新編碼器在這里。一段時間以來,我一直試圖在一個非常基于 Java 的網站上使用 Selenium抓取一段文本。不知道我在這一點上做錯了什么。
from selenium import webdriver
driver = webdriver.Chrome()
driver.get("https://explorer.helium.com/accounts/13pm9juR7WPjAf7EVWgq5EQAaRTppu2EE7ReuEL9jpkHQMJCjn9")
earnings = driver.find_elements_by_class_name('text-base text-gray-600 mb-1 tracking-tight w-full break-all')
print(earnings)
driver.quit()
嘗試刮取的元素的影像:
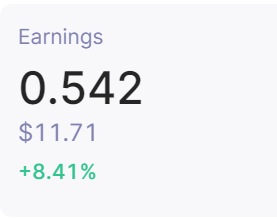
我正在嘗試從這個容器中提取美元金額,以便我最終可以在我正在構建的每日報告中使用它。
我嘗試過的一切都導致它沒有回傳。即使我嘗試從該元素中獲取文本。
這是網站鏈接:https : //explorer.helium.com/accounts/13pm9juR7WPjAf7EVWgq5EQAaRTppu2EE7ReuEL9jpkHQMJCjn9
uj5u.com熱心網友回復:
您應該等到 javascript 加載、頁面加載、元素加載。
_ = driver.Manage().Timeouts().ImplicitWait;
您可以創建條件,直到元素出現。
ExpectedConditions ...... define selenium conditions
//This is how we specify the condition to wait on.
wait.until(ExpectedConditions.alertIsPresent());
您可以使用 XPATH !美元 XPATH 是
/html/body/div[1]/div/article/div[2]/div/div[2]/div/div[2]/div[1]/div[2]/div[2]
Firefox XPATH 查找器
https://addons.mozilla.org/en-US/firefox/addon/xpath_finder/
uj5u.com熱心網友回復:
你可以使用這個 xpath
//*[@id="app"]/article/div[2]/div/div[2]/div/div[2]/div[3]/div[1]/div[1]/div[3]
轉載請註明出處,本文鏈接:https://www.uj5u.com/net/324941.html
上一篇:不能讓硒找到元素