我有一個這樣的資料框架。
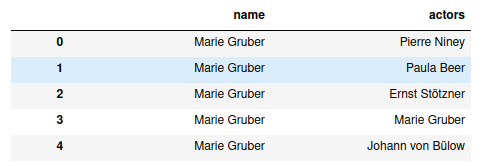
而CSV檔案中的資料集是這里。
。這個資料是從IMDb資料集中提取的。 但我有一個問題,我無法洗掉在同一行中重復出現的演員名字,例如在第4行中,我想在名字和演員欄中洗掉'Marie Gruber'。 我試著使用應用和所有條件,但代碼總是認為它是一樣的。 像這樣的代碼:
data[data['name'] != data['actors'] ]
uj5u.com熱心網友回復:
actors列有三個空格,所以首先通過Series.str.strip洗掉它們:
data['actors'] = data['actors'].str. strip()
data[data['name'] != data['actors']]
或者在read_csv中使用skipinitialspace=True:
data = pd.read_csv(file, skipinitialspace=True)
data[data['name'] != data['ctors']]
uj5u.com熱心網友回復:
使用pandas.dataframe.drop函式。
data.drop(data[data. apply(lambda x: x['name'] in x['actors'], axis = 1) ].index)
轉載請註明出處,本文鏈接:https://www.uj5u.com/net/326398.html
標籤:
上一篇:覆寫Dockerfile中的入口,而不使用"dockerrun"命令
下一篇:Pyspark-歸一化資料框架