概括:
在具有特定目錄輸入的 shell 腳本中宣告 spark 提交(python 腳本)的預期令牌是什么?我應該使用什么標點符號?
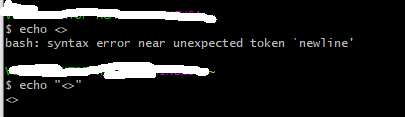
我已經嘗試過了<,但它不起作用
細節:
我盡量詳細說明我的情況,以了解我的情況。我的輸入是
sys.argv[1]對于dataset_1, dataset_2,dataset_3
sys.argv[2] 為了 dataset_4
sys.argv[3] 為了 dataset_5
sys.argv[4] 為了 dataset_6
我的輸出
sys.argv[5]
額外輸入
sys.argv[6] 一年
sys.argv[7] 一個月
這是腳本的一部分,檔案名是 cs_preDeploy.py
import os
import sys
#/tmp/sdsid/encrypted_dataset/ae80ead7-bcf1-43ca-a888-03f6ba48f4b9/0/dataset_1/year=2021/month=1
input_path_1 = os.path.join(sys.argv[1], 'dataset_1')
#/tmp/sdsid/encrypted_dataset/ae80ead7-bcf1-43ca-a888-03f6ba48f4b9/0/dataset_2/year=2021/month=1
input_path_2 = os.path.join(sys.argv[1], 'dataset_2')
#/tmp/sdsid/encrypted_dataset/ae80ead7-bcf1-43ca-a888-03f6ba48f4b9/0/dataset_3/year=2021/month=1
input_path_3 = os.path.join(sys.argv[1], 'dataset_3')
# /tmp/sdsid/encrypted_dataset/328b7446-1862-4489-b1b4-57fa55fe556a/0/dataset_4/year=2021/month=2
input_path_4 = os.path.join(sys.argv[2], 'dataset_4')
# /tmp/sdsid/encrypted_dataset/3119bdd9-c7a8-44c3-b3f8-e49a86261106/0/dataset_5/year=2021/month=2
input_path_5 = os.path.join(sys.argv[3], 'dataset_5')
# /tmp/sdsid/encrypted_dataset/efc84a0f-52e9-4dff-91a1-56e1d7aa02cb/0/dataset_6/year=2021/month=2
input_path_6 = os.path.join(sys.argv[4], 'dataset_6')
output_path = sys.argv[5]
#query_year = sys.argv[6]
#query_month = sys.argv[7]
#For looping year month
if len(sys.argv) > 7:
year = int(sys.argv[6]) # year
month = int(sys.argv[7]) # month
else:
month_obs = datetime.datetime.today()
month = month_obs.month
year = month_obs.year
這是我的第一次嘗試
[sdsid@user algorithm]$ PYSPARK_PYTHON=/usr/bin/python3 ./bin/spark-submit \
> --master yarn \
> --deploy-mode cluster \
> --driver-memory 16g \
> --executor-memory 16g \
> --num-executors 5 \
> --executor-cores 1 \
> ./home/sdsid/algorithm/cs_preDeploy.py
輸出
-bash: ./bin/spark-submit: No such file or directory
這是第二次嘗試,我將年份引數設定sys.argv[6]為 2021 和sys.argv[7]7(7 月)
[sdsid@user algorithm]$ nohup spark-sumbit cs_preDeploy.py </tmp/sdsid/sample_dataset/></tmp/sdsid/sample_dataset/dataset_4></tmp/sdsid/sample_dataset/dataset_5></tmp/sdsid/sample_dataset/dataset_6></tmp/sdsid/sample_output/dataset_output/> 2021 7
錯誤資訊
-bash: syntax error near unexpected token `<'
第三次嘗試
[sdsid@user algorithm]$ nohup spark-sumbit cs_preDeploy.py <"/tmp/sdsid/sample_dataset/"><"/tmp/sdsid/sample_dataset/dataset_4"><"/tmp/sdsid/sample_dataset/dataset_5"><"/tmp/sdsid/sample_dataset/dataset_6"><"/tmp/sdsid/sample_output/dataset_output/"> 2021 7
錯誤資訊
-bash: syntax error near unexpected token `<'
uj5u.com熱心網友回復:
-bash: ./bin/spark-submit: No such file or directory
一種。在這里放置完整路徑,如 /folder1/folder2/bin/spark-submit as as as as ./ 表示當前目錄,并且取決于您現在所在的位置,此類路徑可能不存在。b.或將 spark submit 添加到
 “
“請參考如何提交應用程式以運行py spark的鏈接,這里有很多示例
轉載請註明出處,本文鏈接:https://www.uj5u.com/net/328573.html
標籤:Python 猛击 贝壳 阿帕奇火花 hadoop纱线
上一篇:未決議Bash腳本引數