我有一個包含許多周期的大型資料幀,每個周期內有 2 個最大峰值,我需要將其捕獲到另一個資料幀中。
我創建了一個示例資料框來模擬我看到的資料:
import pandas as pd
data = {'Cycle':[1,1,1,1,1,1,1,1,1,1,2,2,2,2,2,2,2,2,2,2,3,3,3,3,3,3,3,3,3,3], 'Pressure':[100,110,140,180,185,160,120,110,189,183,103,115,140,180,200,162,125,110,196,183,100,110,140,180,185,160,120,180,201,190]}
df = pd.DataFrame(data)
正如您在每個周期中看到的那樣,有兩個最大值,但我遇到問題的部分是第二個峰值通常高于第一個峰值,因此在技術上可能有一排數字高于周期中的其他峰值最大值。結果應該是這樣的:
data2 = {'Cycle':[1,1,2,2,3,3], 'Peak Maxs': [185,189,200,196,185,201]}
df2= pd.DataFrame(data2)
我已經嘗試了幾種方法,包括每個周期的 .nlargest(2),但問題是,由于其中一個峰值通常較高,它會拉出資料中的第二大數字,這不一定是另一個峰值。
該圖顯示了我希望能夠找到的每個周期的峰值壓力。
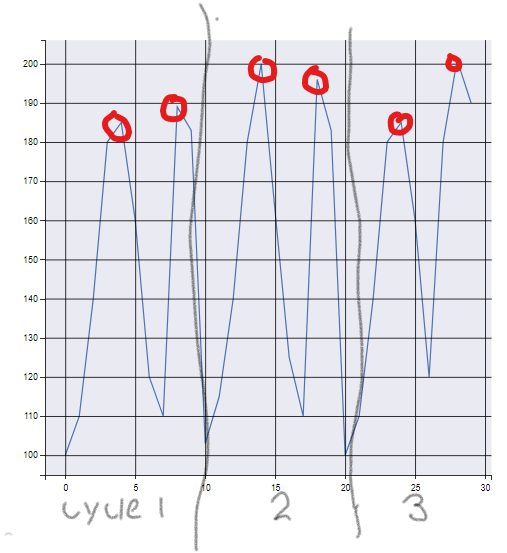
謝謝你的幫助。
uj5u.com熱心網友回復:
從 scipy argrelextrema
from scipy.signal import argrelextrema
out = df.groupby('Cycle')['Pressure'].apply(lambda x : x.iloc[argrelextrema(x.values, np.greater)])
Out[124]:
Cycle
1 4 185
8 189
2 14 200
18 196
3 24 185
28 201
Name: Pressure, dtype: int64
out = out.sort_values().groupby(level=0).tail(2).sort_index()
out
Out[138]:
Cycle
1 4 185
8 189
2 14 200
18 196
3 24 185
28 201
Name: Pressure, dtype: int64
uj5u.com熱心網友回復:
使用groupby().shift()得到鄰域值,然后進行比較:
g = df.groupby('Cycle')
local_maxes = (df['Pressure'].gt(g['Pressure'].shift()) # greater than previous row
& df['Pressure'].gt(g['Pressure'].shift(-1))] # greater than next row
)
df[local_maxes]
輸出:
Cycle Pressure
4 1 185
8 1 189
14 2 200
18 2 196
24 3 185
28 3 201
轉載請註明出處,本文鏈接:https://www.uj5u.com/net/340519.html
上一篇:使用組中的第一個值和條件創建新列(pandas、python、groupby)
下一篇:拆分pyspark資料框列