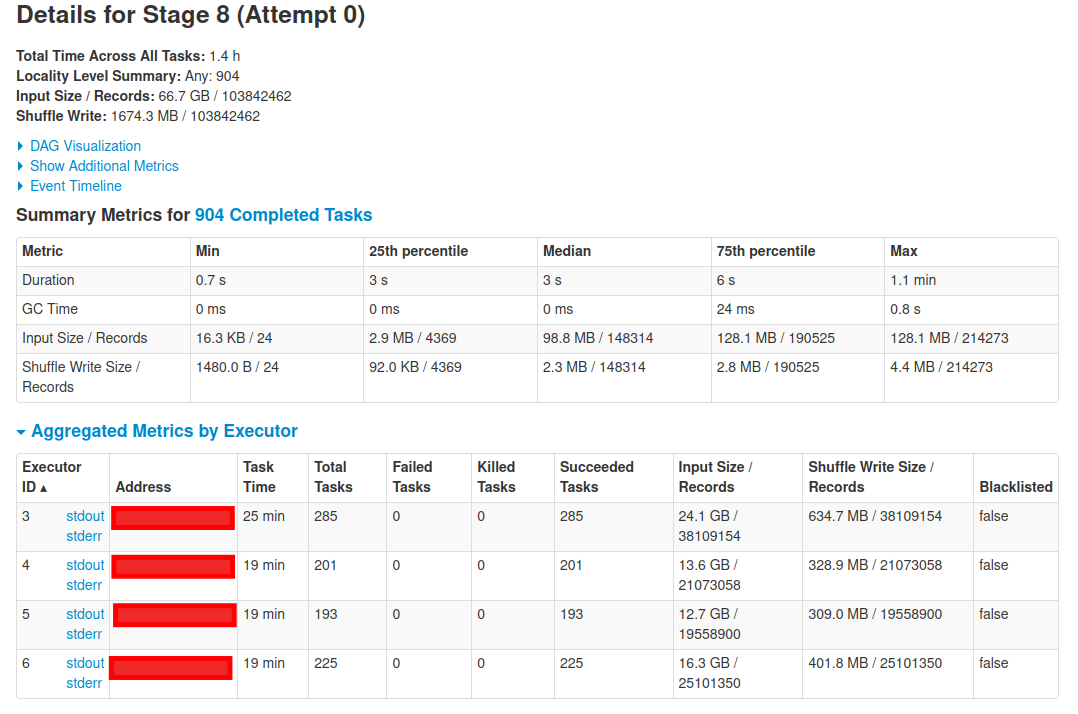
我的問題是為什么 Spark 在沒有呼叫任何操作時讀取資料(在第一個作業,階段)?我怎樣才能優化這個?
uj5u.com熱心網友回復:
它正在通過評估架構,因為它沒有提供。又名推斷模式。
轉載請註明出處,本文鏈接:https://www.uj5u.com/net/319113.html
標籤:json 阿帕奇火花 火花 apache-spark-sql
上一篇:AzureDatabricks多任務作業和作業流。模擬完成狀態
下一篇:無法從AzureBlob讀取:“org.apache.hadoop.fs.azure.AzureException:未找到Azure存盤帳戶的憑據