我正在寫一段代碼,從stdin讀入一個輸入檔案,并輸出完全相同的內容(到stdout),除了以下列方式替換在 "字典 "中發現的任何單詞,而且順序完全相同:
。
- 如果該詞與 "字典 "中的內容完全一致,則該詞將被替換。
- 如果出現了與字典中的鍵值完全相同的詞,那么就找到相應的值對,并將其列印出來。
- 如果這個詞被正確地大寫(例如,Thomas,第一個字母大寫,其他都小寫)是字典中的一個有效的鍵,則列印出相應的值對,而不是 。
- 如果小寫的版本是一個有效的鍵,則列印出其相應的值 。
- 如果沒有匹配,就按原樣列印出來。 (所有非字母的字符都是 "正常 "列印出來的。)
但我遇到的一個問題是,當我在做(2)時,當我測驗 "IPSUM"(全部為大寫)時,一個字符('U')不知何故被標記到 "字串 "或 copy2 陣列的末尾。
例如,請看這個輸出。
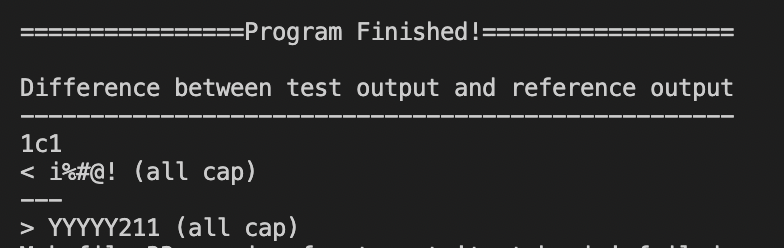 。
我的輸出是在帶有"< "的行中,而"> "表示本應如此。根據我的檢查順序,由于IPSUM不在字典中(關于字典的內容,見本帖末尾),它到了(2),IPSUM應該變成Ipsum,它應該列印出Ipsum的相應值。但我得到的卻是IpsumU,所以字典不承認這個詞。但我不確定這個'U'是從哪里來的,因為輸入的內容正是
。
我的輸出是在帶有"< "的行中,而"> "表示本應如此。根據我的檢查順序,由于IPSUM不在字典中(關于字典的內容,見本帖末尾),它到了(2),IPSUM應該變成Ipsum,它應該列印出Ipsum的相應值。但我得到的卻是IpsumU,所以字典不承認這個詞。但我不確定這個'U'是從哪里來的,因為輸入的內容正是
。IPSUM (all cap).誰能幫我找出我的代碼中可能存在的問題?
//for reference: typedef struct HashBucketEntry { void *key。 void *data; struct HashBucketEntry *next; /span> } HashBucketEntry。 typedef struct HashTable { int size。 unsigned int (*hashFunction)(void *)。 int (*equalFunction)(void*, void*)。 HashBucketEntry **buckets。 } HashTable; //我們有一個Hashtable *dictionary.。 void processInput() { //char c; int c。 int i = 0; //char * word = (char *) malloc(60 * sizeof(char)); char word[60] 。 while (c = getchar() ) { if (isalpha(c)) { word[i] = c; i ; } else { word[i] = ''/span>; if (word[0] != ' ') { //char * copy = (char *) malloc(60 * sizeof(char)); char copy[60] 。 strcpy(copy, word)。 unsigned int location = (dictionary->hashFunction)(copy) % (dictionary->size); char * word_in_dict; if (dictionary->buckets[location] != NULL) { word_in_dict = (char *) dictionary-> buckets[location]-> data; } else { word_in_dict = NULL; } char copy2[60] 。 copy2[0] = toupper(copy[0] )。 for(int i = 1; copy[i]; i ){ copy2[i] = tolower(copy[i])。 } unsigned int location2 = (dictionary->hashFunction)(copy2) % (dictionary->size)。 char * word_in_dict2; if (dictionary->buckets[location2] != NULL) { /somehow this is NULL when IPSUM, even though copy2 has correct string. word_in_dict2 = (char *) dictionary-> buckets[location2]-> data; } else { word_in_dict2 = NULL; } char copy3[60] 。 for(int i = 0; copy[i]; i ){ copy3[i] = tolower(copy[i])。 } unsigned int location3 = (dictionary->hashFunction)(copy3) % (dictionary->size)。 char * word_in_dict3; if (dictionary->buckets[location3] != NULL) { word_in_dict3 = (char *) dictionary-> buckets[location3]-> data; } else { word_in_dict3 = NULL; } if (word_in_dict != NULL) { fprintf(stdout, "%s"/span>, word_in_dict)。 } else if (word_in_dict2 != NULL) { fprintf(stdout, "%s"/span>, word_in_dict2); } else if (word_in_dict3 != NULL) { fprintf(stdout, "%s"/span>, word_in_dict3) 。 } else { /fprintf(stdout, "%s", copy); printf("%s"/span>, copy); } putchar(c)。 i = 0; } else if (c != EOF) { putchar(c)。 } else { break; } } }字典中只有這些條目:
ipsum i%#@! fubar fubar IpSum XXXXX24 Ipsum YYYYY211如果有任何幫助,我們將不勝感激!
更新回應。
針對答案的更新。 我把copy2的代碼改成了這樣:
for(j = 1; j < strlen(copy); j ) { if (j < sizeof(copy2)) { copy2[j] = tolower(copy[j])。 } }(并對copy3做了類似的事情)。第二種情況下可以作業,但現在第三種情況下卻失敗了;只有當我改變第二種情況時,事情似乎才會成功,但第三種情況卻不能。有人知道為什么會出現這種情況嗎?
uj5u.com熱心網友回復:
你的代碼創建你的輸入字串的修改副本,例如:
你的代碼創建你的輸入字串的修改副本。
char copy2[60] 。 copy2[0] = toupper(copy[0] )。 for(int i = 1; copy[i]; i ){ copy2[i] = tolower(copy[i])。 }不復制終止的
''/code>。由于自動變數沒有被隱式初始化,相應的記憶體可能包含任何資料(來自先前的回圈周期或來自不相關的代碼),這些資料可能以尾部字符的形式出現。你必須在你的字串的最后一個字符后附加一個''字符。如果在陣列邊界內沒有
'',當你作為一個字串訪問陣列時,這個錯誤可能導致對陣列的越界訪問。(未定義的行為)如果輸入的字串太長,你的代碼本身可能會導致越界訪問。你應該在
i >= sizeof(copy2)處添加一個檢查來防止對陣列元素的訪問。我建議像這樣:
char copy2[60] 。 copy2[0] = toupper(copy[0] )。 /* 避免讀過一個空字串的末尾 */ if(copy[0] ) { for(int i = 1; copy[i] && (i < sizeof(copy)-1); i ){ copy2[i] = tolower(copy[i])。 } /* variable i will already be incremented here */ copy2[i] = ''。 }轉載請註明出處,本文鏈接:https://www.uj5u.com/net/322432.html
標籤:
上一篇:C語言中變數的范圍