假設我們有一個使用以下代碼生成的資料框:
import pandas as pd
d = {'p1': np.random.rand(32),
'a1': np.random.rand(32),
'phase': [0,0,0,0, 1,1,1,1, 2,2,2,2, 3,3,3,3, 0,0,0,0, 1,1,1,1, 2,2,2,2, 3,3,3,3],
'file_number': [1,1,1,1, 1,1,1,1, 1,1,1,1, 1,1,1,1, 2,2,2,2, 2,2,2,2, 2,2,2,2, 2,2,2,2]
}
df = pd.DataFrame(d)
對于每個檔案編號,我只想取第 3 階段的最后 N 行。因此 N==2 的結果如下所示:
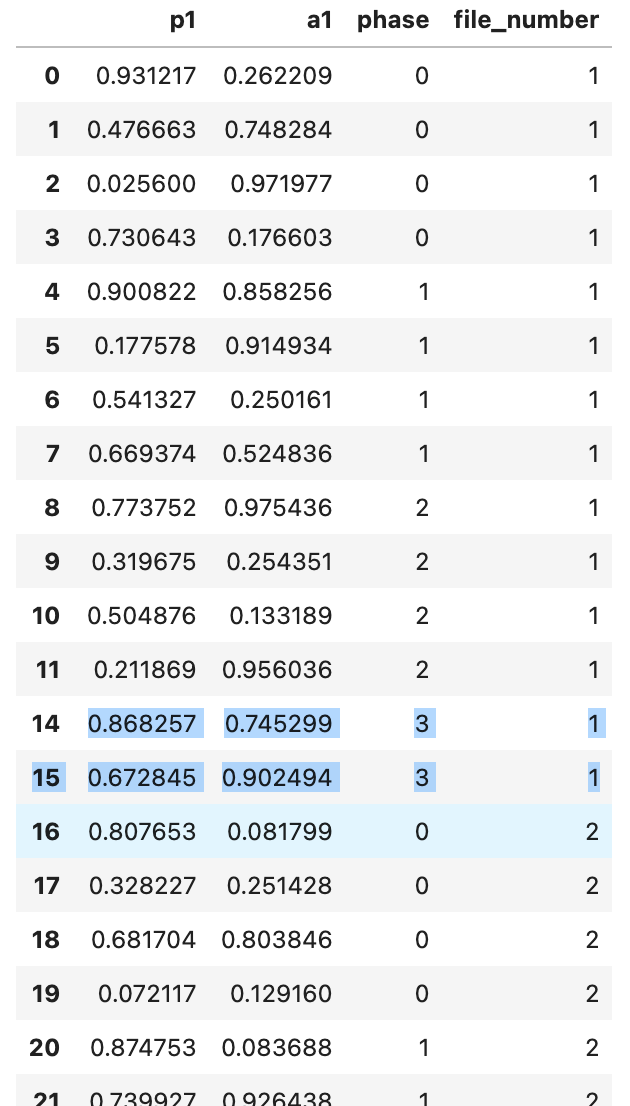
目前我是這樣做的:
def phase_3_last_n_observations(df, n):
result = []
for fn in df['file_number'].unique():
file_df = df[df['file_number']==fn]
for phase in [0,1,2,3]:
phase_df = file_df[file_df['phase']==phase]
if phase == 3:
phase_df = phase_df[-n:]
result.append(phase_df)
df = pd.concat(result, axis=0)
return df
phase_3_last_n_observations(df, 2)
但是,它非常慢,而且我有 TB 的資料,所以我需要擔心性能。有誰知道如何加快我的解決方案?謝謝!
uj5u.com熱心網友回復:
我使用的想法已洗掉的答案-獲得由以前的行指數相匹配的行3通過GroupBy.cumcount并洗掉它們DataFrame.drop:
def phase_3_last_n_observations(df, N):
df1 = df[df['phase'].eq(3)]
idx = df1[df1.groupby('file_number').cumcount(ascending=False).ge(N)].index
return df.drop(idx)
#index is reseted for default, because used for remove rows
df = phase_3_last_n_observations(df.reset_index(drop=True), 2)
uj5u.com熱心網友回復:
過濾 phase 所在的行,3然后 groupby 并用于tail選擇 per 的最后兩行file_number,最后append得到結果
m = df['phase'].eq(3)
df[~m].append(df[m].groupby('file_number').tail(2)).sort_index()
p1 a1 phase file_number
0 0.223906 0.164288 0 1
1 0.214081 0.748598 0 1
2 0.567702 0.226143 0 1
3 0.695458 0.567288 0 1
4 0.760710 0.127880 1 1
5 0.592913 0.397473 1 1
6 0.721191 0.572320 1 1
7 0.047981 0.153484 1 1
8 0.598202 0.203754 2 1
9 0.296797 0.614071 2 1
10 0.961616 0.105837 2 1
11 0.237614 0.640263 2 1
14 0.500415 0.220355 3 1
15 0.968630 0.351404 3 1
16 0.065283 0.595144 0 2
17 0.308802 0.164214 0 2
18 0.668811 0.826478 0 2
19 0.888497 0.186267 0 2
20 0.199129 0.241900 1 2
21 0.345185 0.220940 1 2
22 0.389895 0.761068 1 2
23 0.343100 0.582458 1 2
24 0.182792 0.245551 2 2
25 0.503181 0.894517 2 2
26 0.144294 0.351350 2 2
27 0.157116 0.847499 2 2
30 0.194274 0.143037 3 2
31 0.542183 0.060485 3 2
uj5u.com熱心網友回復:
作為已經存在的替代解決方案:您可以計算所有相組的最后一個元素,然后僅用于.loc獲得所需的組結果。我已經為 撰寫了代碼N==2,如果需要N==3,請使用[-1, -2, -3]
result = df.groupby(['phase']).nth([-1, -2])
PHASE = 3
result.loc[PHASE]
轉載請註明出處,本文鏈接:https://www.uj5u.com/net/329051.html