我在繪制多個水平條形圖的總y軸范圍時遇到了問題,要讓所有的值彼此對齊,并且只讓最左邊的圖上的y標簽可見。 我有下面的資料框架(資料),我使用pd.Grouper函式在開始創建我的圖和軸之前按時間間隔分組。 因為我使用的是資料框架,所以我給我創建的每個軸分配了一個圖。 這段代碼不能正確繪制數值。 如果我去掉sharey=y,那么每個圖都能正確顯示,但當然不能對準一個共同的y軸。
import pandas as pd
import matplotlib.pyplot as plt
#group by time interval[/span]。
data_gb = data.groupby([pd.Grouper(freq='1min')] )
#創建并設定原始資料框架的y軸范圍限制。
custom_ylim = (data.price.min(), data.price.max()
#number of plots based on number of intervals[/span].
numplot = len(data_gb)
# 創建一個軸名的元組,似乎是一個黑客。
axes = tuple(['ax'/span> str(n) for n in range(1, numplot 1) ])
f, axes = plt.subplots(1, numplot, sharey= True, sharex=True)
#iterate and assign plot to each axes[/span].
for (t, prices), ax in zip(data_gb, axes)。
ax.set_ylim(custom_ylim) #這似乎沒有任何作用。
prices.plot.barh(price', stacked=True, ax=ax)
plt.show()
時間戳 價格 colA colB colC colD
2021-09-08 13: 30: 00 00:00 11。 00 0.0 140037.0 0.0 0.0
2021-09-08 13:30。 00 00:00 11。 01 21963.0 34732.0 2961.0 1190.0 >。
2021-09-08 13: 30: 00 00:00 11。 02 17578.0 15434.0 12309.0 2.
2021-09-08 13:30。 00 00:00 11。 03 2493.0 12393.0 11229.0 907.0 >。
2021-09-08 13:30。 00 00:00 11。 04 17240.0 16406.0 1479.0 100.0
... ... ... ... ... ... ... ...。
2021-09-08 13:31。 00 00:00 11。 01 8520.0 22579.0 4031.0 248.0
2021-09-08 13: 31: 00 00:00 11。 02 64626.0 10330.0 11340.0 3862.02021-09-08 13:31。 00 00:00 11。 03 10967.0 5144.0 2621.0 640.0 >。
2021-09-08 13:31。 00 00:00 11。 04 15168.0 2907.0 0.0 4.0
2021-09-08 13: 31: 00 00:00 11。 05 1279.0 0.0 0.0 0.0
不正確地繪制。
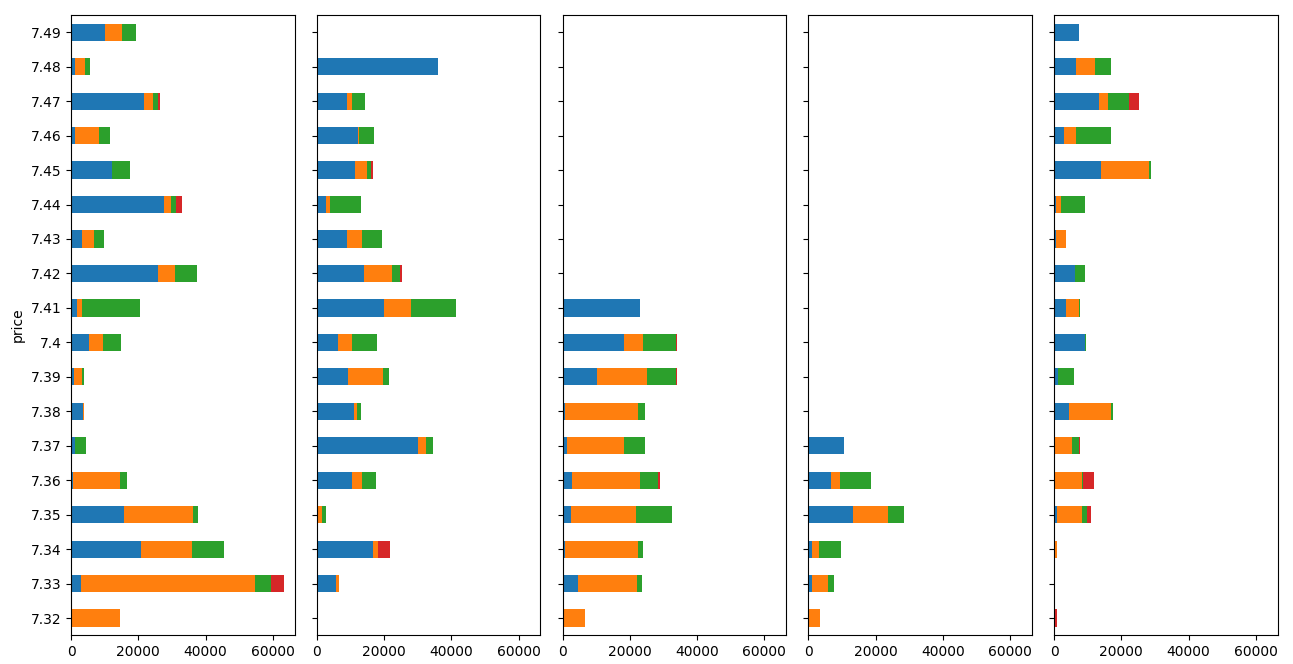
繪制的個體沒有共享Y軸。你可以看到第一個圖形在前面的繪圖中缺少數值。
uj5u.com熱心網友回復:
Pandas的條形圖繪制并不總是直觀地作業。這使得共享坐標軸變得相當復雜。一個問題是,條形圖并沒有得到一個數字或純分類的刻度線位置。相反,條形圖被編號為0,1,2,...,之后的刻度線會得到它們的標簽。
另一個問題是,數字列的條形圖可能會被奇怪地轉換為字串(例如,一個值12.34可能被顯示為12.340000001,這是由于一些浮點的怪異現象)。一些奇怪的現象在你的圖中是可見的,例如7.4被顯示而不是7.40。
我提出的解決方法是:
- 將價格欄轉換為小數點后2位的字串 。
- 在繪圖時,將價格設定為索引,并重新索引到完整的價格范圍;這使得所有的子圖都得到這個相同的范圍 。
- 令人討厭的是,在將列轉換為字串之前,需要計算完整的價格范圍,然后也需要將該范圍轉換為字串 。
from matplotlib import pyplotas plt
import pandas as pd
import numpy as np
#創建一些測驗資料
times = np.repeat(pd.date_range('2021-09-08 13:30'/span>, '2021-09-08 13:34'/span>, freq='1min'/span>), 20)
data = pd.DataFrame({'timestamp': times,
'price': np.round(np.arrange(1100, 1200) / 100 - np.repear([0, 0.25, 0。 5, 0.55, 0.9], 20), 2)。)
'colA': np.random.randint(1000, 5000, 100) 。
'colB': np.random.randint(1000, 5000, 100),
'colC': np.random.randint(1000, 5000, 100),
'colD': np.random.randint(1000, 5000, 100)}).set_index('timestamp')
# 計算全部價格范圍,首先是數字,然后轉換為字串。
full_price_range = [f'{x:. 2f}' for x in np.range(data['price']]。 min(), data['price'].max() 0.0001, 0.01) ]
# 現在將價格列轉換為字串。
data['price'] = data['price'].apply(lambda x: f'{x:.2f}')
data_gb = data.groupby([pd.Grouper(freq='1min')])
numplot = len(data_gb)
fig, axes = plt. subplots(1, numplot, sharey=True, sharex=True, figsize=(12, 4)
for (t, prices), ax in zip(data_gb, axes)。
prices.set_index('price').reindex(full_price_range).plot.barh(stacked=True, legend=False, ax=ax)
ax.set_title(t)
fig.tight_layout()
plt.show()
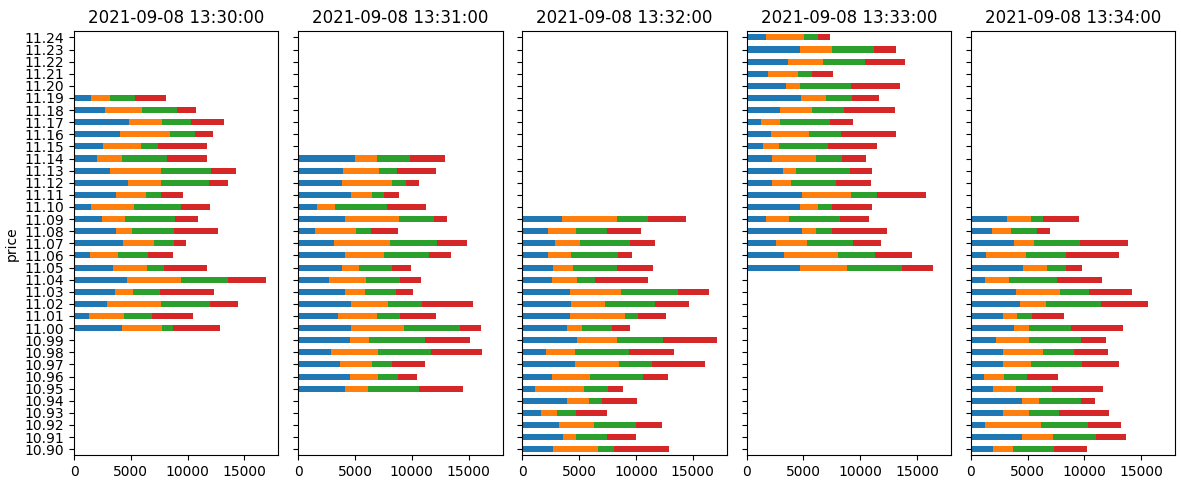
注意,原代碼中的axes = tuple(....)一行沒有任何作用,因為在下一行中,名為axes的變數得到了一個新值。
轉載請註明出處,本文鏈接:https://www.uj5u.com/net/329074.html
標籤:
下一篇:三維散點圖上的誤差條,點的陣列