我有一列中有一些重復值的資料框。我想按該列分組并對其他列求和。資料框如下所示:
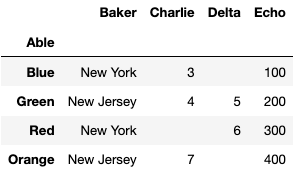
結果應按“貝克”分組,并對其他三列求和。我已經嘗試了各種不同的 groupby 和 pivot_table。他們回傳正確的兩行(紐約和新澤西),但他們只回傳“貝克”和最右邊一列“回聲”的總和。像這樣:

如何回傳所有列,最好不要在代碼中單獨列出它們?
uj5u.com熱心網友回復:
使用pivot_table:
>>> df.pivot_table(index='Baker', values=['Charlie', 'Delta', 'Echo'],
aggfunc='sum').reset_index()
Baker Charlie Delta Echo
0 New Jersey 11.0 5.0 600
1 New York 3.0 6.0 400
確保您的列C,d,E是數字,嘗試df.replace('', 0)或df.fillna(0)填補空白單元格。
uj5u.com熱心網友回復:
用 0 和 agg sum 替換空格。這將取決于最后三列是什么型別。我為您重新撰寫了 df,如果我弄錯了 dtypes 并編輯問題,請隨時進行編輯。論壇將為您提供指導。
資料框
df=pd.DataFrame({'Baker':[ 'New York', 'New Jersey', 'New York', 'New Jersey'], 'Charlie':[3,4,'',7], 'Delta':['',5,6,''],'Echo':[100,200,300,400]})
代碼
df.replace('',0).groupby('Baker').agg('sum')
輸出
Charlie Delta Echo
Baker
New Jersey 11 5 600
New York 3 6 400
轉載請註明出處,本文鏈接:https://www.uj5u.com/net/349855.html
標籤:Python 熊猫 数据框 通过...分组 数据透视表
上一篇:我需要檢查單詞串列中的單詞是否存在于字串串列中以及它出現的次數并回傳dict({word:total_occurrence})
下一篇:如何根據列值修改資料框