我正試圖從一個網站中提取資料。該網頁有不止一個頁面,所以我試圖使用一個回圈來迭代不同的頁面。然而,這個問題是我無法從下一個按鈕中獲得href。
誰能解釋一下我如何才能解決這個問題?
import csv
from datetime import datetime
import requests
from bs4 import BeautifulSoup
def get_url(position, location)。
"從定位和位置生成一個URL"。
模板 = 'https://mx.indeed.com/jobs?q={}&l={}'/span>
url = template.format(position, location)
returnurl
def get_record(card)。
spantag = card.h2.span
job_title = spantag.get('title')
job_url = 'https://www.indeed.com' card.get('href')
公司 = card.find('span', 'companyName').text
job_location = card.find('div', 'companyLocation').text
job_summary = card.find('div', 'job-snippet').text.strip()
post_date = card.find('span', 'date').text
today = datetime.day().strftime('%Y-%m-%d')
記錄 = (job_title, company, job_location, post_date, today, job_summary, job_url)
return 記錄
def main(position, location)。
記錄 = []
url = get_url(position, location)
while True:
回應 = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
cards = soup.find_all('a', 'tapItem')
for card in cards:
記錄 = get_record(card)
records.append(record)
try:
url = 'https://mx.indeed.com' soup. find('a', {'ria-label':'Siguiente" '}).get('href')
except AttributeError:
break
with open('results_Indeed')。 csv', 'w', newline = ', encoding = 'utf-8') as f.
writer = csv.writer(f)
作家。 writerow(['JobTitle'/span>, 'Comany'/span>, 'Location'/span>, 'PostDate', 'Date', 'Summary', 'URL'] )
writer.writerows(records)
uj5u.com熱心網友回復:
嘗試CSS選擇器[aria-label*="Siguiente"]來搜索下一個URL:
import requests
import pandas as pd
from datetime import datetime
from bs4 import BeautifulSoup
def get_url(position, location)。
"從定位和位置生成一個URL"。
模板 = "https://mx.indeed.com/jobs?q={}&l={}"。
url = template.format(position, location)
returnurl
def get_record(card)。
spantag = card.h2.span
job_title = spantag.get("title")
job_url = "https://www.indeed.com" card.get("href")
公司 = card.find("span", "companyName").text
job_location = card.find("div", "companyLocation").text
job_summary = card.find("div", "job-snippet").text.strip()
post_date = card.find("span", "date").text
today = datetime.today().strftime("%Y-%m-%d"/span>)
記錄 = (
job_title,
公司。
job_location,
post_date,
今天。
job_summary,
job_url,
)
return記錄
def main(position, location)。
記錄 = []
url = get_url(position, location)
while True:
print(url)
回應 = requests.get(url)
soup = BeautifulSoup(response.text, "html.parser")
cards = soup.find_all("a"/span>, "tapItem")
for card in cards:
記錄 = get_record(card)
records.append(record)
url = soup.select_one('[ria-label*="Siguiente"]'/span>)
if not url:
break
url = "https://mx.indeed.com"/span> url["href"/span>]
df = pd.DataFrame(
記錄。
列=[
"JobTitle",
"Comany",
"Location",
"PostDate"。
"日期"。
"摘要"。
"URL"。
],
)
print(df)
df.to_csv("data.csv", index=False)
main("Python", "Monterrey")
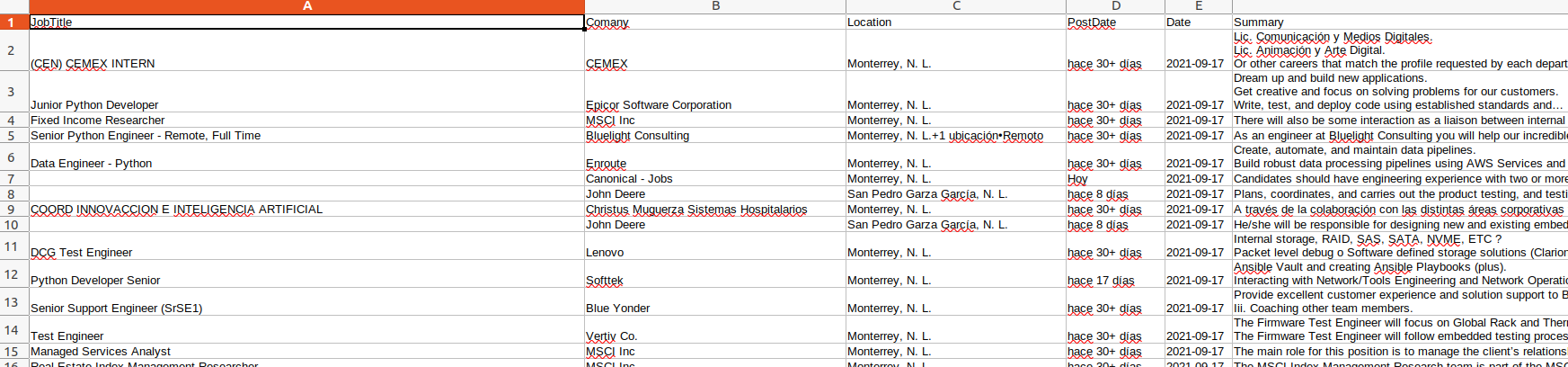
創建data.csv(LibreOffice的截圖):
uj5u.com熱心網友回復:
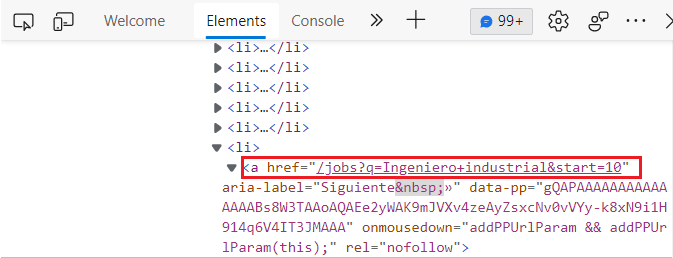
頁面底部的按鈕被排序為一個串列,href是串列項的一個子項,你可以在下面的螢屏截圖中看到。
然而,我建議另一種方法:嘗試使用mechanize。這是一個非常簡單易用的庫,可以讓你像使用瀏覽器一樣操作網頁。有了這個庫,你可以直接模擬點擊next按鈕,而不需要抓取其鏈接地址。
轉載請註明出處,本文鏈接:https://www.uj5u.com/net/331297.html
標籤:
下一篇:直方圖均衡化給了我全黑的影像