我正在嘗試抓取外部資料以在網站上預填表單資料。目的是找到一個關鍵字,并回傳包含該關鍵字的元素的類名。我有不知道網站是否有關鍵字或關鍵字所在的標簽型別的限制。
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
chromeDriverPath = "./chromedriver"
chrome_options = webdriver.ChromeOptions()
driver = webdriver.Chrome(chromeDriverPath, options=options)
driver.get("https://www.scrapethissite.com/pages/")
#keywords to scrape for
listOfKeywords = ['ajax', 'click']
for keyword in listOfKeywords:
try:
foundKeyword = driver.find_element(By.XPATH, "//*[contains(text(), " keyword ")]")
print(foundKeyword.get_attribute("class"))
except:
pass
driver.close()
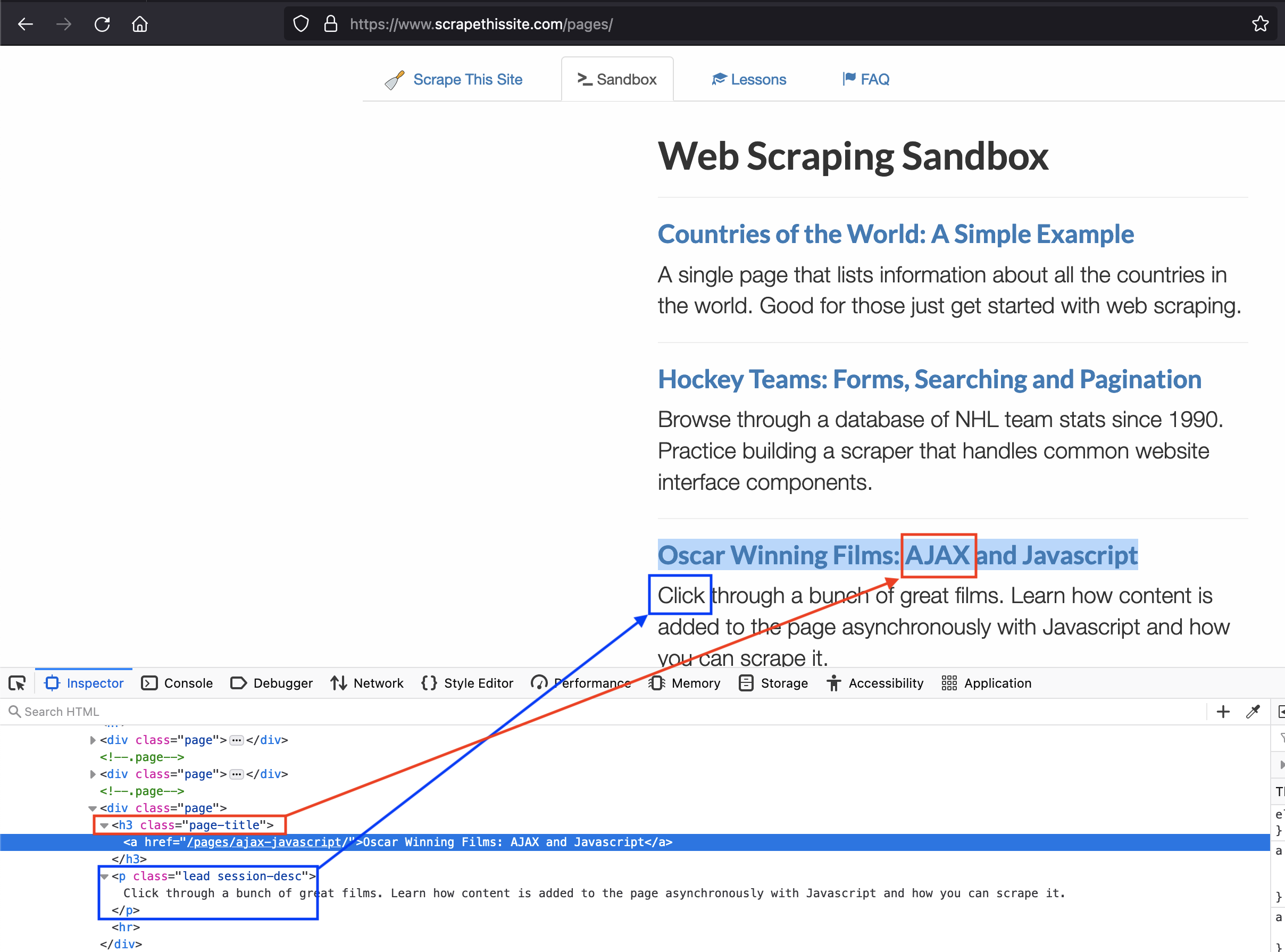
此示例回傳最高父級,而不是直接父級。為了詳細說明這個例子,列印 "" 因為它試圖回傳沒有 class 屬性的<html>標簽的 class 屬性。同樣,如果我更改代碼以搜索關鍵字<div>
foundKeyword = driver.find_element(By.XPATH, "//div[contains(text(), " keyword ")]")
這會為“ajax”和“click”列印“容器”,因為它div class='container'包裝了網站上的所有內容。
所以我想要上面例子的答案是,對于關鍵字'ajax',它應該列印'page-title'(直接父標簽的類)。同樣,對于“click”,我希望它列印“lead session-desc”。
下圖可能有助于形象化這一點
uj5u.com熱心網友回復:
根據注釋獲取 webelement 的父元素,可以parent在 xpath 中使用關鍵字。
<p>是文本節點。該元素的父標簽是<div class='page'>
嘗試如下:
driver.get("https://www.scrapethissite.com/pages/")
listOfKeywords = ['AJAX', 'Click']
for keyword in listOfKeywords:
try:
element = driver.find_element_by_xpath("//*[contains(text(),'{}')]".format(keyword))
parent = element.find_element_by_xpath("./parent::*").get_attribute("class")
tag_class = element.get_attribute("class")
print(f"{keyword} : Parent tag class - {parent}, tag class-name - {tag_class}")
except:
print("Keyword not found")
AJAX : Parent tag class - page-title, tag class-name -
Click : Parent tag class - page, tag class-name - lead session-desc
uj5u.com熱心網友回復:
有兩種不同的情況,如下所示:
- 在第一種情況下,您可以選擇在標題中查找
<h3>具有class父標簽的關鍵字page-title - 在第二種情況下,您可以在
<p>標簽中查找<h3>具有class 同級標簽的關鍵字page-title。
對于第一個查找諸如 關鍵字的用例AJAX,您可以使用以下定位器策略:
driver.get("https://www.scrapethissite.com/pages/")
listOfKeywords = ['AJAX', 'Ajax']
for keyword in listOfKeywords:
try:
print(WebDriverWait(driver, 5).until(EC.visibility_of_element_located((By.XPATH, "//a[contains(., '{}')]//parent::h3[1]".format(keyword)))).get_attribute("class"))
except:
pass
driver.quit()
對于查找諸如 關鍵字的第二個用例Click,您可以使用以下定位器策略:
driver.get("https://www.scrapethissite.com/pages/")
listOfKeywords = ['Click', 'click']
for keyword in listOfKeywords:
try:
print(WebDriverWait(driver, 5).until(EC.visibility_of_element_located((By.XPATH, "//p[contains(., '{}')]//preceding::h3[1]".format(keyword)))).get_attribute("class"))
except:
pass
driver.quit()
在這兩種情況下,控制臺輸出將是:
page-title
轉載請註明出處,本文鏈接:https://www.uj5u.com/net/355798.html
上一篇:如何在選擇DataGridCell時更改模板項的背景
下一篇:硒從元素中提取某些值