我目前正在學習和練習字串演算法。具體來說,我正在嘗試用一些修改替換基于KMP 的字串中的模式,它具有 O(N) 復雜度(我的實作如下)。
def replace_string(s, p, c):
"""
Replace pattern p in string s with c
:param s: initial string
:param p: pattern to replace
:param c: replacing string
"""
pref = [0] * len(p)
s_p = p '#' s
p_prev = 0
shift = 0
for i in range(1, len(s_p)):
k = p_prev
while k > 0 and s_p[i] != s_p[k]:
k = pref[k - 1]
if s_p[i] == s_p[k]:
k = 1
if i < len(p):
pref[i] = k
p_prev = k
if k == len(p):
s = s[:i - 2 * len(p) shift] c s[i - len(p) shift:]
shift = len(c) - k
return s
然后,我使用內置的 pythonstr.replace函式撰寫了相同的程式:
def replace_string_python(s, p, c):
return s.replace(p, c)
并比較了各種字串的性能,我將僅附上一個長度為 1e5 的字串的示例:
import time
if __name__ == '__main__':
initial_string = "a" * 100000
pattern = "a"
replace = "ab"
start = time.time()
res = replace_string(initial_string, pattern, replace)
print(time.time() - start)
輸出(我的實作):
total time: 1.1617710590362549
輸出(python 內置):
total time: 0.0015637874603271484
如您所見,通過 python 實作str.replace比 KMP 領先光年。所以我的問題是為什么?python C代碼使用什么演算法?
uj5u.com熱心網友回復:
雖然演算法可能是 O(N),但您的實作似乎不是線性的,至少在模式的多次重復方面不是線性的,因為
s = s[:i - 2 * len(p) shift] c s[i - len(p) shift:]
這是 O(N) 本身。因此,如果您的模式在字串中出現 N 次,則您的實作實際上是 O(N^2)。
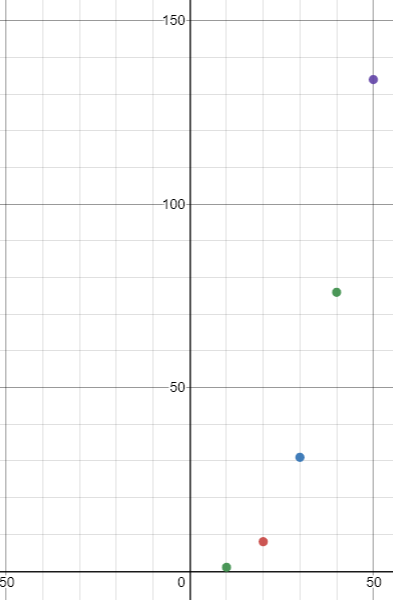
請參閱以下時間以了解演算法的縮放時間,這證實了二次形狀
LENGTH TIME
------------
100000 1s
200000 8s
300000 31s
400000 76s
500000 134s
轉載請註明出處,本文鏈接:https://www.uj5u.com/net/349902.html