我有這四個串列,它們是影像的檔案名,檔案名的格式為:
(疾病)-(隨機患者 ID)-(該患者的影像編號)
單個患者對于每種疾病可以有多個影像。
請參閱下面的這些切片:
print(train_cnv_list[0:3])
print(train_dme_list[0:3])
print(train_drusen_list[0:3])
print(train_normal_list[0:3])
>>>
['CNV-9911627-77.jpeg', 'CNV-9935363-45.jpeg', 'CNV-9911627-94.jpeg']
['DME-8889850-2.jpeg', 'DME-8773471-3.jpeg', 'DME-8797076-11.jpeg']
['DRUSEN-8986660-50.jpeg', 'DRUSEN-9100857-3.jpeg', 'DRUSEN-9025088-5.jpeg']
['NORMAL-9490249-31.jpeg', 'NORMAL-9509694-5.jpeg', 'NORMAL-9504376-3.jpeg']
我想弄清楚:
- 每個患者/每個串列有多少影像?
- 四個串列中的“隨機患者 ID”是否有重疊?如果是這樣,我可以使用 groupby 之類的東西將其匯總為某種報告(患者、疾病、影像數量)嗎?
patient - disease1 - total number of images
- disease2 - total number of images
- disease3 - total number of images
其中影像總數為最大值(該患者的影像數)
我確實看到這會產生一個患者 ID:
train_cnv_list[0][4:11]
>>> 9911627
提前感謝您的任何指導。
uj5u.com熱心網友回復:
您可以使用 Pandas 輕松完成:
import pandas as pd
cnv_list=['CNV-9911627-77.jpeg', 'CNV-9935363-45.jpeg', 'CNV-9911627-94.jpeg']
dme_list=['DME-8889850-2.jpeg', 'DME-8773471-3.jpeg', 'DME-8797076-11.jpeg']
dru_list=['DRUSEN-8986660-50.jpeg', 'DRUSEN-9100857-3.jpeg', 'DRUSEN-9025088-5.jpeg']
nor_list=['NORMAL-9490249-31.jpeg', 'NORMAL-9509694-5.jpeg', 'NORMAL-9504376-3.jpeg']
data =[]
data.extend(cnv_list)
data.extend(dme_list)
data.extend(dru_list)
data.extend(nor_list)
df = pd.DataFrame(data, columns=["files"])
df["files"]=df["files"].str.replace ('.jpeg','')
df=df["files"].str.split('-', expand=True).rename(columns={0:"disease",1:"PatientID",2:"pictureName"})
res = df.groupby(['PatientID','disease']).apply(lambda x: x['pictureName'].count())
print(res)
結果:
PatientID disease
8773471 DME 1
8797076 DME 1
8889850 DME 1
8986660 DRUSEN 1
9025088 DRUSEN 1
9100857 DRUSEN 1
9490249 NORMAL 1
9504376 NORMAL 1
9509694 NORMAL 1
9911627 CNV 2
9935363 CNV 1
甚至現在比你擁有一個資料幀還要多......
uj5u.com熱心網友回復:
這里有一些函式可能會讓你走上正軌,但正如@rick-supports-monica 所提到的,這是 Pandas 的一個很好的用例。您將更輕松地處理資料。
def contains_duplicate_ids(img_list):
patient_ids = []
for image in img_list:
patient_id = image.split('.')[0].split('-')[1]
patient_ids.append(patient_id)
if len(set(patient_ids)) == len(patient_ids):
return False
return True
def get_duplicates(img_list):
patient_ids = []
duplicates = []
for image in img_list:
patient_id = image.split('.')[0].split('-')[1]
if patient_id in patient_ids:
duplicates.append(patient_id)
patient_ids.append(patient_id)
return duplicates
def count_images(img_list):
return len(set(img_list))
從get_duplicates你可以使用任何你從那里要回查找病人的ID。我不確定我是否完全理解串列的結構。看起來像{disease}-{patient_id}-{some_other_int}.jpg。我不確定如何在不了解輸入的情況下向功能添加額外的查找。
我提到了熊貓,但沒有提到如何使用它,這是一種將現有資料放入資料框的方法:
import pandas as pd
# Sample data
train_cnv_list = ['CNV-9911627-77.jpeg', 'CNV-9935363-45.jpeg', 'CNV-9911628-94.jpeg', 'CNM-9911629-94.jpeg']
train_dme_list = ['DME-8889850-2.jpeg', 'DME-8773471-3.jpeg', 'DME-8797076-11.jpeg']
train_drusen_list = ['DRUSEN-8986660-50.jpeg', 'DRUSEN-9100857-3.jpeg', 'DRUSEN-9025088-5.jpeg']
train_normal_list = ['NORMAL-9490249-31.jpeg', 'NORMAL-9509694-5.jpeg', 'NORMAL-9504376-3.jpeg']
# Convert list to dataframe
def dataframe_from_list(img_list):
df = pd.DataFrame(img_list, columns=['filename'])
df['disease'] = [filename.split('.')[0].split('-')[0] for filename in img_list]
df['patient_id'] = [filename.split('.')[0].split('-')[1] for filename in img_list]
df['some_other_int'] = [filename.split('.')[0].split('-')[2] for filename in img_list]
return df
# Generate a dataframe for each list
cnv_df = dataframe_from_list(train_cnv_list)
dme_df = dataframe_from_list(train_dme_list)
drusen_df = dataframe_from_list(train_drusen_list)
normal_df = dataframe_from_list(train_normal_list)
# or combine them into one long dataframe
df = pd.concat([cnv_df, dme_df, drusen_df, normal_df], ignore_index=True)
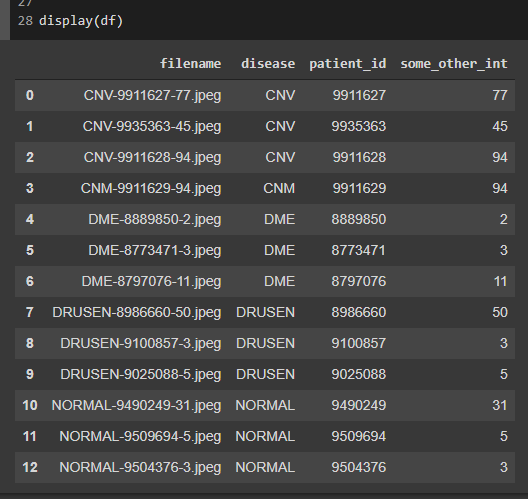
uj5u.com熱心網友回復:
首先創建一個定義良好的資料結構,使用 counter 來回答你的第一個問題。
from typing import NamedTuple
from collections import Counter,defaultdict
class FileInfo(NamedTuple):
disease:str
patient_id:str
image_id: str
l1 = ['CNV-9911627-77.jpeg', 'CNV-9935363-45.jpeg', 'CNV-9911627-94.jpeg']
l2 = ['DME-8889850-2.jpeg', 'DME-8773471-3.jpeg', 'DME-8797076-11.jpeg']
l3 = ['DRUSEN-8986660-50.jpeg', 'DRUSEN-9100857-3.jpeg', 'DRUSEN-9025088-5.jpeg']
l4 = ['NORMAL-9490249-31.jpeg', 'NORMAL-9509694-5.jpeg', 'NORMAL-9504376-3.jpeg']
lists = [l1,l2,l3,l4]
data_lists = []
for l in lists:
data_lists.append([FileInfo(*f[:-5].split('-')) for f in l])
counters = []
for l in data_lists:
counters.append(Counter(fi.patient_id for fi in l))
print(counters)
print('-----------')
cross_lists_data = dict()
for l in data_lists:
for file_info in l:
if file_info.patient_id not in cross_lists_data:
cross_lists_data[file_info.patient_id] = defaultdict(int)
cross_lists_data[file_info.patient_id][file_info.disease] = 1
print(cross_lists_data)
uj5u.com熱心網友回復:
首先連接您的資料
import pandas as pd
import numpy as np
train_cnv_list = ['CNV-9911627-77.jpeg', 'CNV-9935363-45.jpeg', 'CNV-9911627-94.jpeg']
train_dme_list = ['DME-8889850-2.jpeg', 'DME-8773471-3.jpeg', 'DME-8797076-11.jpeg']
train_drusen_list = ['DRUSEN-8986660-50.jpeg', 'DRUSEN-9100857-3.jpeg', 'DRUSEN-9025088-5.jpeg']
train_normal_list = ['NORMAL-9490249-31.jpeg', 'NORMAL-9509694-5.jpeg', 'NORMAL-9504376-3.jpeg']
train_data = np.array([
train_cnv_list,
train_dme_list,
train_drusen_list,
train_normal_list
])
使用扁平陣列創建一個系列
>>> train = pd.Series(train_data.flat)
>>> train
0 CNV-9911627-77.jpeg
1 CNV-9935363-45.jpeg
2 CNV-9911627-94.jpeg
3 DME-8889850-2.jpeg
4 DME-8773471-3.jpeg
5 DME-8797076-11.jpeg
6 DRUSEN-8986660-50.jpeg
7 DRUSEN-9100857-3.jpeg
8 DRUSEN-9025088-5.jpeg
9 NORMAL-9490249-31.jpeg
10 NORMAL-9509694-5.jpeg
11 NORMAL-9504376-3.jpeg
dtype: object
使用Series.str.extract與正則運算式一起提取檔案名的資訊,并將其分成不同的列
>>> pat = '(?P<Disease>\w )-(?P<Patient_ID>\d )-(?P<IMG_ID>\d ).jpeg'
>>> train = train.str.extract(pat)
>>> train
Disease Patient_ID IMG_ID
0 CNV 9911627 77
1 CNV 9935363 45
2 CNV 9911627 94
3 DME 8889850 2
4 DME 8773471 3
5 DME 8797076 11
6 DRUSEN 8986660 50
7 DRUSEN 9100857 3
8 DRUSEN 9025088 5
9 NORMAL 9490249 31
10 NORMAL 9509694 5
11 NORMAL 9504376 3
最后,聚合資料并根據最大IMG_ID數量計算每組影像的總數。
>>> report = train.groupby(["Patient_ID","Disease"])['IMG_ID'].agg(Total_IMGs="max")
>>> report
Total_IMGs
Patient_ID Disease
8773471 DME 3
8797076 DME 11
8889850 DME 2
8986660 DRUSEN 50
9025088 DRUSEN 5
9100857 DRUSEN 3
9490249 NORMAL 31
9504376 NORMAL 3
9509694 NORMAL 5
9911627 CNV 94
9935363 CNV 45
轉載請註明出處,本文鏈接:https://www.uj5u.com/net/333955.html
上一篇:Pandas資料幀無效密鑰