我想過濾遵循數字順序的 2 個模式之間的所有行。例如,我如何過濾所有行 > 1st.7.1.* & < 1st.13.1.*
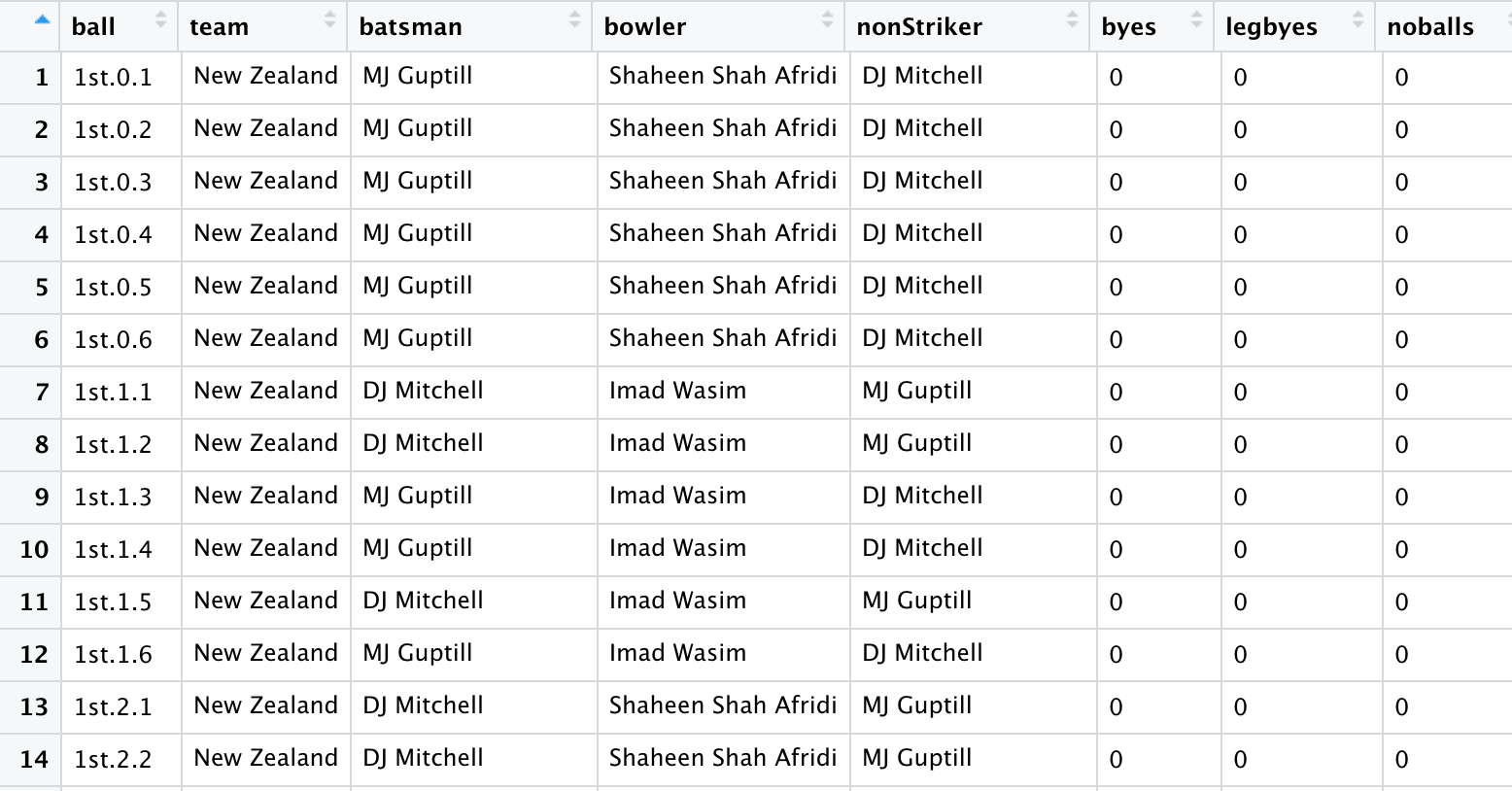
這是資料框的樣子
uj5u.com熱心網友回復:
我們可以parse_number用來獲取數字部分,然后執行filter
library(dplyr)
df1 %>%
filter(between(readr::parse_number(ball), 7.1, 13.1))
或者另一種選擇是提取子字串和 filter
library(stringr)
df1 %>%
filter(between(as.numeric(str_extract(ball, "\\d (\\.\\d )?$")), 7.1, 13.1))
-輸出
# A tibble: 61 × 2
ball team
<chr> <chr>
1 1st.7.1 New Zealand
2 1st.7.2 New Zealand
3 1st.7.3 New Zealand
4 1st.7.4 New Zealand
5 1st.7.5 New Zealand
6 1st.7.6 New Zealand
7 1st.7.7 New Zealand
8 1st.7.8 New Zealand
9 1st.7.9 New Zealand
10 1st.8 New Zealand
# … with 51 more rows
資料
df1 <- tibble(ball = str_c('1st.', seq(0.1, 13.5, by = 0.1)), team = 'New Zealand')
uj5u.com熱心網友回復:
您可以在此提取數字部分和子集:
library(stringr)
df %>%
mutate(num = as.numeric(str_extract(ball, "(?<=st\\.).*"))) %>%
filter(num > 7.1 & num < 13.1) %>%
select(-num)
ball
1 1st.10.9
2 1st.12.7
資料:
df <- data.frame(
ball = c("1st.7.1","1st.7.9", "1st.12.7", "1st.13.1")
)
uj5u.com熱心網友回復:
我們可以洗掉常量1st.并使用數字。在這里,我更改了范圍以顯示對提供的資料的影響。
library(dplyr)
library(stringr)
df %>%
filter(between(as.numeric(stringr::str_remove(ball, "1st.")), 0.1, 1.1))
ball team batsman bowler nonStriker byes legbyes noballs
1 1st.0.1 New Zealand MJ Guptill Shaheen Shah Afridi DJ Mitchell 0 0 0
2 1st.0.2 New Zealand MJ Guptill Shaheen Shah Afridi DJ Mitchell 0 0 0
3 1st.0.3 New Zealand MJ Guptill Shaheen Shah Afridi DJ Mitchell 0 0 0
4 1st.0.4 New Zealand MJ Guptill Shaheen Shah Afridi DJ Mitchell 0 0 0
5 1st.0.5 New Zealand MJ Guptill Shaheen Shah Afridi DJ Mitchell 0 0 0
6 1st.0.6 New Zealand MJ Guptill Shaheen Shah Afridi DJ Mitchell 0 0 0
7 1st.1.1 New Zealand DJ Mitchell Imad Wasim MJ Guptill 0 0 0
structure(list(ball = c("1st.0.1", "1st.0.2", "1st.0.3", "1st.0.4",
"1st.0.5", "1st.0.6", "1st.1.1", "1st.1.2", "1st.1.3", "1st.1.4",
"1st.1.5", "1st.1.6", "1st.2.1", "1st.2.2"), team = c("New Zealand",
"New Zealand", "New Zealand", "New Zealand", "New Zealand", "New Zealand",
"New Zealand", "New Zealand", "New Zealand", "New Zealand", "New Zealand",
"New Zealand", "New Zealand", "New Zealand"), batsman = c("MJ Guptill",
"MJ Guptill", "MJ Guptill", "MJ Guptill", "MJ Guptill", "MJ Guptill",
"DJ Mitchell", "DJ Mitchell", "MJ Guptill", "MJ Guptill", "DJ Mitchell",
"MJ Guptill", "DJ Mitchell", "DJ Mitchell"), bowler = c("Shaheen Shah Afridi",
"Shaheen Shah Afridi", "Shaheen Shah Afridi", "Shaheen Shah Afridi",
"Shaheen Shah Afridi", "Shaheen Shah Afridi", "Imad Wasim", "Imad Wasim",
"Imad Wasim", "Imad Wasim", "Imad Wasim", "Imad Wasim", "Shaheen Shah Afridi",
"Shaheen Shah Afrid"), nonStriker = c("DJ Mitchell", "DJ Mitchell",
"DJ Mitchell", "DJ Mitchell", "DJ Mitchell", "DJ Mitchell", "MJ Guptill",
"MJ Guptill", "DJ Mitchell", "DJ Mitchell", "MJ Guptill", "DJ Mitchell",
"MJ Guptill", "MJ Guptill"), byes = c(0L, 0L, 0L, 0L, 0L, 0L,
0L, 0L, 0L, 0L, 0L, 0L, 0L, 0L), legbyes = c(0L, 0L, 0L, 0L,
0L, 0L, 0L, 0L, 0L, 0L, 0L, 0L, 0L, 0L), noballs = c(0L, 0L,
0L, 0L, 0L, 0L, 0L, 0L, 0L, 0L, 0L, 0L, 0L, 0L)), class = "data.frame", row.names = c(NA,
-14L))
轉載請註明出處,本文鏈接:https://www.uj5u.com/net/338640.html
上一篇:對R中的所有列按年應用運行平均值
下一篇:如何洗掉模態對話框上的關閉按鈕?