我有一個類似于下面的熊貓資料框。它包含 3 個識別符號,分為相應的月份(長度可以不同)、它們相應的值和布爾標志。對于每個識別符號,我需要取值直到看到第一個“1”(包括),以及其他變數。如果所有標志都是“0”,那么它將獲取該 ID 的所有行。
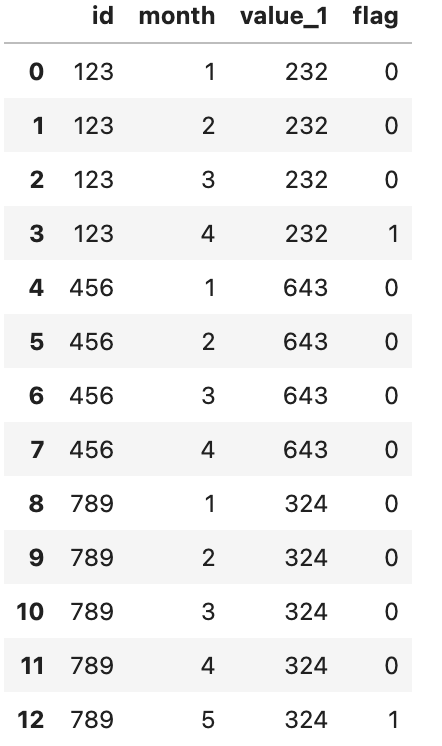
所需的輸出如下圖所示。
data = {'id':['123', '123', '123', '123', '123', '456', '456', '456', '456', '789', '789', '789', '789', '789', '789'],
'month':[1,2,3,4,5,1,2,3,4,1,2,3,4,5,6],
'value_1': [232,432,556,223,643,556,121,853,343,324,654,765,128,543,776],
'flag':[0,0,0,1,1,0,0,0,0,0,0,0,0,1,1]}
# Create DataFrame
d = pd.DataFrame(data)
我曾嘗試使用 groupby 進行轉換(如下所示)。對于值列,我只關心第一個值。但是,我希望所有月份都按相同的順序排列,這似乎用這種方法是不可能的。
temp = d['flag'].ne(1).cumsum()
grouped = d.groupby(temp).agg({'id': 'first',
'value_1': 'first',
'flag': lambda x: max(x)})
uj5u.com熱心網友回復:
IIUC,嘗試:
output = d[d.groupby("id")["flag"].transform(lambda x: x.shift().fillna(0).cumsum())==0]
output["value_1"] = output.groupby("id")["value_1"].transform("first")
>>> output
id month value_1 flag
0 123 1 232 0
1 123 2 232 0
2 123 3 232 0
3 123 4 232 1
5 456 1 556 0
6 456 2 556 0
7 456 3 556 0
8 456 4 556 0
9 789 1 324 0
10 789 2 324 0
11 789 3 324 0
12 789 4 324 0
13 789 5 324 1
轉載請註明出處,本文鏈接:https://www.uj5u.com/net/338744.html