我有資料框,我想洗掉星號和本地化中的所有空行。我必須創建兩列“temp”和“word”。
“temp”包含第一個換行符之后的所有行,“word”列代表在“temp”中找到的此串列中的所有單詞:
words = ['SECTION 11', 'CONE', 'BELLY', 'FIXED PLAN']
我的輸入:
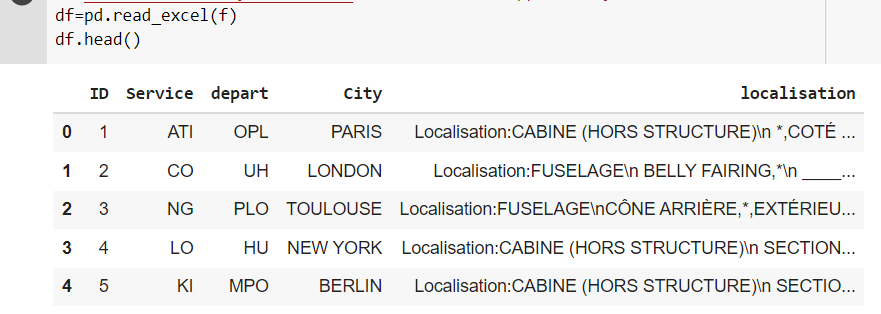
預期輸出:我必須在“單詞”列中用空替換星號:

我試試這個
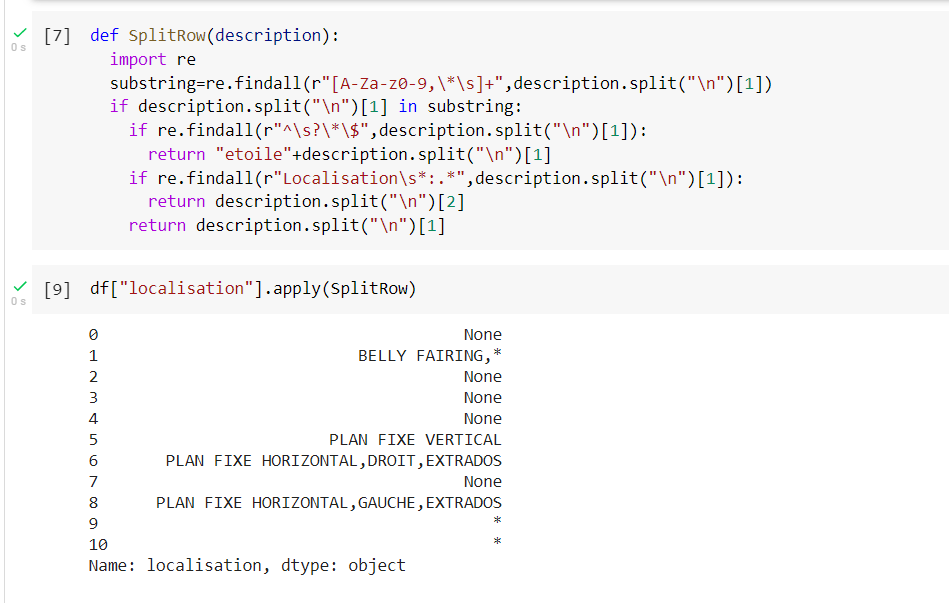
def SplitRow(description):
import re
substring=re.findall(r"[A-Za-z0-9,\*\s] ",description.split("\n")[1])
if description.split("\n")[1] in substring:
if re.findall(r"^\s?\*\$", description.split("\n")[1]):
return "etoile" description.split("\n")[1]
if re.findall(r"Localisation\s*:.*", description.split("\n")[1]):
return description.split("\n")[2]
return description.split("\n")[1]
但它不起作用,因為有很多行None:
uj5u.com熱心網友回復:
您可以使用
import re
df['temp'] = df['localisation'].str.replace(r'^.*\n', '', regex=True)
words = ['SECTION 11', 'CONE', 'BELLY', 'FIXED PLAN']
df['word'] = df['temp'].str.findall(fr'(?<!\w)(?:{"|".join([re.escape(w) for w in words])})(?!\w)').str.join(', ')
詳情:
.str.replace(r'^.*\n', '', regex=True)洗掉帶有換行符的第一行.str.findall(fr'(?<!\w)(?:{"|".join([re.escape(w) for w in words])})(?!\w)')提取列中所有出現的words整個單詞(由于(?<!\w)和(?!\w)明確的單詞邊界),temp同時轉義words..str.join(', ')在最后一個代碼行的末尾用于用逗號 空格連接找到的匹配串列。如果您編輯部件中的引數,您可以進一步調整加入匹配的內容.str.join()。
轉載請註明出處,本文鏈接:https://www.uj5u.com/net/344019.html